Game Launches Should Be Exciting for Your Players, Not for Your LiveOps Team
By Liz Fong-Jones | Last modified on November 18, 2021This blog was co-authored by Amy Davis.
The moment of launching something new at a game studio (titles, experiences, features, subscriptions) is a blockbuster moment that hangs in the balance. The architecture—distributed and complex, designed by a multitude of teams, to be played across a variety of devices in every corner of the world—is about to meet a frenzy of audience anticipation, along with the sky-high expectations of players, executives, and investors.
When I was on the LiveOps team at Three Rings Design, we found that first impressions especially mattered to our players—and that’s still true today. All the hard work that our LiveOps team put in meant nothing if players experienced widespread glitches or, worse, couldn't even connect to servers for hours on launch day. How could we invest early in ensuring that things will work correctly rather than scrambling at the last minute or having to extend downtime over and over and over?
No matter how much QA was conducted or how rigorous the playtesting was or how big our beta was, we didn’t really know how every piece of in-studio, platform, partner, and third-party code would behave for our servers until game clients were hitting it at scale. And if we did it well, nobody would notice our efforts.
Success means a boring, uneventful launch for us as a LiveOps team. A boring launch doesn’t mean that nothing goes wrong—but when something does act up, it means we are able to quickly identify, manage, and resolve it.
So how can we have confidence in our services and in our ability to debug any last-minute problems that might arise? The answer is continuous delivery practices, including real-time feedback on builds, observability, and feature flagging.
Get the feature right the first time with fast feedback
Yes, assets are big and annoying. Integrating five other teams' work takes time. But why is it that we don't know whether our feature works until it's gone through the hours-long integration test pipeline alongside dozens of other commits?
At smaller studios, incremental, speedy local builds are easy to achieve. But as scope and dependencies sprawl, the build gets slower and slower. It becomes hard to even know what is slowing down the build, let alone optimize it.
We used tracing (more on tracing below) as a really easy way to start looking at specific builds. We found a trace from an early morning build that took 37 minutes. Where is the time being spent? Is 37 minutes good or bad? If we want quicker builds, how do we know where to invest in order to maximize the amount of time we can save—e.g., buy more hardware, find the root cause of a persistent bug, focus on finding and unburying an error that causes a test to be re-run after reboot?
Trace spans help us ask more and better questions that set us on a course of action to remove wasted effort. We can get early feedback out of builds, and the faster builds improve our developer feedback loop.
Observability limits what can go wrong
Too often, we focus on trying to enumerate every possible failure case through unit tests, manual QA testing, and even mass player tests. What if, instead of enumerating possible failures, we could narrow down the amount of time it takes to debug anything that goes wrong (and it will). What if, instead of taking guesses in the dark because we forgot to add a CloudWatch alarm or a Datadog metric, we can have visibility into every component and service call in the life cycle of client requests and server-side responses?
To see how things are working, all the way down to the client side, we need observability. Observability isn't logging, metrics, and traces; instead, it's a broader capability that encapsulates our ability to answer questions that we didn't know that we wanted to ask. In fact, logging can lead us astray by producing too much data to sensibly analyze and look at, and metrics can lead us astray with red herrings from different unrelated signals wobbling or lack of adequate precision to understand categories of failing traffic.
“The most painful thing I saw when I first joined CCP Games, the team would say, ‘We released today, and it didn’t explode.’ I would ask, ‘Okay, but how is everything performing?’ And the reply was, ‘Well, we won’t know until tomorrow.’ My response was, ‘I’m sorry. What?!’
Now, Honeycomb helps us with the forensics, when we want to know real time what’s happening with the release and be able to see how everything is performing.”
- Nick Herring, Technical Director of Infrastructure for EVE Online
By having real-time observability, we're able to understand production—without having to manually comb through raw server logs and uploaded client crashes.
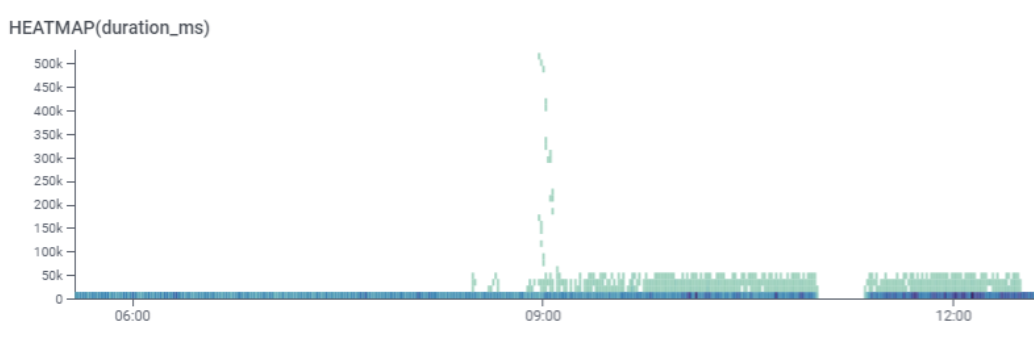
Heatmaps expose the lie of percentiles
Let's suppose that our 99th percentile latency says that logins are taking 1,500ms. Great, right? Well … that percentile means the last 1% of users might be having unbounded latency up to the timeout and are having a frustrating experience! Instead, it's better to visualize the spectrum of possible request latencies and time buckets as a picture rather than a set of lines.
Heatmaps enable us to spot patterns—not just slowness, but perhaps a change in the overall shape of the data, including bursts of fast failures, stampeding herds of retries gone amok, and more.
Your launch can become even more boring if you have tooling on your side that helps you not just visualize heatmaps, but act on them by telling you what's different about a pattern that you'd like to drill into—whether it be client build id, locale, graphical settings, or more. There's no more guessing or plotting 100 things at random any more, just a laser focus on the fields and values that matter.
 Tracing helps us dig into individual request performance
Tracing helps us dig into individual request performance
Sometimes the aggregate picture of what an individual endpoint is doing is insufficient to help us understand what's really happening. Is it blocking on the authentication backend? Is there a bottleneck on the item database? Does the matchmaking pool have enough players in it at that Elo?
It's essential for us to be able to debug individual examples of requests that are slow or failing in order to understand where and why they are failing. Traces provide causality and allow us to explain that a request was slow because it called the database 50 times in serial instead of making one bulk lookup or using the cache. The waterfall is a much more powerful tool than wiggling lines.
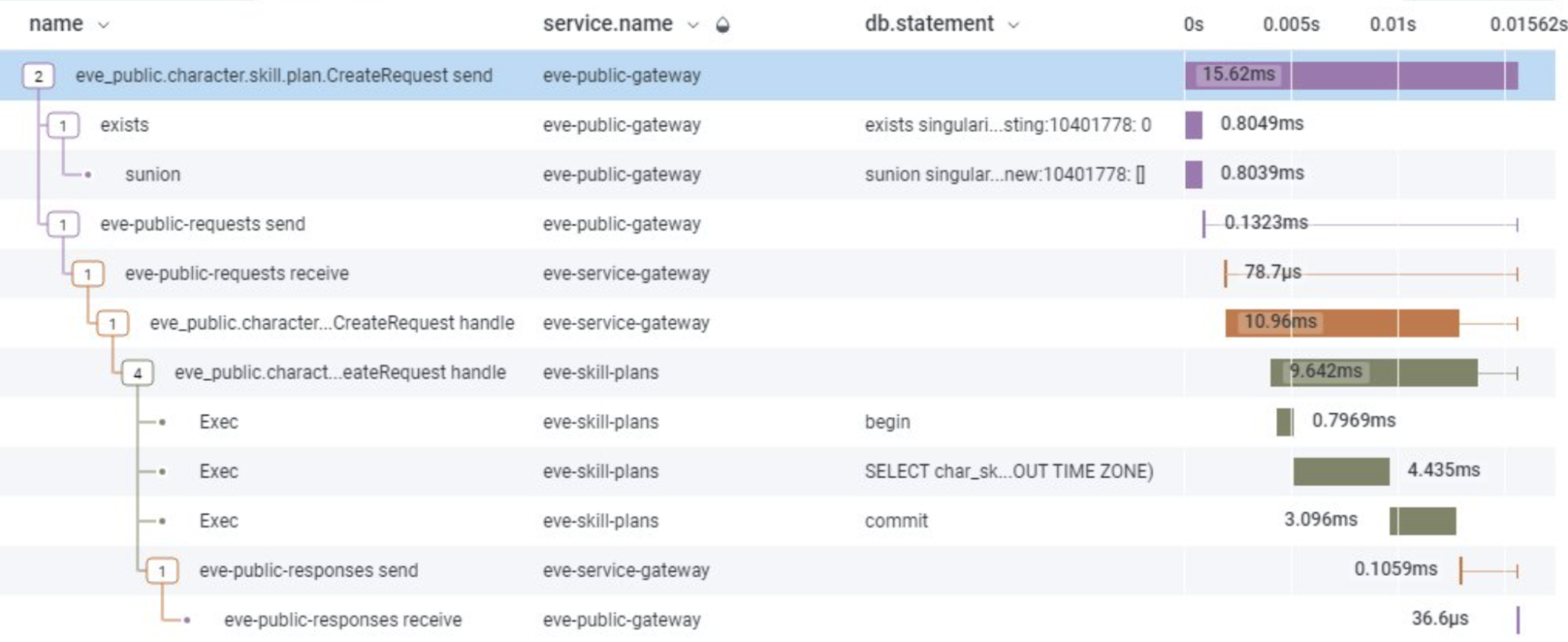
If a service doesn’t perform as anticipated you can see it and resolve it, and keep your players playing. Which is what you want … and more importantly … what they want.
Feature flags allow us to contain blast radius
Instead of turning a feature on for 100% of users, use a rolling launch with LaunchDarkly. That way if the feature does cause slowness or crashes, it'll only be for 1% of users, and you'll immediately be able to pause or reverse the rollout for a few minutes while you sort out the issue. Because you implemented good observability, even the gnarliest of issues can be found within half an hour. And you optimized your build pipeline, right? Which means you can get that hotfix out within an hour and resume the rollout. And nobody will notice. Your players will be delighted and executives will give everyone bonuses!
Request-level granularity lets us catch bad actors
Launches should be an exciting party for your players. But there's always a party pooper who's looking to bot, spam, or otherwise disrupt player experience. Server logs are a cumbersome way of catching them. Grepping over unstructured logs is so, so slow, especially when the logs are scattered across many servers or when we need to pay an arm and a leg to centrally index them. Wouldn't it be better to highlight anomalies in API usage patterns, traffic sources, and session lengths, and pick out the cardinality of individual client IDs to figure out who to banhammer within minutes?
What does it take to know if there is value using observability for our launch?
To know, you simply begin.
And, like with everything else, over time you will fine-tune.
You will need instrumentation. OpenTelemetry (OTel) is your best bet. Depending on your familiarity, the engineering work to put instrumentation in place is from about two days to about a week. By using OTel, this work can be leveraged regardless of tool choice.
Interested in learning more about how we can help make your next launch just another day at work? Book some time to meet with Liz and Amy for expert advice and access to enterprise services and features.
Meet with Liz and Amy
Related Posts
Transforming Financial Services with Modern Observability: Moov's Story
As a new company poised to transform the financial services industry with its modern money movement platform, Moov wanted an equally modern observability platform as...
What Is Application Performance Monitoring?
Application performance monitoring, also known as APM, represents the difference between code and running software. You need the measurements in order to manage performance....
Where Does Honeycomb Fit in the Software Development Lifecycle?
The software development lifecycle (SDLC) is always drawn as a circle. In many places I’ve worked, there’s no discernable connection between “5. Operate” and “1....