How Reliability and Product Teams Collaborate at Booking.com
This article originally appeared on the Booking.com engineering blog. For more by the author, visit his blog www.codecapsule.com. With more than 1.5M room nights booked per day, Booking.com requires a solid infrastructure that’s constantly…

By: Guest Blogger

This article originally appeared on the Booking.com engineering blog. For more by the author, visit his blog www.codecapsule.com.
With more than 1.5M room nights booked per day, Booking.com requires a solid infrastructure that’s constantly monitored. And indeed, Booking.com now has a footprint of 50,000+ physical servers running across four data centers and six additional points of presence. The sheer size of this server fleet makes it viable for Booking.com to have dedicated teams specializing into looking only at the reliability of those servers.
This article outlines how Booking.com’s reliability teams approach their collaboration with product teams on shared systems by using two homegrown tools, the Reliability Collaboration Model (RCM) and the Ownership Map.
Here, I provide background on the assumptions made when the RCM was developed and on how the RCM creates visibility for all the tasks required to maintain quality of service for a system running in production. I cover the three Support Levels of the RCM, including how a system gets upgraded or downgraded from one Support Level to another. I explain how the Ownership Map creates awareness on what systems a reliability team owns, and how it enables product leadership to make strategic decisions by providing their portfolio of systems with support that is proportional to their relative business criticality.
The Ownership Problem
One of the major goals of Booking.com’s Tech department is to enable product teams to focus on developing new features without having to worry about the infrastructure. To achieve this goal, dedicated reliability teams were assigned to look after each of Booking.com’s major platforms. Complications arose when a single reliability team had to manage a system for which multiple product teams would be pushing code independently. Further yet, there were even some extreme cases of dozens of product teams sharing a single system.
I was the Manager of Infrastructure leading Booking.com’s reliability teams when the reliability organization started. This gave me the chance to witness first-hand that on top of solving technical problems, we needed to figure out how we were going to build and maintain healthy working relationships with product teams.
During our meetings and discussions with product teams, the one challenge that kept slowing us down was that each of these teams had a different understanding of what infrastructure and reliability meant — as well as varying expectations as to what reliability teams would do for them. Most product teams expected that reliability teams would do absolutely everything related to the system, including all the toil, monitoring, and incident handling — expectations which ultimately weren’t realistic. We had an ownership problem, because we hadn’t been explicit enough as to who owned what, and as an organization, we needed to solve this problem and consequently communicate it to the product teams.
We quickly settled on the idea of making an exhaustive list of all the activities that went into keeping a system reliable, as means to create visibility for product teams. Likewise, every system has a different criticality for the continuity of our business, therefore it wouldn’t make sense for Booking.com’s reliability organization to offer a single split of responsibilities to all systems and product teams. This is when the idea of having multiple tiers rapidly came in, as a way to represent different splits of responsibilities.
But these two ideas — the exhaustive list and the tiers — were simply starting points. In order to fill out the content and organize it in a way that would make sense, we needed all the help we could get. So we booked a series of whiteboarding meetings with some of the engineers, team leaders, and product managers within our organization. As a team and with our combined knowledge and experiences, we tried different lists of activities and ownership splits to figure out which one would make the most sense for this kind of relationship. The result of that work is what we now call the Reliability Collaboration Model.
The Reliability Collaboration Model
The Reliability Collaboration Model, or RCM, is the model we developed to map out all activities required to keep a system reliable, and who among the reliability and product teams would own those activities. We ended up placing a lot of emphasis on collaboration within this model due to the mistrust that could easily simmer between reliability and product teams.
The model, presented in Figure 1A below, is meant to be read from the point of view of a system. This particular system has one reliability team looking after it, with one or more product teams deploying new features to it. For the system to be healthy and deliver value to end customers, a certain number of activities need to be taken care of. For readability, they have been grouped into four main categories in the left column of the diagram: Basic Operations, Disaster Recovery, Observability, and Advanced Operations. The detailed list of the activities for each category can be seen on another page, in Figure 1B. You can also click here to download high-resolution PDF and JPEG versions of the RCM.
They include activities such as: capacity planning, dependency management, server upgrades, etc. We then defined three tiers, which represent three different ways that the reliability team and product teams can share ownership of responsibilities and activities for that system.
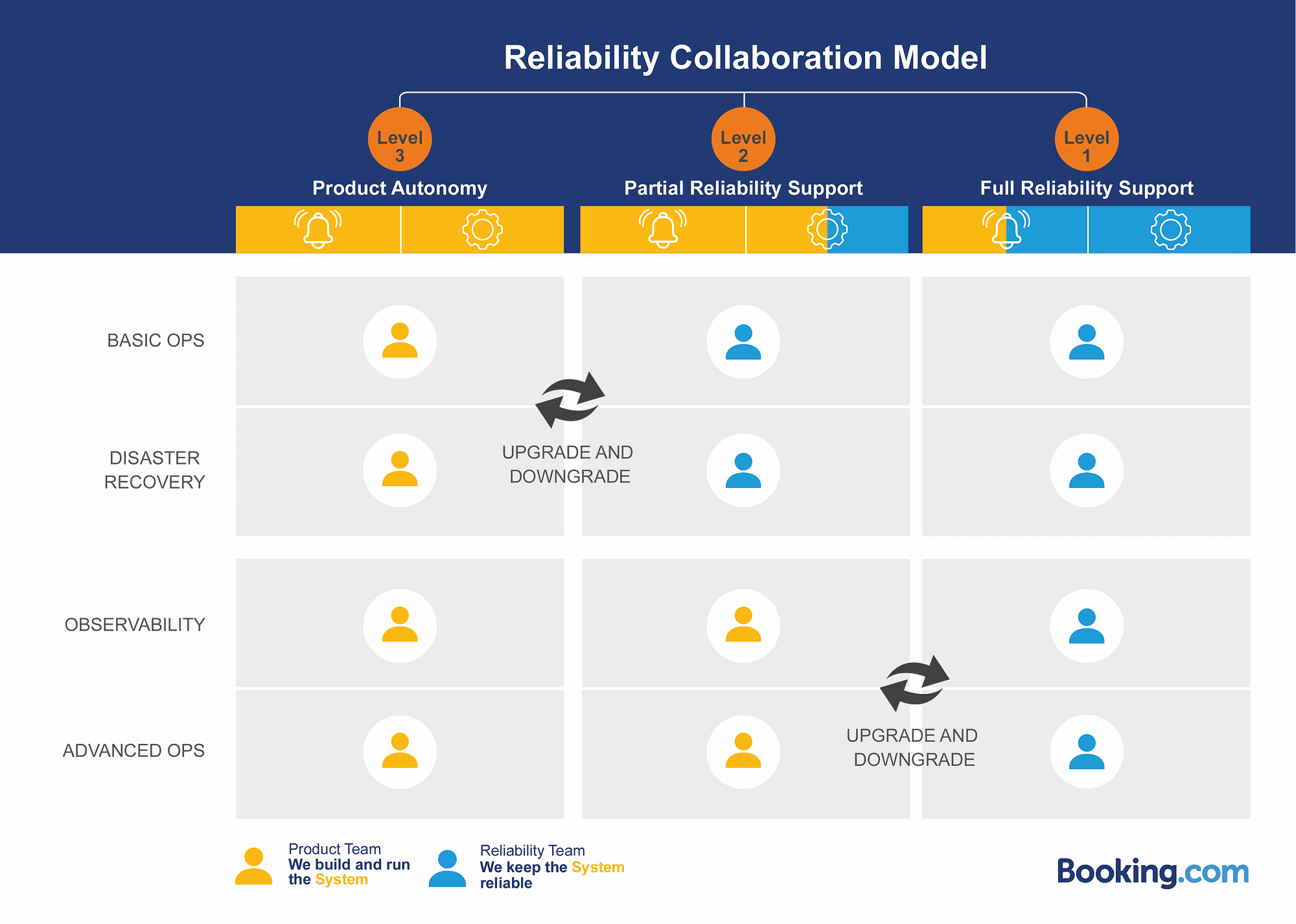
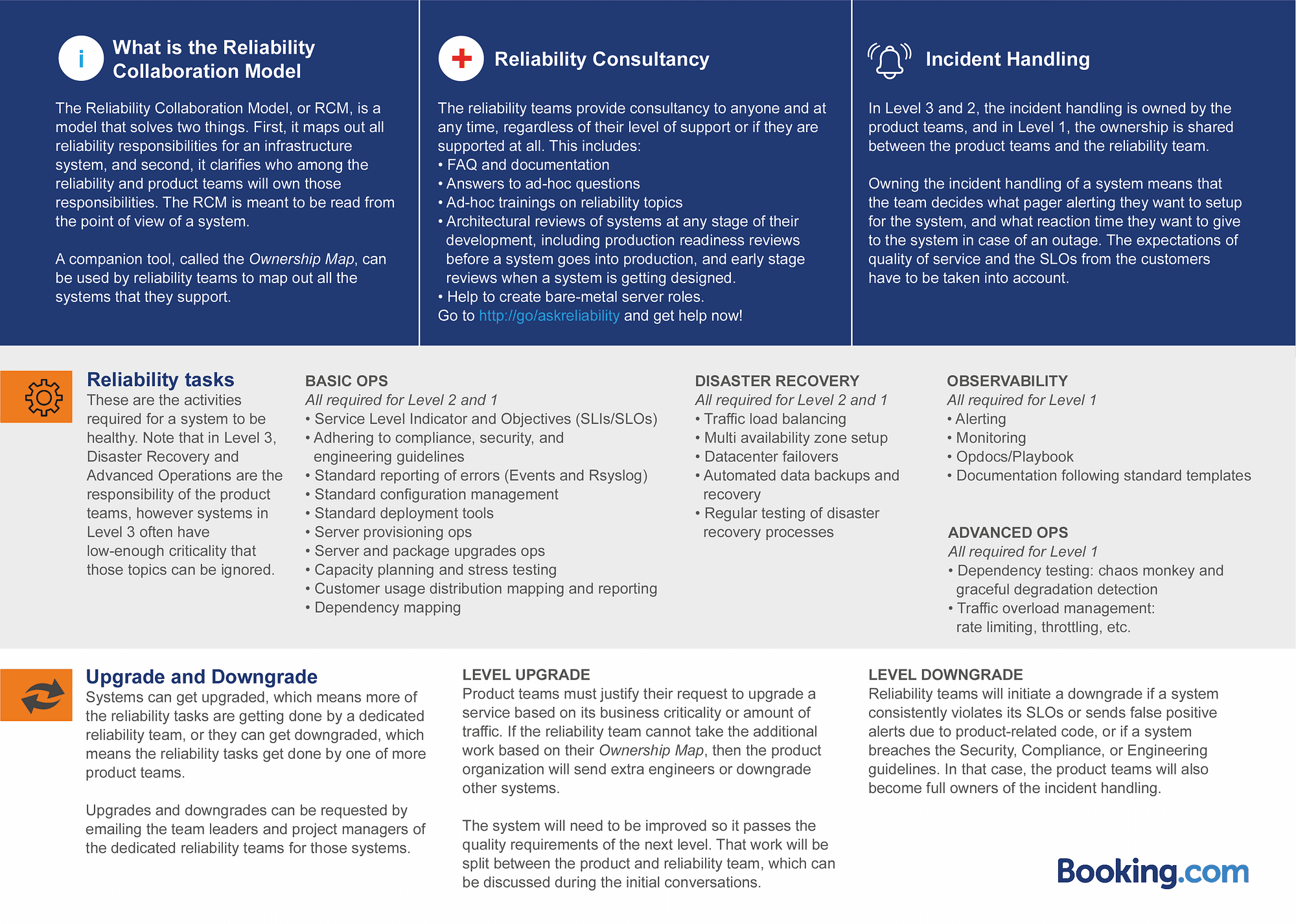
Regardless of the level a system is in, Booking.com’s reliability organization and teams offer their time on-demand to any person in a product team who wants their expertise, in the form of an informal coffee catch-up, an architectural review to prepare a launch to production, a meeting to define Service Level Objectives (SLOs), and further structured training on Booking.com’s internal tooling. The full list of what is offered can be seen in Figure 1B.
Now let’s dive into the definitions of Level 3, 2, and 1, and how such a system is upgraded or downgraded from one level to another.
Level 3: Product Autonomy
By default, all systems fall into Level 3, or Product Autonomy. In that level, the product teams are responsible for all the reliability topics of a system, and they receive best-effort support from the reliability team assigned to the system. If no reliability team is assigned, then they get best-effort support from the reliability community as a whole. It’s important to note that in Level 3, the product teams are responsible for holding the pager and handling incidents. This may sound scary to many product developers, but systems are usually placed in Level 3 due to their low criticality for the business. This means those systems do not create too much of a financial impact in case of an outage and can often be ignored for one or two days before being restored.
The list of reliability tasks can also seem daunting to product developers, but bear in mind that for most low-criticality systems, one doesn’t need to look into advanced topics such as user throttling or fine-grained dependency mapping. Therefore for systems in Level 3, the product team can use this list of reliability tasks to get an idea as to what they should be looking at. Furthermore they are free to choose to ignore some of those tasks if they don’t see value in them.
One could also argue that it’s not entirely fair to expect a team whose members mostly have experience with web development to take care of reliability tasks. For that reason — and to make sure systems in Level 3 are successful — the reliability organization created documentation, automated tooling, and training for each of the reliability topics in the RCM. This would allow product teams to do the tasks themselves without requiring too much context switching from their usual feature-focused work. In essence this is aligned with the Site Reliability Engineering mindset of using automation and eliminating toil.
Level 2 and Level 1: Partial Reliability Support and Full Reliability Support
In Level 2, or Partial Reliability Support, half of the reliability tasks still fall under the responsibility of the product teams, including alerting and holding the pager. The reliability team takes care of the rest of the tasks, which removes workload from the product teams who can then reinvest the time into releasing new features.
In Level 1, or Full Reliability Support, all the reliability tasks have been handed over to the reliability team, which enables the product team to focus only on developing new features. Notice that there is one thing that is still shared between the reliability and product team, and that’s holding the pager and handling incidents. This is because we’ve learned that it’s absolutely critical to include product developers in the pager rotation, just so that they understand the full cycle of deploying code to production, including deploying bad code that causes an outage, and in turn being paged for it.
Finally, it is important to note that Level 2 and 1 shouldn’t be seen as superior to Level 3. Level 3 provides a big advantage for product teams, which is that it enables full autonomy and development velocity. Being in Level 2 or 1 does send reliability tasks to the reliability team, but it also imposes adhering to certain standards and requires regular sync-ups with the reliability team, which will inevitably slow down development velocity. Therefore a product team should always think twice before requesting an upgrade of their systems to Level 2 or 1, and evaluate if such overhead is worth it.
The Criticality Problem
In the previous section I covered the reliability tasks and how they were shared between reliability teams and product teams according to three distinct Support Levels in the Reliability Collaboration Model (RCM). But what’s the process that guides the decision to put a system in a certain level, and who gets to make such a decision?
The RCM does not mention the criticality of a system, and there was two reasons for that. First, because the criteria that makes a system critical will vary from one business area to another. By keeping any mention of criticality out of the RCM, every business area can define what criticality means for them based on their own needs. Secondly, it helps clarify that it is not up to the reliability team to decide the criticality of a system and what Support Level it should fall into.
Instead the product leadership group of a business area is encouraged to make such decisions as they are best positioned to understand the business impact of an outage on their systems. Generally, this product leadership group would be formed of people managers, product managers, and some of the most knowledgeable engineers within that business area, but ultimately it’s up to a particular business area to decide. Booking.com’s reliability organization will then tell this product leadership group: “you’re getting a team of N engineers to look after the reliability of the systems in your business area. It’s up to you to figure out how you want to best use their time; you will focus their attention on what matters to you by telling them to treat your portfolio of systems in Level 3, 2, or 1.” Sometimes the business area that is getting support won’t be properly organized yet. In these cases they will require the help from the reliability organization to understand that they need to form a product leadership group.
In addition, people on the product side often have little experience with reliability and do not fully grasp the details and implications. Therefore it is the job of every reliability team to meet with the product leadership group for the area they support, to explain the RCM to them, and to help them figure out what levels they want their systems in. But again, the final decision is left to the people from that business area. There are some obvious limitations. For example, if the reliability team doesn’t have enough people to take on all the systems in Level 1, then it cannot happen. I cover what happens in such a situation in the section about Ownership Maps below.
Where do newly developed systems go?
Systems newly developed should start in Level 3, so that the engineers developing them feel the heat of being paged for bugs, and have a big enough incentive to bring their new systems up to proper quality standards. This approach is aligned with the SRE Engagement Model used by reliability teams at Google.
As for the case in which you need to use the RCM in an environment of many existing legacy systems, figuring out where to begin can be problematic. One thing you can do is use the amount of support that the reliability team gives those systems as a starting point, and later on retrofit those systems into the respective Support Levels that match them best. More about that in the section about Ownership Map below.
Level Upgrades and Downgrades
Systems can get upgraded, which means more of the reliability tasks are getting done by a dedicated reliability team. They can get downgraded, which means the reliability tasks will get done by one of more product teams.
For a system to be upgraded, the product teams must demonstrate that the business criticality or the amount of traffic justify the upgrade. Then based on the current workload of the reliability team — as shown in their Ownership Map — they will be able to determine whether they can take on the extra workload or not. If they cannot, the product organization may be required to send one or more engineers to the reliability team to take on the additional workload, or to make room by downgrading other systems currently supported.
Bringing a system up to the quality requirements of the next support level requires work. Some of that work will be done by the product teams, and the rest by the reliability team. The exact split of that work can be discussed during the teams’ initial conversations.
As for downgrades, they will occur in any of the following situations:
- A system consistently violates its Service Level Objectives (SLOs) or consistently sends false positive alerts to the pager due to changes being made by the product teams.
- A system breaches the Security, Compliance, or Engineering Guidelines.
- The product teams want a system to be upgraded and want to compromise on another system getting downgraded to make room.
Note that a level downgrade for a system implies that the product teams become full owner of the pager and its incident handling.
The Ownership Map
In the previous sections, I covered the Reliability Collaboration Model and how it helps solve the ownership problem. I also talked about how the criticality of a system and choosing what Support Level that system falls into should be left for each product organization to decide on.
At this stage, the separation of duties has been agreed on between the reliability organization and the product organization. But this doesn’t mean that this is the end. The majority of people who will be impacted by these decisions were not a part of those meetings, and until the outcome is shared with them and explained, no tangible alignment will ever be achieved between the reliability and product teams.
This is when the working group that came up with RCM also came up with the Ownership Map, which is a visual tool for reliability teams to map out all the systems that they support, and which is meant to be read from the point of view of a reliability team. This Ownership Map is then not only used to communicate the agreed-upon ownership split to all stakeholders, but to also create visibility for team members who had not taken part in the meetings. In addition, the Ownership Map is used to apply a portfolio management mindset to the grouping of systems that a reliability team looks after.
You can see an example below in Figure 2, for a fictitious reliability team owning several systems. The columns are the same as the one in the Reliability Collaboration Model, and represent Support Levels. The rows represent different degrees of criticality for the systems, the same that were agreed on by the product organization leadership team.
In that example, you can see that three systems have been flagged as critical and are getting Support Level 1: api-service, photos, and payment. You can also see that only one system is getting Support Level 2, analytics, and that two systems of lowest criticality are getting Support Level 3: admin and logging.
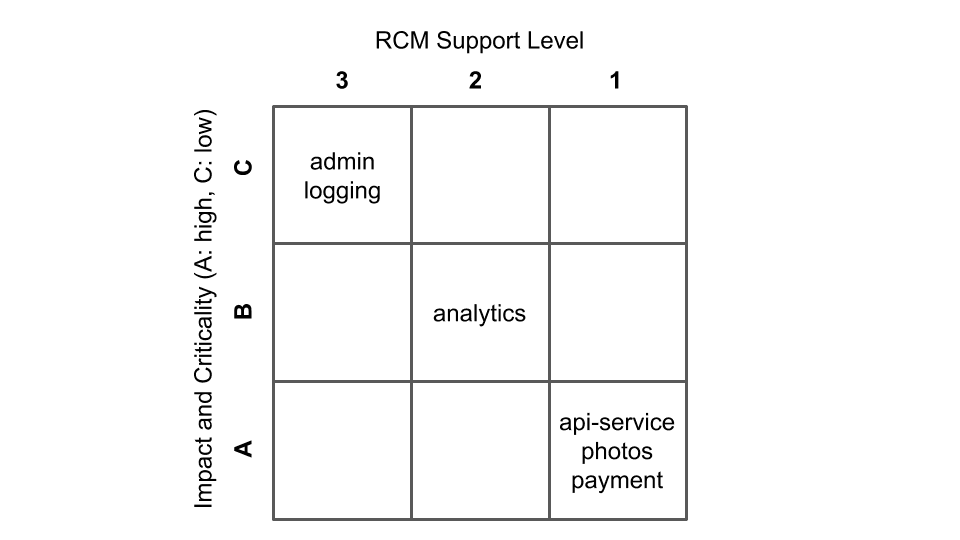
The ideal state of an Ownership Map is for all the systems to be in the diagonal line — like in the map in Figure 2. This would mean that the different systems are getting an adequate amount of support from the reliability teams, proportionally to their relative criticality and impact on the business.
But this ideal state rarely happens in real life. Often, systems are all over the place, they don’t meet the requirements for their Support Level, some are neglected, some are over-supported, etc. This is the reality and it’s okay. It gives the reliability team an opportunity to identify those problems and to act on them.
Reliability teams at Booking.com represent the transition process between current and ideal ownership states by putting two ownership maps next to each other. Figure 3 below shows what this looks like for the same fictitious team as above. On the left side you can see the ownership map for the current state of the team, and on the right side you can see the ownership map for the ideal future state of the team.

For example on the left, the logging system is currently in 1C, which means it is getting Support Level 1 — the highest possible — but it has been flagged as being of the lowest criticality for that business area — criticality C. Therefore on the right, logging has been placed in 3C, meaning that the reliability team intends to lower the Support Level for that logging system, and handover the reliability tasks and the pager back to the product teams.
Another important thing to pay attention to is the star next to some of the systems’ names. This star means that for some historical reason, the reliability team owns those systems and gives them support, but that the systems don’t yet fulfill all the requirements they should as expected by the RCM. For example, the RCM states that all systems in Level 2 must have Service-Level Objectives (SLOs) and report them using Booking.com’s standard tooling. If a system is given Support Level 2 but isn’t complying with all the quality requirements for that Support Level, then this lacking is flagged with a star on the right side, in the future ownership map.
It will then be up to the reliability team to bring up the matter to their product counterparts, and decide what work needs to be done to fix the problem. Eventually what you want to see is that both parties come up with an agreement as to who will allocate people to do the work, and that tasks are landing into the teams’ backlogs and ultimately getting completed.
What’s next?
Converting an entire department of hundreds of people to a reliability mindset doesn’t happen overnight. It takes years of engineering excellence to bring all systems to the desired quality, to patiently educate people at every level of the organization, and to listen to the needs and pain points of everybody who’s impacted or involved.
The Reliability Collaboration Model is only one of the tools and strategies that Booking.com uses. There is more that Booking.com does from a process and organizational point of view which has not been covered in this article, some of which consist of:
- Reliability Team Processes: a set of best practices that any team can follow to offer the best quality of service for their systems. One such process aims at planning for 50% time spent on project work, focused on tooling and automation. Another process is about regularly reporting SLOs for systems and running post-mortems to analyze the root causes of outages.
- Business alignment: reliability teams need to understand and align with the business goals of the product leadership group they support. In case one or more reliability teams own systems spread across different business areas, it is best to reshuffle those systems among all reliability teams so that each team ends up supporting a single business area.
- Team structure: Booking.com’s reliability teams usually consist of five to eight people, including a team leader and a product manager. Having a product manager is instrumental to improving stakeholder management.
- Downgrade readiness checklist: meant to help developers from product teams to take over operational work when the Support Level for a system gets downgraded.
The next step for Booking.com is to expand the reliability organization by having more reliability teams to support emerging business areas, while maintaining a consistent culture of reliability across the entire Tech department.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.