Observations on ARM64 & AWS’s Amazon EC2 M6g Instances
At re:Invent in December, Amazon announced the AWS Graviton2 processor and its forthcoming availability powering Amazon EC2 M6g instances. While the first-generation Graviton processor that powered A1 instances was better suited to less compute-intensive…

By: Liz Fong-Jones

At re:Invent in December, Amazon announced the AWS Graviton2 processor and its forthcoming availability powering Amazon EC2 M6g instances. While the first-generation Graviton processor that powered A1 instances was better suited to less compute-intensive workloads, this processor is intended to offer AWS customers a compelling alternative to conventional x86-powered instances on both performance and cost. The Graviton2 processor uses the aarch64 (“arm64”) architecture rather than x86_64 (“amd64”), so workloads reliant upon native x86, and their toolchains, do require being recompiled to function. In this blog, we’ll address how much work is involved in changing architectures, and whether it’s worth it. I spent a few spare afternoons over the past few weeks experimenting, and am pleased to share our observations confirming the improved performance and lower cost of M6g instances as compared to the C5 instances we currently use, despite M6g not being a C-family instance that’s tuned for raw compute!
Some architectural context
Honeycomb consists of our ingest workers (called “shepherd”), Kafka, query workers (“retriever”), and frontends (“poodle”). All of these (except Kafka, of course) are written in Golang, which supports cross-compiling for aarch64 out of the box. For our initial test, we chose to trial migrating a subset of the shepherd workload as it’s stateless, performance-critical, and scales out horizontally.
Shepherd’s core task is parsing incoming telemetry in JSON or msgp format, performing validation and access control, then serializing the data to Kafka. It sits behind a load balancer that round-robins traffic to each healthy serving task. Thus, it’s a perfect performance and cost test for JSON parsing and compressed Kafka production on M6g, performed head-to-head against the spot purchase and savings plan C5 & C5n instance families we run Shepherd on today.
We run three environments: production for our customers’ telemetry, dogfood for analyzing production’s telemetry, and kibble for observing dogfood in turn. Which environment was most appropriate for this test? We didn’t want to risk degrading or dropping customer data, so that ruled out production, and kibble has nothing that observes it. Thus, the choice was clear to deploy a few instances of M6g in our dogfood environment, and observe the results using kibble.
Setting up the experiment [gory details]
The first challenge was to run a local Golang build with `cd shepherd; GOARCH=arm64 go install .`. That completed without incident, as did compiling all our application binaries with GOARCH=arm64 and integrating the cross-compilation into our continuous builds & artifact storage. Next, we swept our codebase and transitive dependencies to identify any code dependencies on either cgo native compilation or x86_64 inline assembly without an alternative pure golang implementation. Having discovered nothing that would outright break, only at worst degrade performance, we could proceed to bootstrapping an m6g.xlarge canary instance.
We don’t use Kubernetes or container orchestration for workload serving. Thus, every machine bootstraps from a Packer-prepared AMI, runs pre-flight scripts, converges with Chef, and then unpacks and runs application binaries. So, the first task was to run Packer to customize the latest Ubuntu Bionic Beaver 18.04 arm64 AMI with our firstboot scripts using a special Chef recipe. Unfortunately, Chef’s official builds for Ubuntu (and indeed, for all OS flavors), are only available for amd64. And Bionic’s package repo ships with extremely crufty Chef (12.14). I had to do a quick backport of Chef 13.8 from Focal to Bionic, compiling both for amd64 and arm64, in order to get our Chef recipes to work correctly. Packer succeeded finally, and we had an AMI we could use to provision arm64 instances into the Shepherd serving pool.
Next step: booting one server, inside an ASG. Unfortunately, while AWS will allow Spot instance type mixing for ASG scale-up, it won’t allow the AMI to be varied or permit precise control over how many instances of each type are created. Thus, I had to create a special ASG in Terraform just for arm64 instance types and corresponding boot AMI, with a target ASG instance count of 1 for testing. I did not yet add it to the target group, as I wasn’t yet ready to serve real dogfood traffic off it. The machine booted and I could ssh in!
But then the firstboot script emitted a litany of failures as it ran the full Chef cookbooks for the first time. Several of the recipes’ dependent gems such as xmlrpc refused to native compile during rubygems dependency fetching, but had readily available substitutes that could be installed system-wide from the Ubuntu package repositories. The gem we use for zookeeper locking during code releases failed to compile on aarch64, so I had to both port and backport it. Our open source telemetry-forwarding utilities such as honeyvent and honeytail were compiled for amd64 only, so I had to apply a quick GOARCH switcher to our CircleCI configs to build, tag, and upload them. Wavefront’s install recipes only know about amd64, not arm64, versions of InfluxDB’s telegraf binaries, so I had to patch the recipe to install InfluxDB’s version prior to configuring Wavefront. Amazon’s Inspector Agent worked out of the box once I found the correct s3 path for their arm64 package. But the biggest stumbling block was the security/auditing tool osquery, which I had to skip and come back for later with the help of my friend Artemis.
Finally, once enough things were replaced or temporarily commented out of the Chef recipes, we had a fully functioning server that could fetch our application binaries and run them. With trepidation, I ran `sudo service shepherd start` and the service came to life. After quickly testing its health endpoints, I added it to the target group, and it began serving live dogfood traffic, and transmitting its own telemetry in turn to kibble so I could compare its performance to its peer instances. This whole process (except osquery) took about two weeks of wall time, and about 15 hours of work from me, an experienced generalist systems engineer/SRE. And you can benefit from the backporting and compatibility work we did, if you follow in our footsteps!
Show me the numbers and charts!
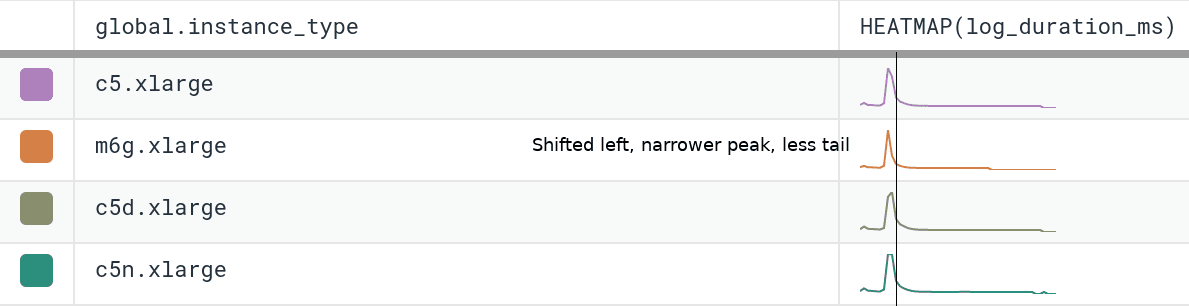
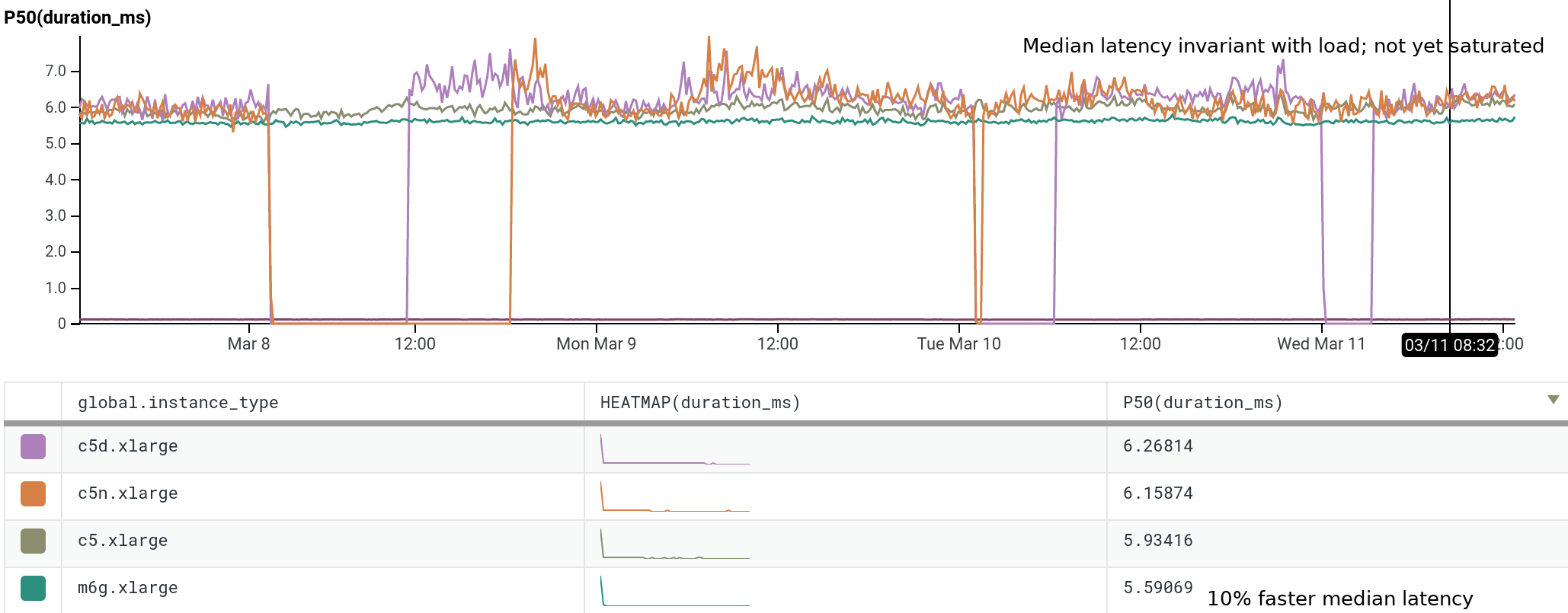
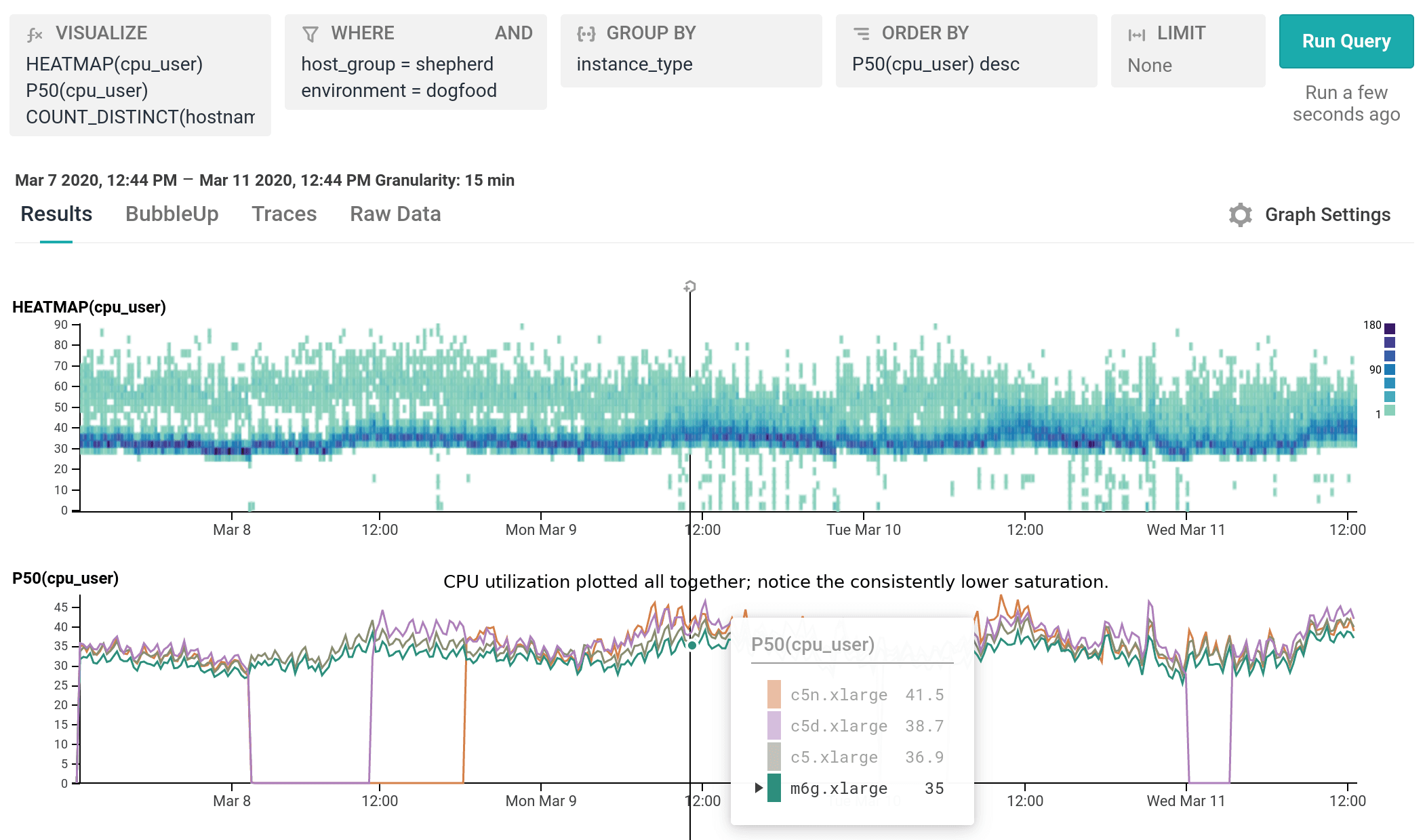
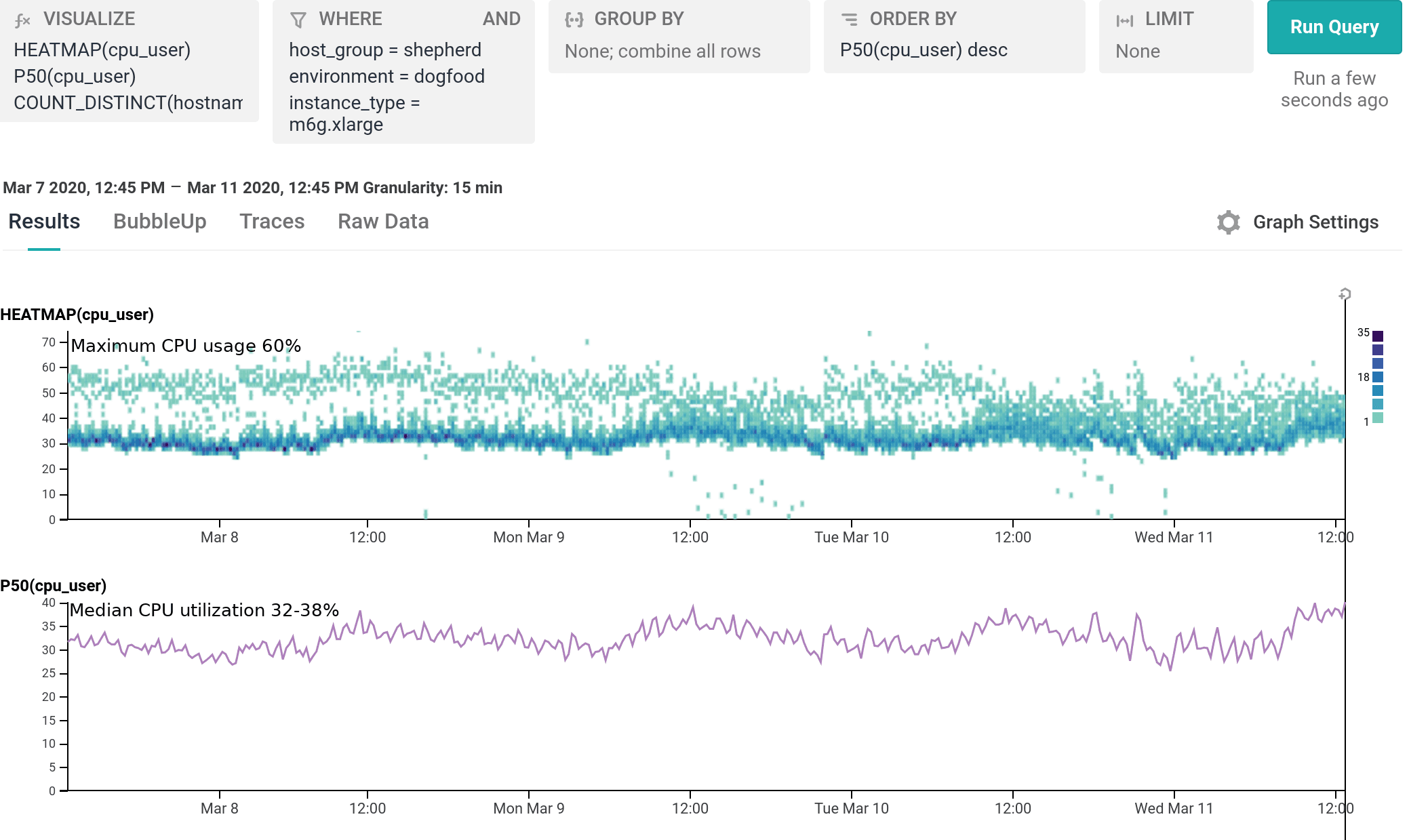
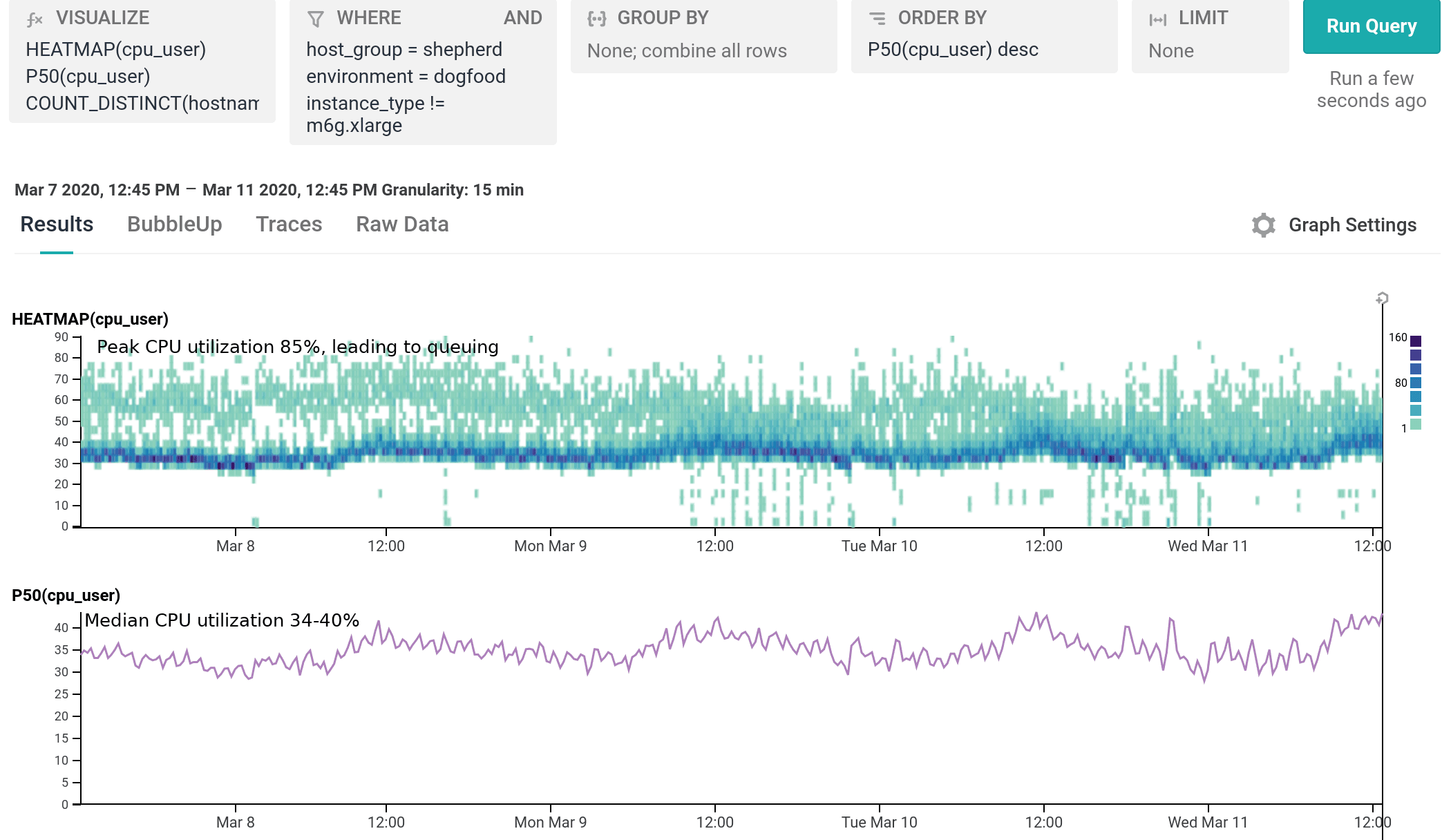
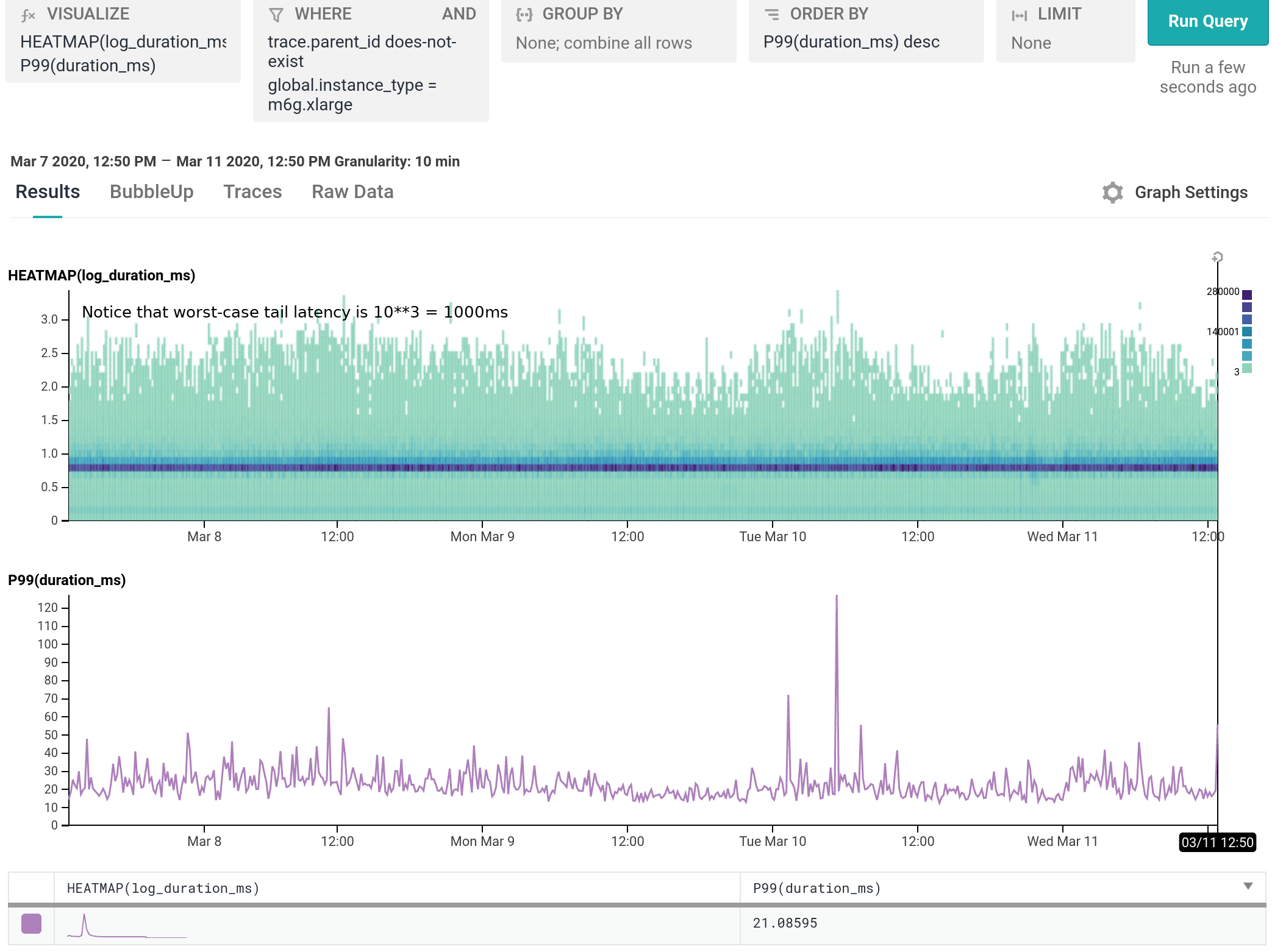
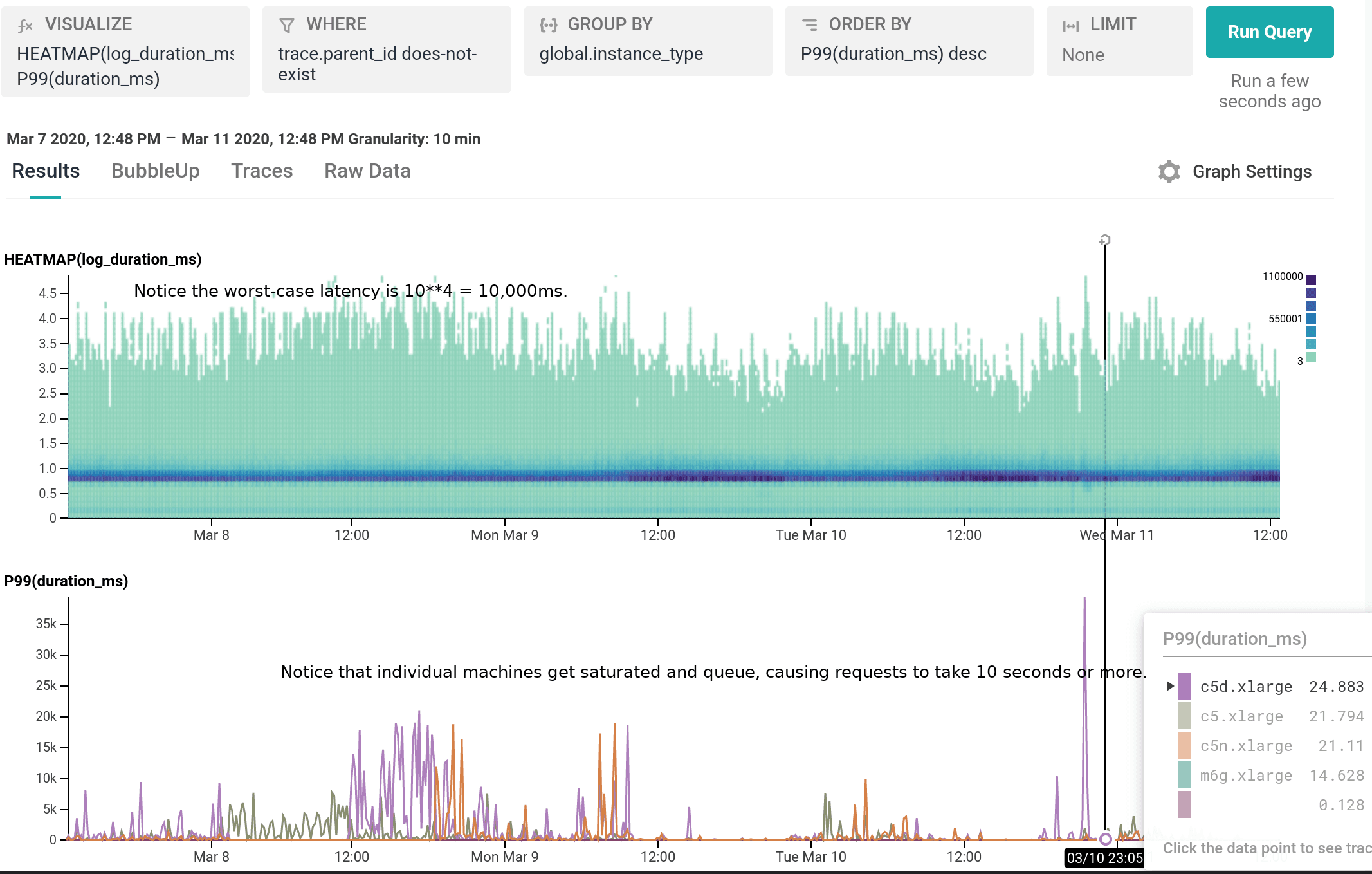
We’ve been running m6g.xlarge for several weeks as 20% of our dogfood shepherd fleet, head to head against c5.xlarge and c5n.xlarge. It is a well-integrated equal citizen in our workflows, with every hourly release being automatically built for and deployed to both amd64 and arm64. arm64 behaves like any other instance from an operability standpoint, the only difference being the text `My architecture is: aarch64` scrolling by as the deploy script finds its artifacts. As of today, we’ve shifted 100% of our dogfood shepherd workload to run on M6g, using 30% fewer instances than we used with C5.
For our use case, M6g is superior in every aspect to C5: it costs less on-demand, has more RAM, exhibits lower median and significantly narrower tail latency, and runs cooler with the same proportional workload per host. As demonstrated in our dogfood shepherd environment, if M6g were the only instance type in our fleet of Shepherds, we could run 30% fewer instances in total, and each instance would cost 10% less on-demand versus C5. Was it worth it to port? I personally approached it as an idle experiment with a few spare afternoons, and was surprised by how compelling the results were. Saving 40% on the EC2 instance bill for this service once we’re able to fully convert our instances to Graviton2 is well worth the investment, especially in this new economic climate.
However, M6g is not yet available to customers in production quantities, and cannot yet be bought off the spot market, so we expect to continue to use C5 instances for the foreseeable future in production. But we look forward to fully making the switch to M6g or C6g once they’re out of early access and commercially available!
Liz Fong-Jones is a Principal Developer Advocate at Honeycomb.io, provider of observability tooling designed for modern engineering teams to observe, debug, and improve their production systems so that business-critical apps maintain resilience. Teams reduce toil, ship code faster and keep customers happy.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.