We Learn Systems by Changing Them
In the social world, there is no outside: we participate in the systems we study. I’ve noticed this in code: when I come to an existing codebase, I get a handle on it by changing stuff. Change some text to “HELLO JESS” and see it on the screen. Break something on purpose and see what fails. Refactor and find compilation errors. After I make some real changes and shepherd them into production, then I’m integrated with the code, I come to an understanding of it.

It is only possible to come to an understanding of a system of interest by trying to change it.
Michael C. Jackson explains Kurt Lewin’s work, in Critical Systems Thinking
Here, Jackson contrasts action research with old-style hard science, which tries to study a system from the outside. Laboratories draw a line between experiment and scientist. In the social world, there is no outside: we participate in the systems we study.
I’ve noticed this in code: when I come to an existing codebase, I get a handle on it by changing stuff. Change some text to “HELLO JESS” and see it on the screen. Break something on purpose and see what fails. Refactor and find compilation errors.
After I make some real changes and shepherd them into production, then I’m integrated with the code, I come to an understanding of it.
Jackson continues:
To ensure scientific rigor, this demands
a close analysis of the initial situation,
clearly documented action to bring about desired change
and continuous monitoring of effects,
and careful analysis of the end results of the action.
Michael C. Jackson on Kurt Lewin’s work, in Critical Systems Thinking
I do this in code too!
At a small timescale, I want to change what the code does.
A close analysis of the situation: I look at what it does now, and make sure that’s clear in the tests.
Clearly documented action: Version control tracks the changes that I make.
Continuous monitoring of effects: I run the tests after each change, and make them document the new behavior.
Careful analysis of the end results: And then I describe the why & how in a commit message.
At a larger timescale, we made this behavior change for a reason. “Did it work?” widens to “Did it have the effect we wanted?”
Here’s an example of how that can work.
A close analysis of the situation: I look at what the code does in production, and how it is used. I study a trace of the current flow.
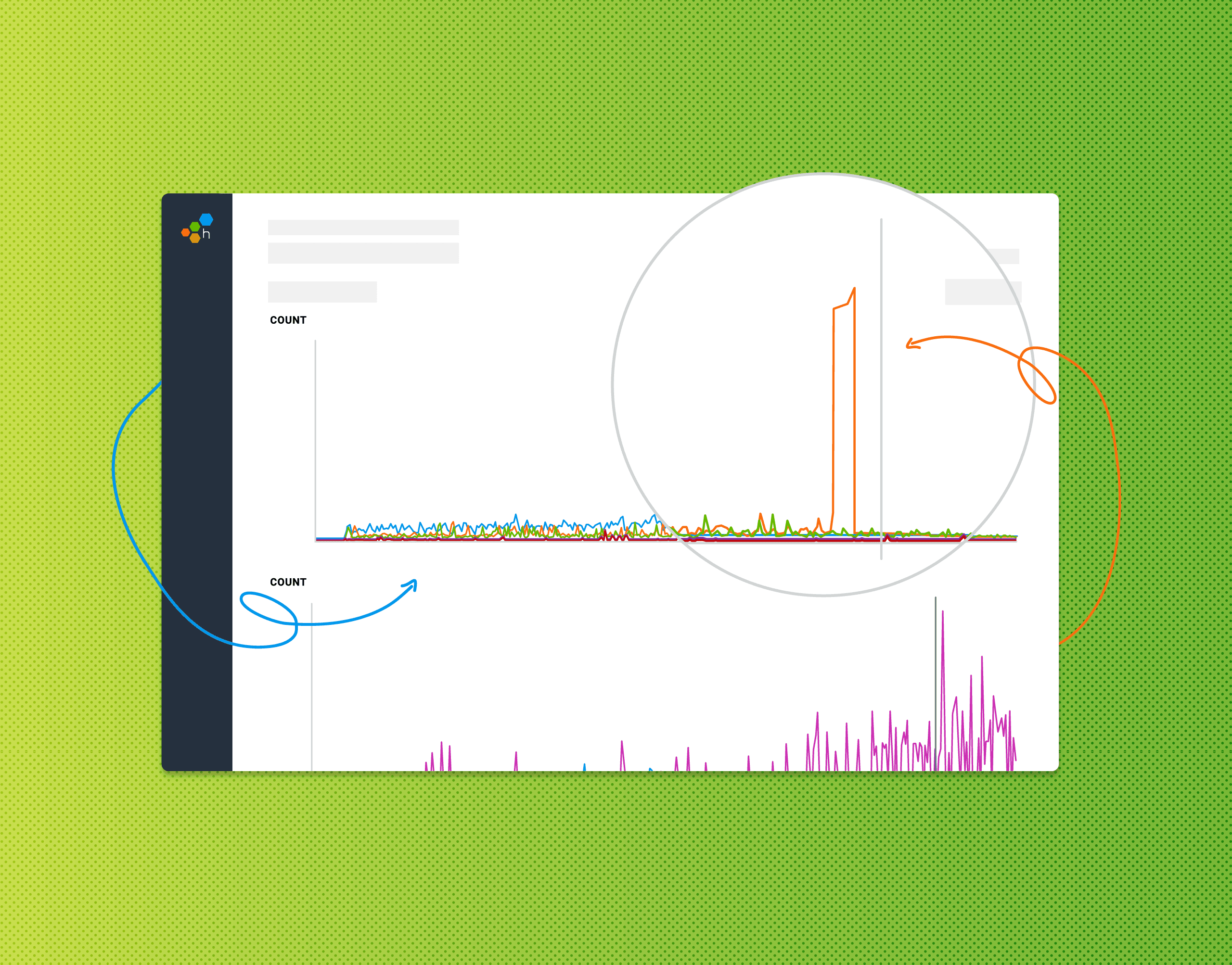
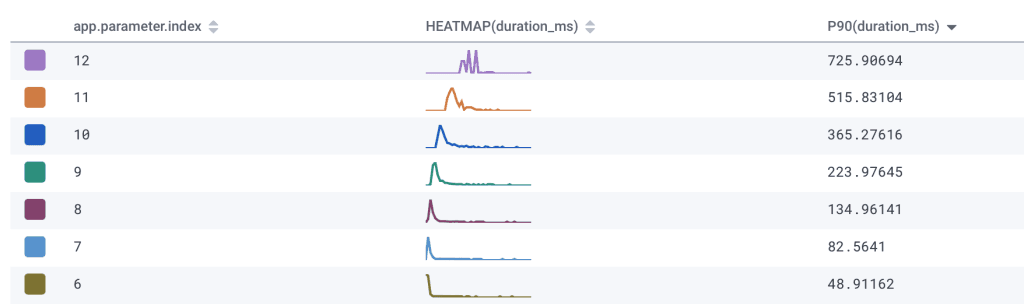
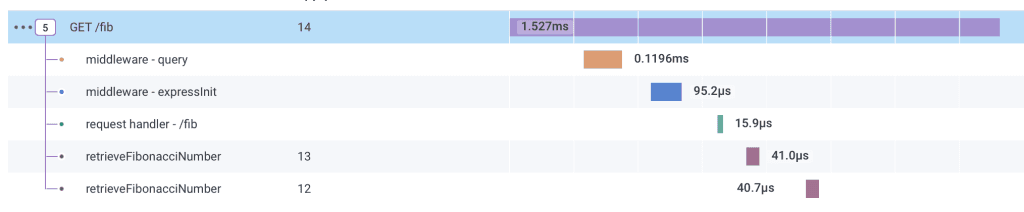
For example, maybe some sleuthing helps me notice that requests take longer for larger values of a parameter:
Then I look at a trace for a slowish request, and see a lot of nested recursive calls:
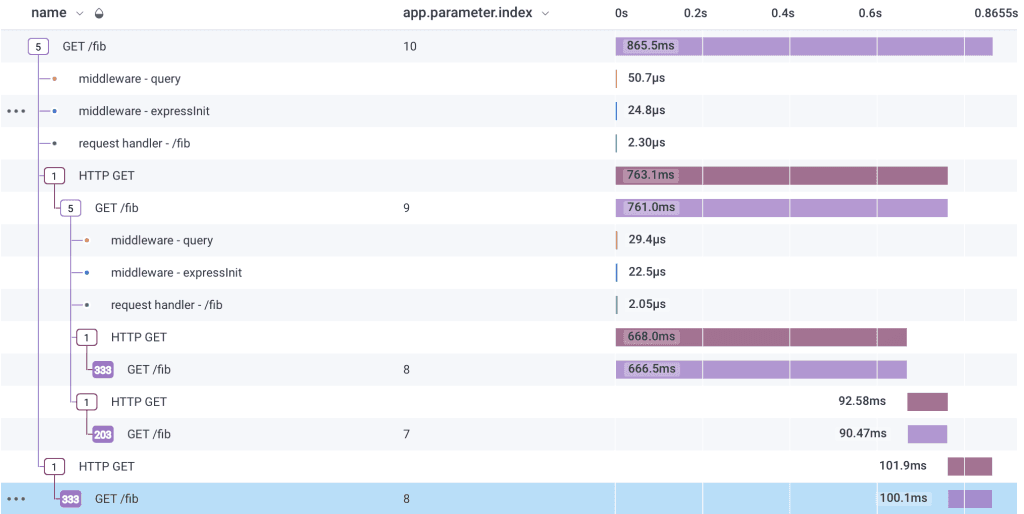
From this, I suspect that if we cache the return values, performance will improve at higher indexes.
Clearly documented action: A pull request documents the changes, and also my expectations for them. Deployment automation (or feature flag flip) documents when it went live.
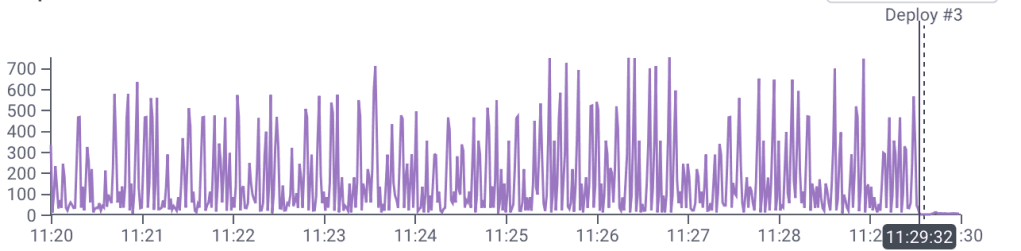
Continuous monitoring of effects: I look at a trace to see the new flow. Then I watch graphs of customer experience looking for unexpected changes.
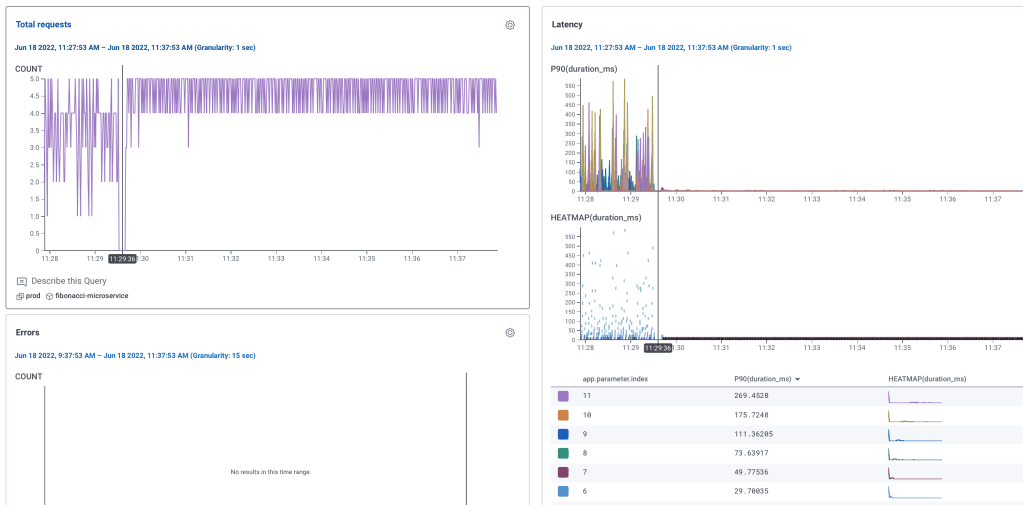
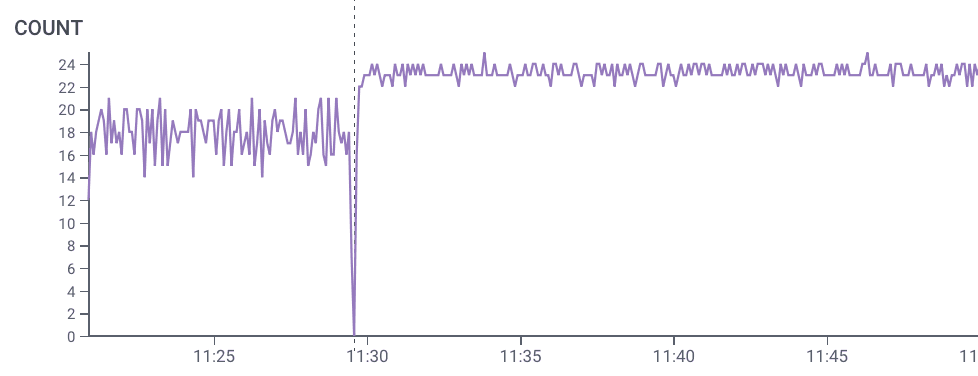
Careful analysis of the end results: A few days later, I go back to the same queries in the initial analysis, and check for changes.
I find that after the change, people are sending more requests than before. The performance improvement has made the app more useful!
While this example was pedagogical, we do this in real life at Honeycomb (to varying degrees). We compare performance before and after the change. We look at who is using the feature we delivered. Graphs and traces get shared in demos, while prioritizing, and in pull request review. Software delivery incorporates action research.
When we change software and look carefully at what happens, we’re gaining understanding of this system, the system that includes the running code, the people or software who use it, and the people who change it. We’re always changing systems by participating in them. With care, we will also come to a better understanding.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.