Data Strategy for SREs and Observability Teams
The idea that telemetry data needs to be managed, or needs a strategy, draws a lot of inspiration from the data world (as in, BI and Data Engineering). Your company most likely has a data team that manages the data warehouse(s), data pipelines, data sources, and reporting tools. These teams are also constantly balancing costs with their user and stakeholder needs, usability, data retention, granularity, etc. Sound familiar? That’s because if you’re working on observability data, these teams are at least several years ahead of you in addressing these tradeoffs and considerations—and can teach us quite a lot.



The Cost Crisis in Metrics Tooling
Learn MoreIn Honeycomb’s Customer Architects team, we work with the full spectrum of team, scope, and budget sizes. “The data isn’t valuable enough” is something we’re always dismayed to hear, but we hear it often enough. The thing is, as much as we want it to not be true, no product or tool can magically maximize the value of your telemetry data—at least not without gobs of human input, oversight, and review.
The idea that telemetry data needs to be managed, or needs a strategy, draws a lot of inspiration from the data world (as in, BI and Data Engineering). Your company most likely has a data team that manages the data warehouse(s), data pipelines, data sources, and reporting tools. These teams are also constantly balancing costs with their user and stakeholder needs, usability, data retention, granularity, etc. Sound familiar? That’s because if you’re working on observability data, these teams are at least several years ahead of you in addressing these tradeoffs and considerations—and can teach us quite a lot.
Let’s flatter our data friends, borrow some of their terminology, and learn as much from them as possible by outlining the principles and categories of an observability data strategy.
The challenges
Let’s say you’re on an SRE or observability team at your company, in charge of tooling and budgets. Do these challenges sound familiar?
- Unpredictable observability tooling costs
- Constant tug-of-war between the need for high-granularity data, long data retention periods, and the physical practicalities of storing large amounts of data while maintaining query performance and budgets
- Lack of effective controls to prevent the leaking of PII and secrets in telemetry data
- Timeline gaps and/or missing spans and services from tracing data, leading to an inability to correlate between signals
- Excessive volume of repetitive, low-value data
- Lack of technical and business context, making it difficult to tie telemetry to specific users’ actions or underlying infrastructure
- Disconnected tools, data sources, and telemetry types, making troubleshooting slow and difficult
If these sound familiar, fear not: you’ve come to the right place. In this article, we’ll borrow terminology and techniques from the data world to help you get this data under control.
New to Honeycomb? Get your free account today.
First principles
Stepping back from all of the specific tools, technologies, and vendors, the following should be true:
- Your observability data should be complete, usable, and trustable.
- You shouldn’t send more than you need—and never sensitive information.
Let’s break this down and define some terms:
Complete: Your data provides full system visibility throughout the user journey, connected across all services. There are no gaps in the timeline, missing services, missing metrics, logs, or errors.
Usable: Your data is easily approachable by all engineering teams and roles, correlates business and technical context with user actions, and regularly leads to quick problem discovery and resolution.
Trustable: Your data is regularly evaluated for accuracy across all data types and responsible teams, with active governance of standards.
You don’t send more than you need: You sample traces and logs where appropriate, but regularly review sampling rates against acceptable margins of error.
You never send sensitive information: You have clear definitions for sensitive information, and effective technical controls and governance to ensure that sensitive data is either pseudo-anonymized, redacted, or filtered. You have a regular review process and an incident procedure in case your rules are violated.
To bring these principles to life, you need an observability data strategy. There are two foundational elements that work in tandem: data governance (the people and processes) and telemetry pipelines (the technical implementation).
The building blocks of a good observability data strategy
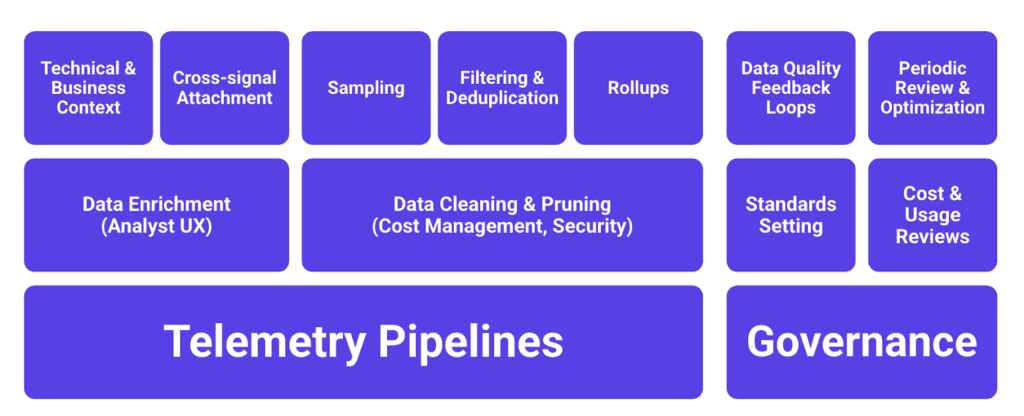
Data governance
Data governance is the foundation of any effective observability data strategy. Before you dive into pipelines, sampling, or enrichment, you need clear answers to basic questions:
- What data matters?
- Who is responsible for it?
- How do we define quality?
- What information is sensitive and how must it be handled?
Without governance, your observability efforts risk becoming disorganized, inconsistent, and ultimately untrustworthy. Governance is what turns a pile of telemetry into a reliable system by setting standards, assigning ownership, and ensuring data serves its intended purpose.
We’ve found that the challenges and needs of observability data are very similar to the BI/data domain—it’s just in a different setting and with different constraints:
- Your SREs and observability team wear the hats of data engineers, analysts, and everything in between
- Your system availability and data usability is tested 24/7 and crises often occur off-hours, like at 2 a.m.
- Query speed and data availability need to be near-real-time, especially during incidents, to support rapid iteration on queries
The value of your observability system, including the data within, is subjectively measured when:
- Alerts happen. Good alert coverage with low false positives and false negatives increases perceived confidence and value in the system.
- How well it empowers your team to solve hard problems without needing to resort to manual debugging.
- When it’s being used by new employees and/or those who normally don’t use the system.
This is why someone must be responsible for overall data quality and usability, and setting standards for all others to follow. A data governance practice does not have to be overly complex and unwieldy, but it must tackle the above needs and perceived value challenges. That means having a process for reviewing the quality and usability of the data, as well as defining, encouraging, and enforcing standards on all teams and code owners:
- Troubleshooting jumping-off points (dashboards, alerts, and SLOs) are intuitive, easy to find, and well described.
- Data organization should match the real-world deployment in terms of environments and services.
- Field names and types should be intuitive and easy to find, well described, and consistently applied.
- Sensitive values (such as PII and secrets) are effectively redacted or pseudo-anonymized, and audited regularly.
At a minimum, your data governance practice should consist of a data governance leader, and a periodic review process.
A mature data governance practice would include a defined system of ownership and distributed accountability, a defined process for setting and auditing standards, a data quality discussion and improvement step during incident retros, and a feedback process for telemetry pipelines.
Telemetry pipelines
In the data world, pipeline tools like Airflow, Spark, and dbt have become the gold standard because they let teams shape, validate, and control the flow of data—ensuring quality, reducing waste, and enabling governance at scale. The same principles apply to observability. A well-designed telemetry pipeline isn’t just a conduit—it’s a control point. It’s where decisions get made about what data to collect, how to enrich it, when to drop it, and who is accountable for it.
A telemetry pipeline is a fundamental building block that enables nearly all technical aspects of the data strategy. It may start off extremely simple, with an SDK in your service configured to send data directly to an observability backend. Or perhaps you have fleets of OpenTelemetry Collectors running a wide variety of configurations. For a good primer, check out the article What is a Telemetry Pipeline?
A mature telemetry pipeline should be treated with the same criticality as any other production system, meaning that it is highly available and fully managed using infrastructure-as-code practices, monitored, and alerted on. A loss of production telemetry data incident is treated similarly to an outage in production.
An advanced telemetry pipeline incorporates dynamic sampling, tiered storage, a unified management interface, and enables self-service at scale.
Let’s break down the main capabilities we need from telemetry pipelines:
- Data enrichment: adding contextual fields, or mutating existing data to make it more useful in analytics.
- Data pruning: reducing the volume of data being sent.
- Data cleaning: redacting, anonymizing, or filtering out potentially sensitive data.
Data enrichment
When understanding the scope of a problem, business context is priceless. This is why having high-cardinality fields, such as detailed user and customer information, infrastructure and execution environment information, and code orientation are so valuable when troubleshooting an issue.
There are three types of context that all of your telemetry data should be enriched with:
- Business context: User ID, company ID, plan level, shopping cart contents, etc.
- Technical context: Cloud region/zone, instance type, Kubernetes node/namespace/pod, etc.
- Code context: Name of function, inputs, database query latency and results, etc.
While your telemetry pipeline can and should automatically add most of the technical context, it is up to auto-instrumentation to apply the code context, and custom instrumentation to handle the business context (because you know your business best).
A mature data enrichment practice is where all context fields are standardized and consistently applied, where frontend and backend requests are connected, and where metrics and logs can be correlated to traces (and thus individual user actions).
An advanced data enrichment practice is where high-dimensionality and high-cardinality fields are effectively used by all. Telemetry data is used as a deployment and/or release gate.
Data cleaning and pruning
Maintaining a perception of “highly valuable” data also means effectively removing or never emitting data that is perceived as noisy or useless. Some examples of highly prune-able data:
- Traces associated with highly repetitive requests, such as health checks and cached home page loads.
- Well-known “noisy” auto-instrumentation libraries such as Redis (when used as a caching layer), producing hundreds to thousands of extraneous spans per trace.
- Leftover log statements meant for debugging purposes.
- Metrics scraped at a far shorter interval than necessary.
There are a variety of techniques for reducing or eliminating data, ranging from the simple and very inexpensive to the computationally intensive. The cheapest is the span that is never emitted, meaning in-SDK filtering caught it or certain types of auto-instrumentation have been disabled. Utilizing an OpenTelemetry Collector with a processor (e.g., filterprocessor, logdedupeprocessor, probabilisticsamplerprocessor) increases operational complexity but is highly performant. A tail-based sampling proxy such as Refinery is the most computationally intensive approach, because traces must be buffered in memory until complete in order for a sampling decision to be made.
Unlike in the data world, where the term is used much more broadly, data cleaning in observability concerns itself with transforming or removing potentially sensitive information. This should be done along the telemetry pipeline using OpenTelemetry Collectors processors (e.g., redactionprocessor, transformprocessor).
A mature data cleaning and pruning practice effectively utilizes all of the above techniques at their most appropriate points. For example, noisy auto-instrumentation is caught at the source rather than adding strain to tail-based sampling proxies. Sampling is utilized, but margins of error are calculated and verified in real-world data.
Cost and usage governance
Finally, after data governance and telemetry pipelines have done everything they can to maximize the value of your data, it’s important to ensure that the data is used effectively in the context of contracts and budgets and that processes are in place to monitor and manage cost spikes.
Like data governance, the cost and usage of observability tooling needs an owner and defined process. The following principles should form the basis of this governance:
A high-level summary of your observability tools pricing structure should be available for your users to understand when they need it.
The reality today is that most engineers have little to no knowledge of how the tools they use are priced. This leads to many misunderstandings about which actions might be costing a lot and which optimizations are unnecessary. This is exacerbated by a wide variety of complex pricing structures. In an ideal world, all tools would have a usage page that is easy to understand and improves general knowledge. A practical solution in the meantime is to build “cheat sheets” for your engineers.
Cost should be commensurate with usage.
Consider a situation where 80% of telemetry volume comes from the production environment and 20% comes from staging, yet 98% of query activity is in the production environment. A sampling strategy for the staging telemetry should be employed in order to reduce its volume. As another example, is long-retention and rarely accessed data like audit logs being stored in hot/fast storage? This data can be moved to cold storage or some type of data lakehouse solution.
Cost spikes should be dealt with in a timely manner, but should never be an emergency.
Sudden increases in telemetry volume will happen in any production environment and are useful signal in and of themselves. Is there a sudden increase in traffic to your app? Has a new service been implemented? Perhaps an auto-instrumentation library has been upgraded and is suddenly emitting a bunch of noise. All of these scenarios are routine, and most observability tools will alert you when a sudden spike has happened. Honeycomb offers burst protection and will let you know when these bursts are detected. It’s important that someone receives these alerts and generates routine tickets for business hour investigation by on-calls.
At a minimum, your cost and usage governance practice should consist of a governance leader, and a periodic review process.
A mature cost and usage governance practice would include a defined system of ownership and distributed accountability, and a continuous improvement process.
Evaluating your data strategy maturity
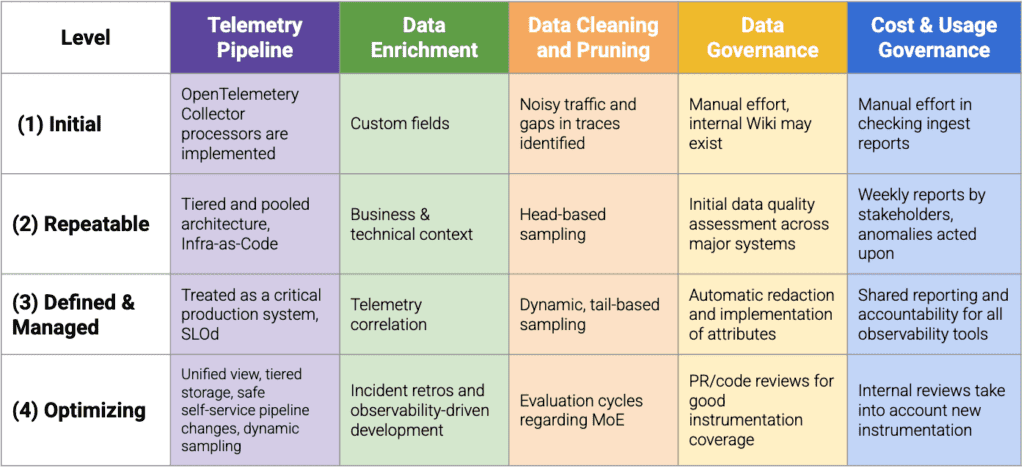
We’re building a workshop to help our enterprise customers evaluate their capabilities and maturity levels. If you’re interested in having your data strategy evaluated, please reach out to your account team or contact sales.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.