Toward a Maturity Model for Observability
By Rachel Perkins | Last modified on June 11, 2019Access to observability is becoming critical to organizations shipping software, running modern infrastructures in production, and to understanding how users are experiencing their service. To achieve success in delivering a complex service, it's no longer optional to instrument for real visibility and ease of troubleshooting, to optimize alerting to enable a focused response, to do what is needed to drive toward real understanding and ownership of the code we deliver.
If you're building an observability practice, you need guideposts and an understanding of how different aspects of the practice can affect your business. You need to consider what to do first, what to do next, and why. The goals and practices of observability are closely inter-related, and can be iterated on via the practice of Observability-Driven Development. Developers get happier and more productive when code is cleaner and easier to maintain. Clean, easier-to-maintain code results in a more stable product and a more pleasant experience for folks oncall and ultimately, for your customers. Where should you start?
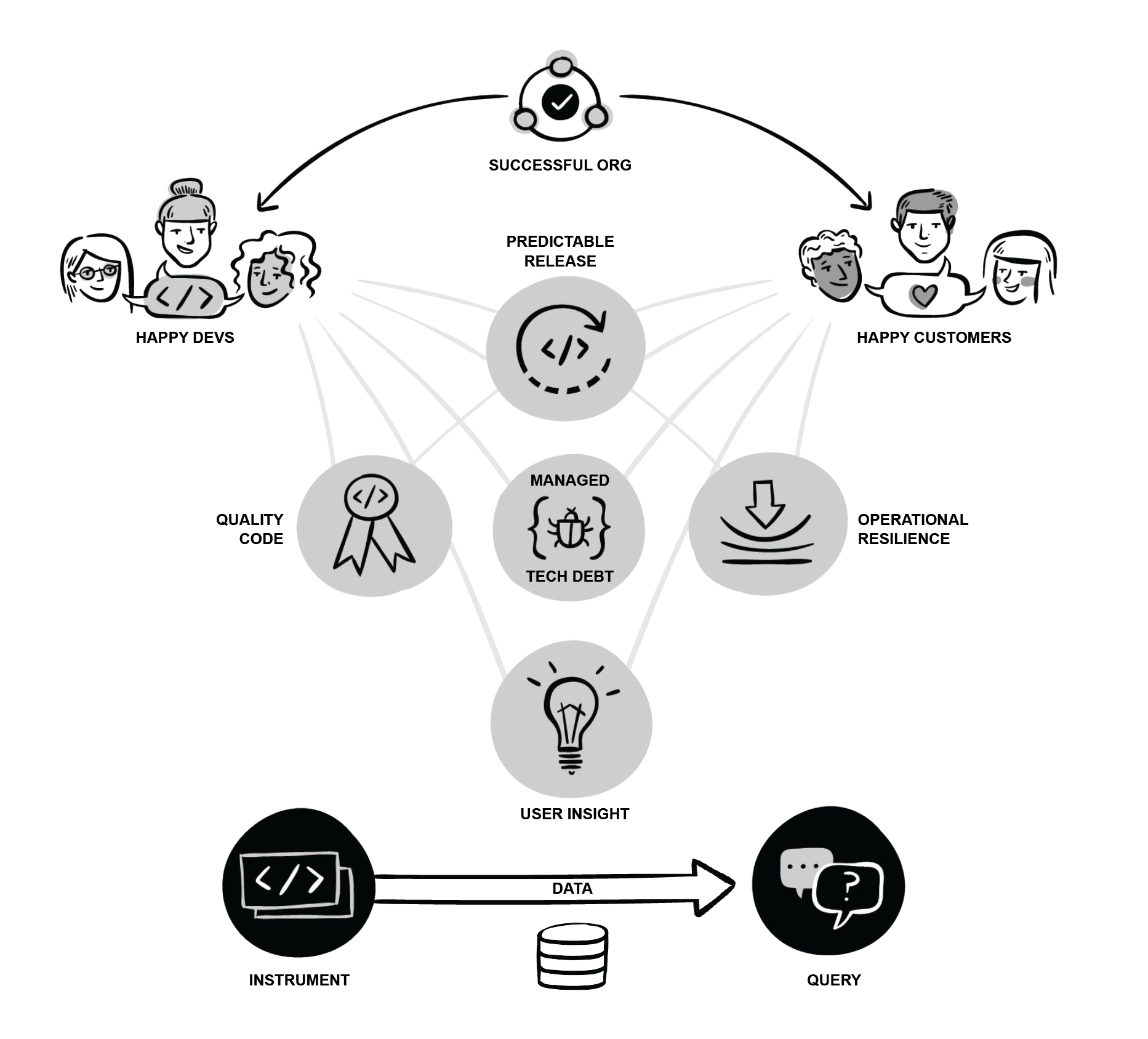
The framework we describe in the Framework for an Observability Model is a starting point. With it, we aim to give organizations the structure and tools to begin asking questions of themselves, and the context to interpret and describe their own situation--both where they are now, and where they could be.
Download the Framework for an Observability Model and join our discussion (find an HTML version here). We'll be hosting a roundtable meetup at Velocity this week looking to get your feedback, and will be hosting more, similar discussions through the summer as we develop a suitably rigorous approach.
Ready to take the next step toward growing your observability practice? Sign up for a free trial!
Related Posts
Introducing Relational Fields
Expanded fields allow you to more easily find interesting traces and learn about the spans within them, saving time for debugging and enabling more curiosity...
Real User Monitoring With a Splash of OpenTelemetry
You're probably familiar with the concept of real user monitoring (RUM) and how it's used to monitor websites or mobile applications. If not, here's the...
Transforming to an Engineering Culture of Curiosity With a Modern Observability 2.0 Solution
Relying on their traditional observability 1.0 tool, Pax8 faced hurdles in fostering a culture of ownership and curiosity due to user-based pricing limitations and an...