Anything But Tech Debt
Engineers often feel they aren’t allowed enough time to address tech debt. Product partners wonder why engineers spend so much time working on it—or at least talking about it. “The business” always seems to insinuate that engineers should do less of it, instead focusing on shipping value to customers. And despite all this, many engineering leaders worry their teams may actually be under-investing in tech debt, in ways that could negatively impact the business over the long term.

By: Emily Nakashima

Tech debt is usually one of the most fraught topics on engineering teams.
Engineers often feel they aren’t allowed enough time to address tech debt. Product partners wonder why engineers spend so much time working on it—or at least talking about it. “The business” always seems to insinuate that engineers should do less of it, instead focusing on shipping value to customers. And despite all this, many engineering leaders worry their teams may actually be under-investing in tech debt, in ways that could negatively impact the business over the long term.
With all of these conflicting opinions, it seems like there might be wires crossed in the system somewhere. What’s so wrong with tech debt?
What’s in a name?
Part of what makes tech debt so challenging to reckon with is how vague the term is. Nearly all engineering work has at one point been labeled “tech debt” by someone who didn’t like it. And the possible business justifications for addressing tech debt can vary. Is the term part of why these conversations are always so hard?
I think the broad nature of the term “tech debt” is part of its trouble, and a better label can help—or really, many better labels. Rather than talking about tech debt as a monolithic work type, I like to break it down into more specific categories.
The diagram below is one effort to identify more granular labels that I assembled for an internal meeting. I created a visualization of the major types of engineering work I saw our teams complete in a quarter:
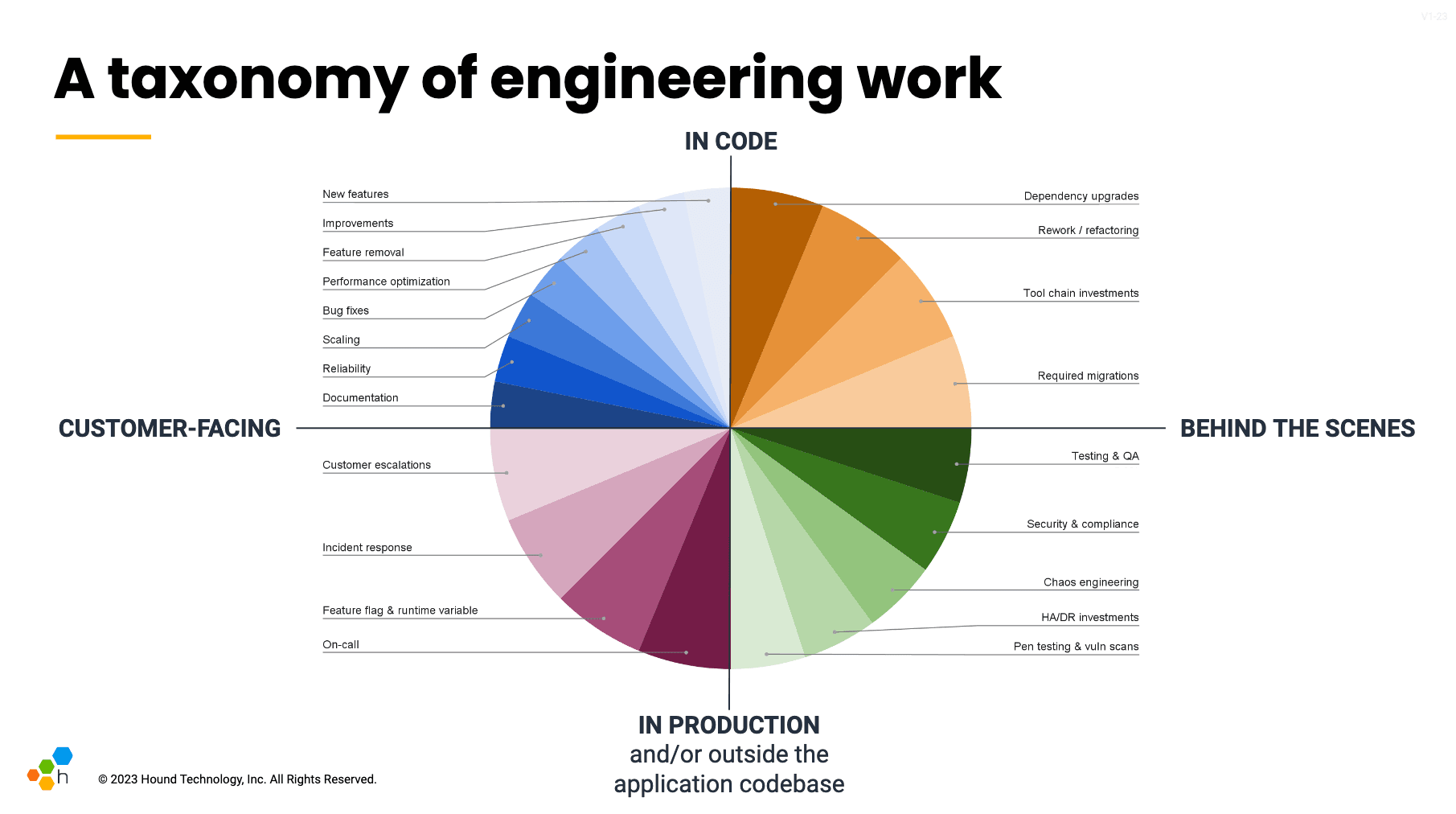
It’s easy to quibble with the specific labels and the categories I’ve stuck them under, and in another organization these might be the wrong set or the wrong categories. But the thing I immediately notice about each of these more specific types of work is how quickly any engineer I know could explain its value to the business. The more precise label helps reduce the need for elaborate explanation and business justification, because those reasons are made obvious by the labels’ descriptive name.
I took this diagram and drew a red dotted line around each slice referred to as “tech debt” at one point or another.
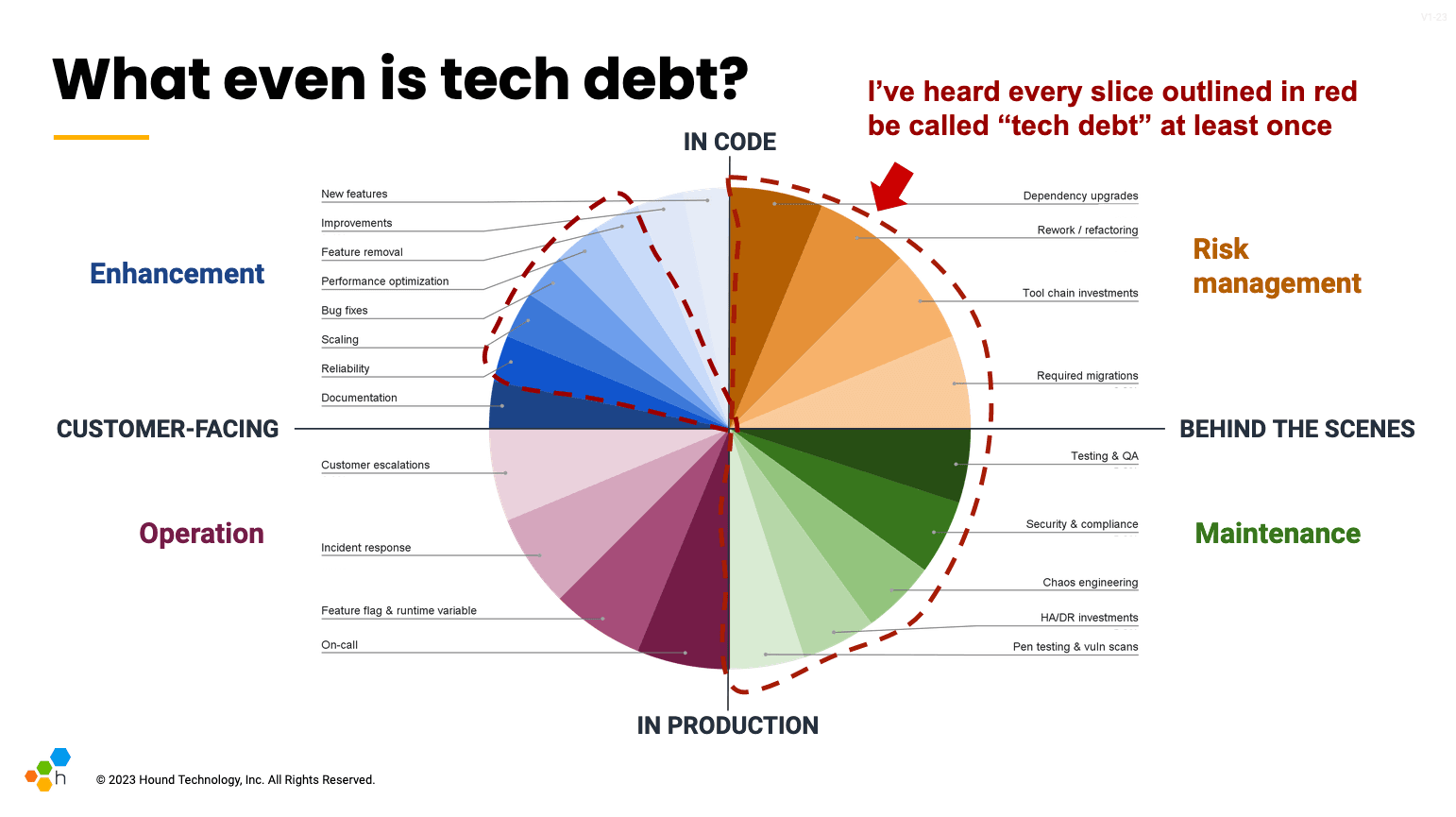
Stakeholders sometimes feel like engineering teams spend a lot of time on tech debt, but once you take the time to unpack all the work in the category, the exact reason for this is obvious. So-called “tech debt” could amount to more than two thirds of the different types of work an engineer might touch, if you apply the label broadly. And there is a business need behind each type. Of course all of this work could make up a significant portion of a responsible engineer’s quarter or year.
Struggling to negotiate time for tech debt? The right communication strategy can help
While many organizations struggle to prioritize all non-feature work, a few types of work seem to generate the most internal disagreement. Here are some strategies to make the case for the stickiest discussion topics.
Tool chain investments
Tool chain investments sound like they should be easy to pitch. Tools make us more productive, and everyone wants more productive engineers, right? But in reality, getting a solid return on investment from bringing in a new tool or an existing one can be a challenge.
Many tooling investments fail to gain adoption or don’t deliver on the productivity benefits. How will you make sure engineers adopt the tool successfully? How will you measure and communicate the ROI, including outside of your immediate team and to leaders around the company? Addressing these questions will help you build a stronger case to take the time (and money, if it’s a paid product) to invest in the tool.
If you know you’re facing a particularly tough internal fight to adopt a tool, I’d recommend taking a look at the frameworks used by enterprise sales teams when they plan the sales process. For example, MEDDIC—or the variant I’m more familiar with, MEDDPICC. Not all pieces will be relevant to you as an internal champion, but generally speaking, a framework can help you break down what it takes to sell a new tool to internal stakeholders, get a plan approved, and build toward successful adoption.
It’s also worth thinking through the payback period for a tooling investment. Even if a tool is widely adopted and genuinely valuable to the team, the payback period could be longer than makes sense for the organization’s current constraints.
What’s a payback period? Say it takes me one day to implement a new tool, and each week in the future it will save our engineering team a quarter of a day of work, in total. In that scenario, the hours I invested in implementation would “pay back” in four weeks (assuming all engineers’ time is equally valuable to our business, and leaving out the opportunity cost of whatever work I could have done with that initial day).
An investment that pays back in four weeks is generally a good one for most businesses, unless they’re a startup that’s very short on runway or the business is pursuing an extremely time-sensitive opportunity that requires lots of work right now. However, it gets murkier when the payback period is longer. I’ve spent a lot of time at series A-D startups, and in most cases, a payback period of three months to one year was the maximum horizon we should have considered for the business conditions we were in.
Reliability
Reliability investments are another category that sound so obviously good, who could be against them? But engineers nonetheless struggle to negotiate time for this sort of work, even when dealing with a heavy load of incidents and off-hour pages.
While some workplaces are staunchly committed to being inhumane meat grinders that don’t respect people’s time and quality of life, there are also well-intentioned organizations that nonetheless get this wrong. Sometimes the missing ingredient is visibility: those who could change the current setup don’t know how bad it really is. For this sort of situation, regular on-call health reporting can go a long way.
But often, the situation can be more complex. There’s a need to invest in reliability, scaling, maintenance, tooling, product roadmap, quality, etc. This results in a struggle to balance reliability with all those other needs.
The best approach I’ve seen for making the case for reliability investments is to do it up front by using Service Level Objectives (SLOs). With an SLO-based approach, technical teams and business stakeholders align on what sort of reliability they believe their customers and the business needs, setting a reliability target together. This target is usually framed as the percentage of requests to the service that are successful. For example, for our customer-facing web application, we might set an SLO that 99.9% of requests to our application should be handled within one second and without errors.
By setting a shared expectation up front for how services should perform, teams are then able to frame the need for scaling and reliability work in terms of risk to the SLO. Business stakeholders then get handed a clearer tradeoff: do we invest now, or do we decide meeting our 99.9% SLO isn’t important and we’re ok with reducing the target to, for example, 99.5%?
Rework
Rework or refactoring is probably the category most associated with “tech debt” in software engineering. It usually involves taking hard-to-maintain, messy, or confusing code, and updating it to improve its readability and maintainability without changing its user-facing functionality.
There’s a lot to say about refactoring, with many good books written on the topic. But the important thing that often goes unacknowledged is that many refactorings fail. The worse the initial problem and the more ambitious the refactor, the more likely the refactor is to lead to a negative outcome. For a refactor to succeed it 1. must actually ship, 2. must improve the maintainability and readability of the codebase for future travels, and 3. must save enough future time or pain, in a reasonable enough payback period (see above), to have been worth the opportunity cost. These three criteria are listed in order of difficulty to assess—and in difficulty to measure.
Debt is still a useful concept
While tech debt is rarely a helpful label when making the argument to pay down debt, the notion of “debt” remains a useful one in software engineering. We can invest in something today, or we can borrow against the future and plan to invest later.
While tech debt may not be a useful label when advocating for the next interval’s work, it’s still useful at another point: the moment of potential debt creation, when making the choice to invest in a particular effort now or wait for the future. The concept reminds us that the timing of an investment and its cost are connected, and that usually things cost much more (in engineers’ time) to address later, but increasing flexibility in the present (opportunity cost) may still be the right choice.
I have often been that engineer (and later that manager) struggling to come to alignment with my stakeholders on when and how to pay down tech debt. So often, those disagreements were emotionally loaded and frustrating on all sides. Looking back, I realize how often the source of that disagreement was a fundamental misunderstanding of what the work was and why it was valuable to the business.
If you ever find yourself in an intractable debate on tech debt investments, I encourage you to try one of the more precise labels for the work you’d like to do. Sometimes, using a label that speaks directly to the business value of a type of work can do wonders to help both sides find a way to move forward.
Interested in reading more about engineering management? Read my article on Becoming a VP of Engineering.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.