What Are Some Useful Things to Look for Right Away When You Get Data into Honeycomb?
Here’s what some of our customers had to say about Honeycomb features that they found value in right away.

By: Rynn Mancuso
At Honeycomb, we love involving our customers when we can. We asked: “What was the first thing you found value from with Honeycomb?” Here are some of our favorite answers.
You probably have an embarrassing number of N+1 queries and it’s bogging your front end down
N+1 queries are where you go to retrieve one item (say, a customer), but end up retrieving a bunch of related items (say, their contacts), and it retrieves those one at a time. You asked for one customer, and you got N+1 database calls, where N is the number of contacts that customer has. This happens to a lot of us because many web frameworks employ lazy-loading by default, which means they execute a SQL query for every child row they load, plus one for the parent row. You only needed two queries to do that, and with a small test database, the difference in performance may not be obvious.
To find these in Honeycomb, you’ll want to group your traces on trace_id and examine traces that have a large number of spans.
“The first easy win I got from Honeycomb was probably finding traces and grouping on trace_id and looking at traces that had a huge number of spans in. This helped me find some obvious N+1 query problems.”
-Ollie Charles, CircuitHub
“hahahah, the first useful thing we figured out after setting up Honeycomb is that our ORM (mis)use had generated a LOT of n+1 queries (the worst one was mnop+1).”
-Randall Koutnik, Jellyfish
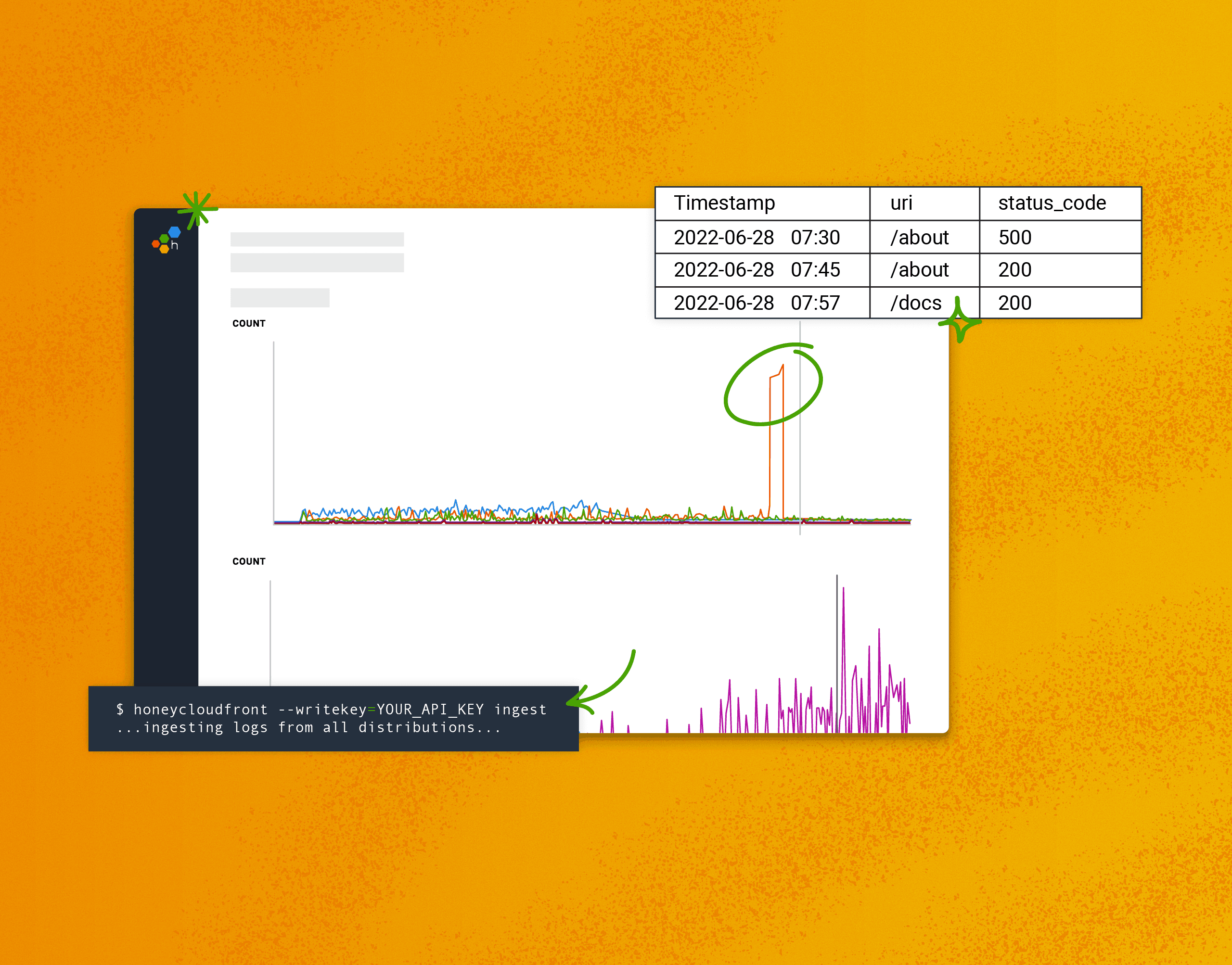
Dig into your Cloudfront data
Bringing your Cloudfront logs into Honeycomb is super easy to turn on, and it’s enlightening to look at that data and find out when content is loading slowly for your customers. We have a number of other AWS integrations, too.
“Hmm… honestly, the first thing was probably just what our customer facing CloudFront response times actually look like. CloudFront log exports to Honeycomb were one of the first things we enabled and prior to that we didn’t really have any visibility into that data.”
-David Whittington, AR Drive
Go right to Honeycomb after you feature flag in a change
Once you’ve flagged in a change, you can look at performance time in detail. If you’re using LaunchDarkly for your flags, they have an integration that will allow you to send flag status changes as markers. If you’re rolling your own feature flags, you can use similar logic. Additionally, you can use Honeycomb to clean up after a feature flag when it’s finally set to true for all users—it’s easy to forget to remove these.
“Time for a request to complete and the parameters sent into the request was very helpful. Especially when feature flagging in changes that can affect performance.”
-Kevin Kruger, LaunchDarkly
Look at BubbleUp. Yes, even if you’re literally having an incident right now
BubbleUp is Honeycomb’s secret sauce. It’s our favorite feature when we dogfood, and 10/10 SREs who have tried and failed to select a tiny piece of anomalous data in their APM solutions agree with us. BubbleUp allows you to select the outliers in a heatmap and ask, “What is different about these?”
“How super badass the BubbleUp feature was. It’s a literal game changer for us during incidents, since specific outlier metric comparisons is not something I’ve seen in a telemetry platform before.”
-Matthew Daize, TradeRev
You can dig into a specific service by creating a dashboard
This is slightly more advanced than the others, but for a lot of our users the most helpful thing is to create a dashboard for a specific service that is giving you problems. Especially if you’re moving from an APM solution that’s all dashboards all the time, this can significantly help your team see the power of Honeycomb—without having to move too far out of their comfort zone.
“I think the first useful thing I figured out was how to construct a service-specific dashboard that we could use to monitor the health of said microservice. We pinned queries for the rate of 500s, failed jobs, and db query length, and all of those have been invaluable in understanding system health.”
-Maya Ziv, censys.io
Bonus: share a honeycomb link with your team right away! Nothing like getting feedback from friends.
See for yourself
Interested in seeing what Honeycomb could do for you? We have a generous free tier we’d love for you to try. Sign up today and see how easy observability can be.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.