What Is Honeycomb’s ROI? Forrester’s Study on the Benefits of Observability
Register for the webinar and download the full study to see and apply Forrester’s financial model to determine the observability ROI for your organization. Many teams want to adopt observability and Honeycomb—but run into…

By: Evelyn Chea

Register for the webinar and download the full study to see and apply Forrester’s financial model to determine the observability ROI for your organization.
Many teams want to adopt observability and Honeycomb—but run into budget roadblocks because budget holders may not clearly understand the quantifiable benefits to their end users, their teams, and the bottom line.
That’s why we commissioned Forrester Consulting to conduct an independent study of the quantified benefits and cost savings of deploying Honeycomb for observability. Forrester Consulting’s Total Economic Impact™ (TEI) framework identifies the cost, benefits, flexibility, and risk factors that can affect an investment decision. The customers interviewed and researched in the process represent the high tech, financial services, and fintech industries.
The customer interviews and Forrester’s financial analysis found that a composite organization choosing Honeycomb would see numerous quantified benefits, including:
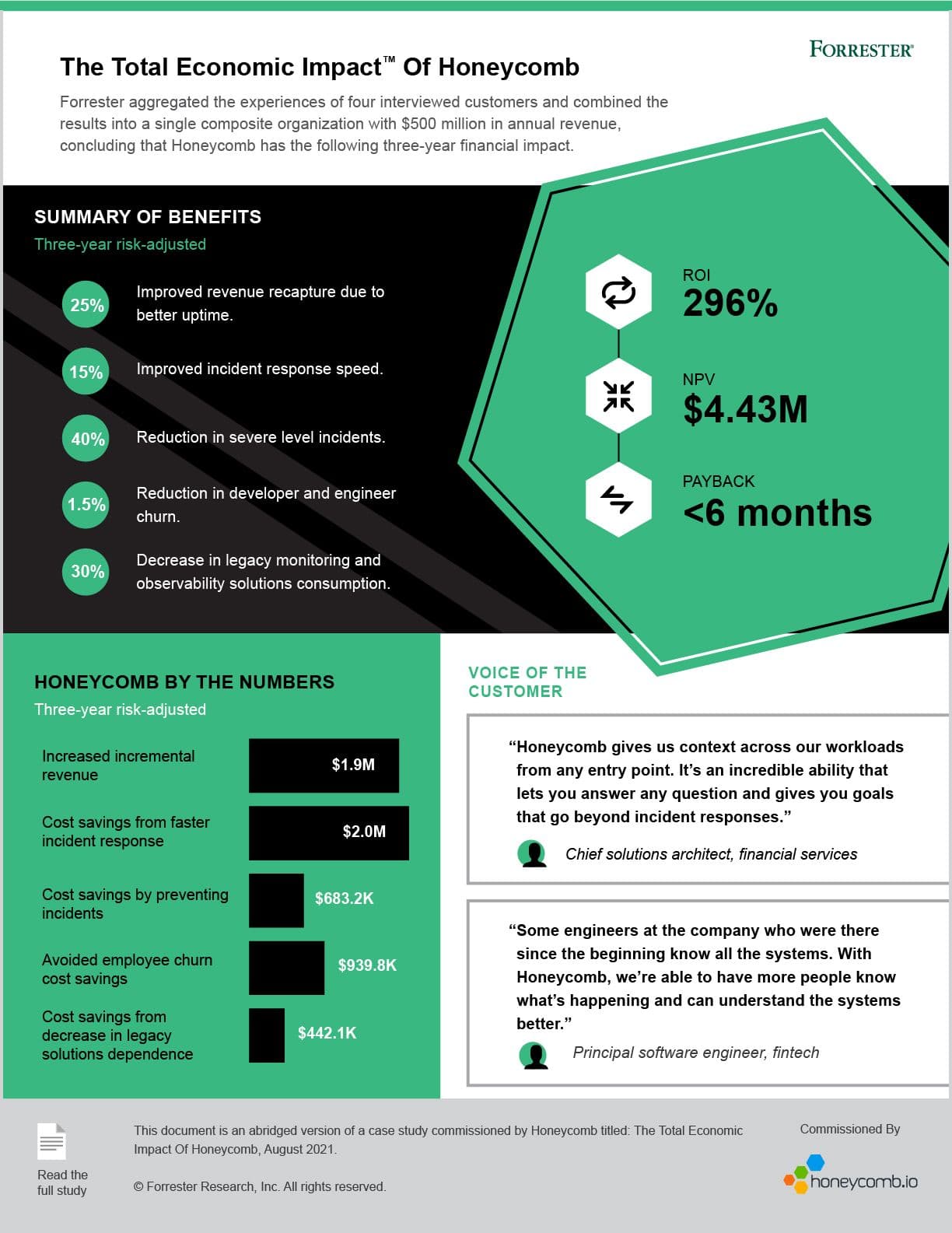
- A three-year ROI of 296%
- Cost savings of $2.68 million due to faster incident response and incident prevention
- A total of $4.43 million net present value (NPV) over three years when also factoring in incremental revenue due to better uptime and performance, and cost savings from lowering developer turnover, and reducing legacy monitoring costs
Customers also shared unquantified benefits such as faster release cycles, faster innovation, improvements in the customer experience, and avoidance of vendor lock in due to open instrumentation.
How can you achieve the results detailed in the study? With Honeycomb, engineering teams quickly query and analyze high-cardinality data in real time, and slice and dice information any way they want. When coupled with Honeycomb’s super-fast querying capabilities and BubbleUp feature, teams can ask any question and quickly get to the cause of any production issues, no matter how deeply buried.
The challenges with existing monitoring, metrics, and logging solutions
The customers interviewed shared the challenges they faced with their legacy solutions, including metrics and logs, which didn’t provide the real-time querying and high-cardinality analytics they needed and made it difficult to find causes of incidents in production.
Metrics tools allow you to aggregate performance across a small number of labels. For every triggered alert, you may be able to see which service is experiencing a problem, but you won’t be able to dig into underlying data to understand why it’s happening and which users are affected. Additionally, the metrics-based approach of monitoring relies on having knowledge about past failures because teams will set alerts based on past failures.
Some teams then say “Okay, but I have logs that could help.” But as Honeycomb CTO Charity Majors wrote, “Logs are at their best when you know exactly what to look for, then you can go find it.” This involves manually digging through logs and also brings up the question: What if you don’t know what failed exactly and don’t know what to look for?
Modern distributed systems architectures fail in novel ways that no one is able to predict and that no one has experienced before. Without the ability to slice and dice high-cardinality data, you can’t see where in the service the problem is happening. And that’s why the ROI of observability is so high.
The bottom line on observability with Honeycomb
At its core, observability is about unknown-unknowns. When your applications and/or systems fail in unexpected ways, can you ask a bunch of questions while investigating to arrive at answers? In other words, if you can’t predict all the questions you’ll need to ask in advance or if you don’t know what you’re looking for, then observability can help.
“Honeycomb gives us context across our workloads from any entrypoint,” shared one customer, a chief solutions architect at a financial services firm. “It’s an incredible ability that lets you answer any question and gives you goals that go beyond incident responses.”
According to the customer interviews and financial analysis conducted by Forrester, this impacts the bottom line in 5 important ways:
- Cost savings from lower dependency on legacy solutions. Organizations that have implemented Honeycomb decrease other legacy monitoring solutions used, resulting in licensing, infrastructure, and operational savings. This is especially true as legacy vendor pricing often penalizes custom instrumentation vs. Honeycomb, where our pricing encourages generating wide events with rich context.
- Higher incremental revenue. Honeycomb helps teams improve uptime and performance, leading to increased incremental revenue directly as a result of improving code quality.
- Cost savings from faster incident response. The study finds Honeycomb significantly reducing labor costs due to faster mean-time-to-detect (MTTD) and mean-time-to-resolve (MTTR), improved query response times, the ability to find bottlenecks quicker, reduction of time spent on call, and avoided roll backs.
- Cost savings from avoided incidents. Honeycomb enables developers to find causes of problems before they become critical and long-lasting, which helps prevent incidents. One customer in the study eliminated 15% of overall incidents using and reduced severe-level incidents by 40%
- Cost savings from decreased employee churn. Forrester found that implementing Honeycomb results in improved job satisfaction and decrease in developer burnout, alert and on-call fatigue, and turnover.
The big picture: Honeycomb’s total economic impact
Forrester Consulting’s analysis reveals that all interviewed customers have improved their ability to manage and prevent critical incidents because they used Honeycomb’s unique features like high-cardinality data, fast querying capabilities, and BubbleUp to identify sources of issues and avoid problems before they become critical.
The interviewed customers also reported that Honeycomb has been essential in reducing revenue leakage due to production outages by enhancing external production system uptime, which in turn optimizes customer experiences, improves services, and drives better business outcomes—ultimately resulting in an ROI of 296% and a net present value of $4.43 million over three years, and a break-even point less than 6 months after implementing Honeycomb.
Your mileage may vary. Register for the webinar and download the full study to see and apply Forrester’s financial model to determine the observability ROI for your organization.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.