Never Alone On Call
By Deirdre Mahon | Last modified on August 29, 2019Does your organization have an on-call rotation? Several members of the Honeycomb engineering team recently hosted a live webcast about why they never feel alone when on-call at Honeycomb.
Wait, that’s someone else’s job
Are you working on a team with a culture where functional roles are distinct and ‘hard-wired’ into everyday practices? Perhaps your org has distinct teams responsible for writing code, another team responsible for test and validation, others who take care of the build release pipeline, and perhaps an entirely separate team that focuses on system operations, triaging when things go wrong or when specific services need attention. The latest DORA report, Accelerate “State of DevOps 2019” findings show that when an organizational culture that optimizes for information flow, trust, innovation, and risk-sharing, it is predictive of high Software Delivery and Operational (SDO) performance. The report also cites that culture is a key success factor in successful and scalable technology efforts, citing the Davis and Daniels Effective DevOps book.
At Honeycomb, we have always had a culture of everyone on call, with a two week rotation where for the first week you act as a secondary resource and during the second week, you take the primary role. There's a hand off meeting at the end of each week, passing on key activities and learnings documented for all.
In the old days before everyone was on call, Honeycomb engineers remember, "back then ops would complain that dev didn’t instrument the code adequately" or that "dev doesn’t understand what its like to be woken up and have to address what may appear to be a severe issue and find out that it could wait until standard office hours". Back in the old days there was a clear division of labor and ops was responsible for production issues and dev’s wrote code.
First-hand experience builds critical knowledge
Now, dev teams learn how ops works. Check out the Honeycomb Learn webcast episode and hear first hand from Honeycomb engineers on the on-call front lines. Dev builds the product, runs it, and with the inevitable challenges of running new code in production, everyone learns first-hand what those challenges look like, how they are handled, and how to best avoid similar things happening again. With everyone on the team involved, problems are identified more quickly and finding a fix happens much faster. Any tickets that arise are handled by the on-call team and they don’t grow stale waiting for the next on call team to get up to speed.
As an engineer on call, you start to change how you instrument your code. Being in a support role, you see how code behaves in production first hand. Your workload can vary depending on what’s happening during your rotation. Perhaps the team just pushed a significant release with changes that impact all users or maybe the business just on-boarded a large number of new users that happen to be less sophisticated with the app. The on-call team prioritizes what to spend their time on, and guidance comes in the form of:
- Alerts via Slack or Pagerduty to inform you exactly what’s happening so you hone-in on any unusual activity or system behavior. After further inspection, you determine what level of resources and time it needs, with an on-call team to lean on if you can’t resolve on your own.
- User generated errors also need attention which may be seen in the form of a Javascript error and there’s always the ongoing long tail of edge cases and unexpected user behaviors.
- Bugs and special customer requests that are waiting to be co-worked or pushed to engineers that are not on that particular rotation.
It starts with an alert
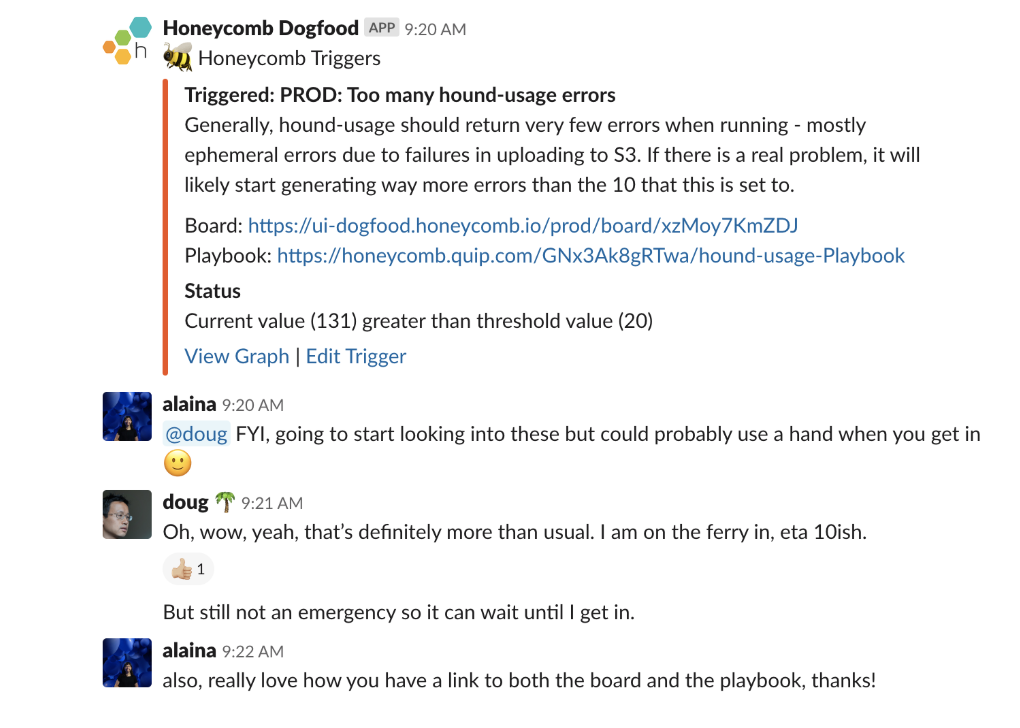
On-call is never dull at Honeycomb. Our production environment notifies on-call team-members of issues with details via a Slack alert, a link to a potentially useful result set. The on-call engineer can immediately drill-in to see the query and the investigation begins. Honeycomb is designed for team collaboration, giving everyone full access to all queries previously run. With this ability to search for clues from past investigations, everyone is looking at the same level of detail, learning from others why certain queries were constructed and run.
Observability drives a closed loop cycle
The cycle of writing, testing, validating and deploying has by its very nature a built-in closed loop and if you don’t engage the right team members at each software development stage, you will struggle to pass on critical information and knowledge. Additionally, if you don’t share the same analytical tooling along the stages in the cycle, you will not have the same level of understanding about is occurring in production at that very moment. On-call teams require a single version of the truth and it must be real-time and provide insights to what the user is experiencing with the service.

Everyone benefits when the organization supports a team culture
In the latest Dora State of DevOps report cited earlier, page 42 talks about having structures and processes in place to support a culture of a loosely-coupled architecture when it comes to defined roles and functions. The findings revalidated the positive impact of this: A loosely coupled architecture is when delivery teams can independently test, deploy, and change their systems on demand without depending on other teams for additional support, services, resources, or approvals, and with less back-and forth communication. This allows teams to quickly deliver value, but it requires orchestration at a higher level. At Honeycomb, the on-call playbook is a centrally shared document that is modified and updated as the service changes and grows.
The benefits far outweigh the commitment
The Honeycomb team recognizes that it may seem revolutionary to have everyone join the on-call rotation, but the benefits far outweigh the commitment.
“At first it was scary," shared Alyson "because I was new to Honeycomb and I didn’t want to fail or not be able to solve any issue but when I realized that I was never alone, I was more comfortable”.
Stress levels reduce and there is no panic because Honeycomb supports a blameless culture. Everyone on the team learns -- back-end engineers learn from front end engineers — which broadens their understanding of the entire environment.
New team-members don’t join on-call on day one. There is recognition that the on-call team can’t fix everything and certainly not single-handedly. Best practices include a post mortem analysis and everyone learns from that sharing in addition to a detailed blog post publicly shared with Honeycomb’s customers, an invaluable support mechanism. No-one ever feels shame or blame if they can’t resolve something, and the culture of jumping in to help a new team-mate is understood so that everyone contributes over time.
Want to watch the live recording of this webcast and get the rest of the story? Check out our Webcasts page for more great sessions with members of the Honeycomb team.
Related Posts
What Is Application Performance Monitoring?
Application performance monitoring, also known as APM, represents the difference between code and running software. You need the measurements in order to manage performance....
Where Does Honeycomb Fit in the Software Development Lifecycle?
The software development lifecycle (SDLC) is always drawn as a circle. In many places I’ve worked, there’s no discernable connection between “5. Operate” and “1....
How We Leveraged the Honeycomb Network Agent for Kubernetes to Remediate Our IMDS Security Finding
Picture this: It’s 2 p.m. and you’re sipping on coffee, happily chugging away at your daily routine work. The security team shoots you a message...