A Better Environment for Observability, at Your Service
We’ve made some big changes under the hood at Honeycomb to give you better control over how you put your apps data to work—we’ve expanded our core data model with formal Environments and Services!…

By: Nick Rycar
We’ve made some big changes under the hood at Honeycomb to give you better control over how you put your apps data to work—we’ve expanded our core data model with formal Environments and Services! In short, the best observability (o11y) platform in town just got better!
Before we dig in, an important note. Existing Honeycomb teams are not impacted by this update.
If you’re already a Honeycomb user, congratulations! Your team is now a Honeycomb Classicteam. The docs will give you all the details, but the short version is that you don’t need to take any action in response to today’s release. Everything will continue to work the same way as ever.
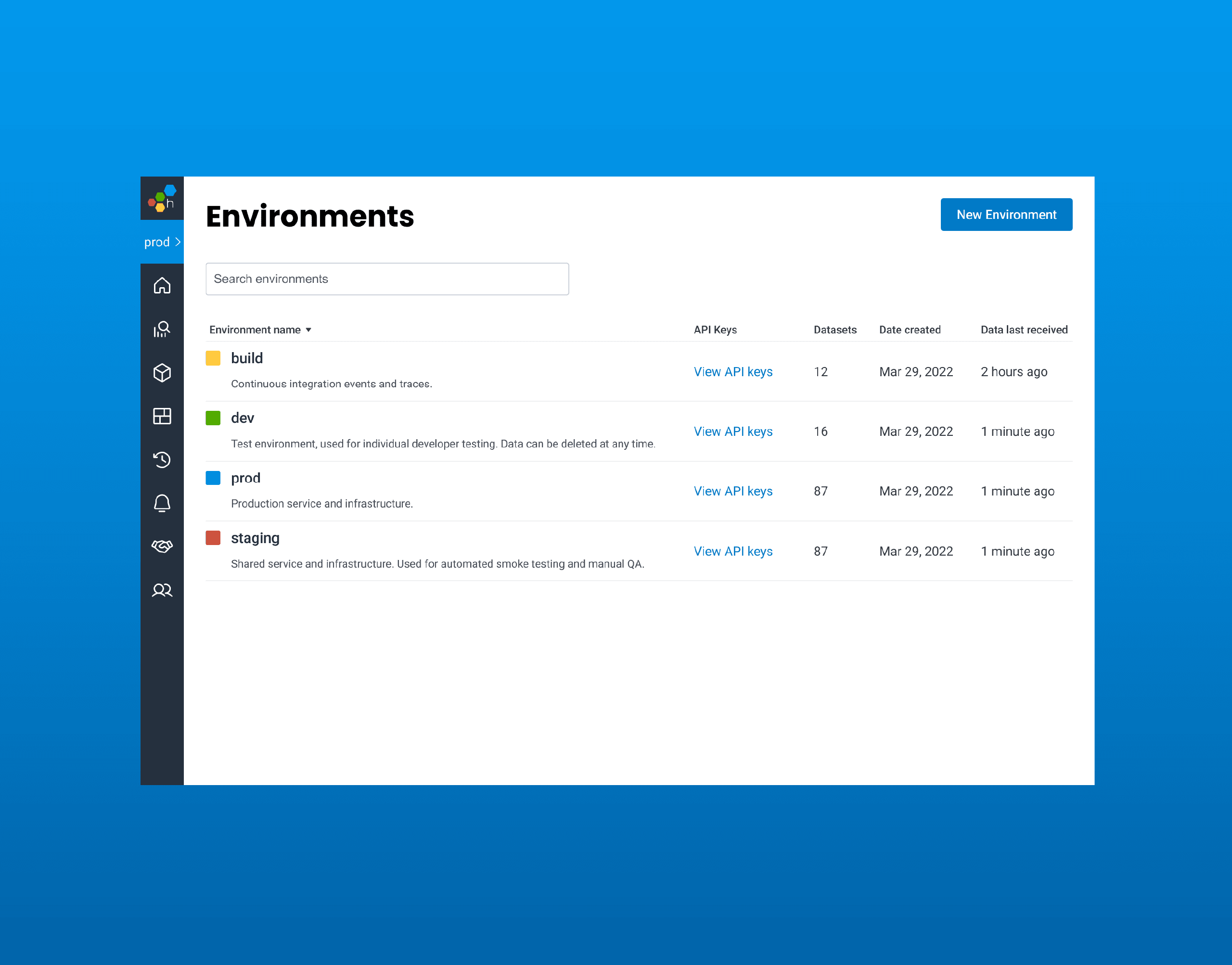
What’s New: Environments and Services
Teams created on or after March 29, 2022 will gain access to Honeycomb’s expanded data model with Environments and Services. An Environment represents a named group of your datasets. A Service represents one or more programs sharing an executable.
Design implications: Service Datasets
Historically, when sending data to Honeycomb, you had two high-level strategies when splitting your datasets:
- Separate by Environment. With all of services and data, you can easily see and query distributed traces in Honeycomb. However, as a team scales, it becomes hard to find information in a single dataset without granular segmentation.
- Separate by Service. Services are split by datasets, which leverages the existing segmentation via datasets. However, there were additional limits due to the inability to query across datasets.
With this update, you no longer have to choose! Honeycomb will create separate Service Datasets directly from our tracing libraries. You get the best of both worlds with service-specific context for dataset operations, but visibility into user experiences across services within an environment.
In addition to the new Service Datasets, this release includes General Datasets. Any workloads that don’t fit neatly into the more rigid, tracing structure of Service Datasets become General Datasets instead. These work more or less exactly like the datasets you’re used to in Honeycomb Classic, making the new bells and whistles truly opt-in.
New product updates
With these new constructs, Honeycomb functions differently compared to the Honeycomb Classic experience.
API keys now scope to a specific environment
API keys originally were scoped to a team, which was inflexible across teams in that API keys were harder to manage, organize, and scale across larger complex teams with more nuanced permissions needs. With environment-scoped API keys, teams can more easily share keys and set permissions for different services that send data to Honeycomb. Worry less about impacting production datasets with different keys.
Queries can run across multiple Services and Datasets in an Environment
There are times when it makes sense to focus queries on a specific service that your team owns or that you are triaging. Other times, it may be useful to understand what is happening across the entire environment for multiple services. Teams can scope their queries appropriately and see relevant information without needing additional filters.
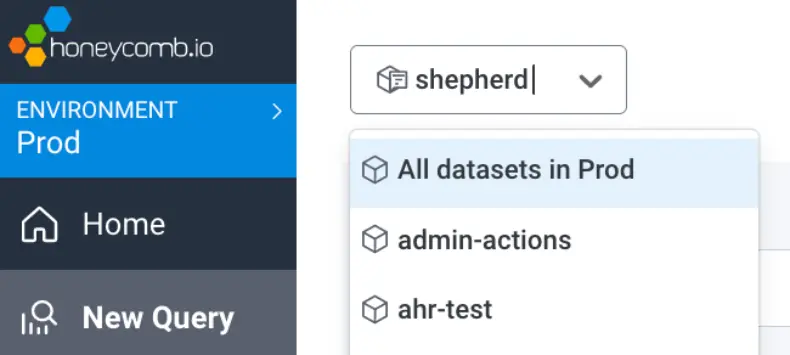
Markers can apply to a moment in time for either an Environment or a Dataset
Markers are a great way to note events in your systems. These may be relevant for a specific service or is relevant to an entire environment. You can now create a marker to a point in time for your environment or continue to create them for a dataset. When running queries in Honeycomb, you can view either types of markers in your queries with our Filter Markers option.
Improved organization and segmentation with Service Datasets
Honeycomb auto-creates datasets from traces. It becomes easier to see more for a specific service or an entire environment across Boards, Service Level Objectives (SLOs), Triggers, and Queries. As teams add services to Honeycomb, the structured service views minimizes the impact of adding new teams or applications.
As an added level of protection, there is currently a limit of 100 datasets per environment. If you find that you need more, feel free to contact our support team to raise these limits.
Next milestone: Migrations
What if you’re a Honeycomb Classic user and want access to the new capabilities? We’ve got you covered but want to make sure the experience is as seamless as possible. We’re working to onboard some early adopters to smooth out any rough edges before a broader migration guide is released. We’ll keep you in the know as updates are available, but if you want to get hands-on now, you can create a new team to check things out at any time.
Learn more
Be sure to check out the Honeycomb Classic docs page for more detail on what’s new, as well as guidance on preparing for migrations.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.