Logging tool no more: Observability sheds light on Dark’s business growth and helps their customers scale
Dark is a programming language and platform that enables building serverless backends. There’s no infra, framework or deployment nightmares. It’s a new paradigm in software delivery. As a startup, the Dark team is constantly…

By: Deirdre Mahon
Dark is a programming language and platform that enables building serverless backends. There’s no infra, framework or deployment nightmares. It’s a new paradigm in software delivery.
As a startup, the Dark team is constantly making decisions about where to invest in improvements to support customer needs. With Honeycomb, they can observe user behavior and make business decisions based on meaningful data.
A Need for Clarity
Early on the engineering team relied on logs to understand how users interacted with their platform. However the desire to achieve better visualization compared to Stackdriver, in addition to getting a deep understanding of timing and workflow through the platform, drove the team to observability-driven development and the adoption of Honeycomb.
“Through this journey from unstructured to structured logs and now observability, I’ve enjoyed being able to run richer queries. I don’t always know what I’ll want later on but as we instrument, get it into Honeycomb, we know that we’ll figure out what’s useful.”
Ian Smith, Engineer, Dark
The Dark team added distributed tracing, which has been really helpful in understanding overall performance as well as traffic changes across different pieces of infrastructure. The team can now identify the highest impact areas to conduct ongoing performance tuning in order to improve their user’s experience.
“We can now pack as much contextual event information into Honeycomb and this has been tremendously helpful. We’ve seen a big noticeable improvement with that. With Stackdriver, we were restricted by having a logline be a certain length with further limitations around readability. We now have something that is more query-time dependent.”
Ian Smith
The Dark team needed to run rich queries & interactive visualization in order to introspect and understand how users experience Dark’s platform. They wanted to proactively investigate behavior after performance tuning using tracing, as well as to continuously improve deploy times by tracking Honeycomb markers. Finally, they leaned on boards and team query history to allow different team-members to collectively debug when alerted.
Honeycomb at Dark
Initially, the team was able to get early insights with minimal instrumentation work. Over time the team added more instrumentation incrementally.
“The Nginx processor feeding data into Honeycomb got us there. We get a lot of bang with this from very little instrumentation.”
Ian Smith
As a small but growing team, the engineers instrumenting code are also on call, which provides a crucial feedback loop. The team made it a goal for engineers to become proficient with Honeycomb, and now sharing query results and boards is second nature.
“I find it really useful when colleagues share links and I can see the query they wrote. I may look at an interesting BubbleUp heatmap and I not only want to confirm what they saw but now I have an example to work with and build upon, which makes learning how to use Honeycomb more efficient.”
Ian Smith
Instrumentation as documentation
Since the team has invested in instrumenting their code, they can lean on that instrumentation itself as a learning and debugging tool. Instrumentation is a form of documentation that doesn’t just live close to the code, it is the code.
Today when the team knows they have a particular question, they search their git logs for the instrumentation they added as well as any historical issues, and then they can easily find that data in Honeycomb.
As part of the transition from Stackdriver to Honeycomb, the Dark team invested not just in instrumentation but in optimizing their use of the tool. When the team isn’t busy writing code and tuning for performance, they are working towards building additional Honeycomb boards with the belief that becoming proficient during slower times will pay dividends during more stressful times.
Use-case: System Optimization
Dark has been able to use Honeycomb to identify performance issues and validate improvements as they roll out.
One example of this was when the team made a change in data loading for a particular high traffic end-point and Honeycomb told the team that not only was this endpoint significant in terms of number of hits (COUNT) but was also significant in the total load on Dark’s system (SUM(request_time)), showing that it took up more compute time than anything else.
Since the team had that insight up front, they could prioritize this optimization work because even though each individual request is small, the SUM() of those requests is large.
The marker on the left of the histogram shows when the optimization shipped, followed by a decline as the deploy rolled out showing a clear reduction in system impact right after the roll-out (yay!). This type of visualization is great for Dark’s end-of-week retro when learnings are shared by all team-members.
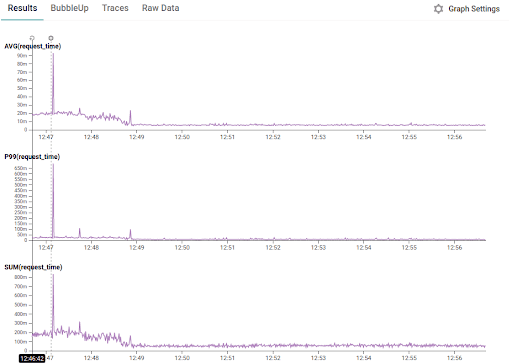
The query details for this result set are as follows:

Getting a Clear Picture of User Adoption
In order to more clearly understand customer usage patterns, the engineering team created Honeycomb boards for Dark’s CEO Ellen Chisa.
“Early on I relied on Honeycomb to understand relative traffic between different users. Honeycomb tells me how much bigger a particular user is and how much of our load we are experiencing from a business viewpoint.”
Ellen Chisa, CEO, Dark
The team knows who is active in Dark, when they are building something versus when they see real-world traffic to their own app as they become active and begin to scale.
The team uses Rollbar for error reporting and collective triage. Rollbar code spits out a log which is also now in Honeycomb that allows engineers to correlate Rollbar and Honeycomb data and see users affected by an issue. With Honeycomb’s operational boards, Ellen and other customer-facing team members see exactly which users and projects are underway.
This insight has been tremendously valuable because it allowed them to delay deploying a full-blown business analytics platform by an entire year. Heap is now used by those teams for ongoing customer insights, but Honeycomb boards continue to add value when a customer is experiencing an issue that requires immediate attention.
“The big benefit is it pushed out building a full-blown business analytics system a year later than we needed to.”
Ellen Chisa
“I see users and their projects. We didn’t know what their project was without Honeycomb. If I find out about an incident where something was broken in the last two hours, I can see exactly who was impacted by that particular incident. It helps us get ahead of issues.”
Ellen Chisa
What’s next for Dark & Observability
As the team becomes proficient building boards and getting comfortable when not on-call, the plan is to continue expanding tracing capabilities.
“Moving to traces doesn’t remove my ability to do event based queries. When I send a span, I don’t need to query on the whole trace. I can just get that span and I don’t lose any aspect of my logging.”
Ian Smith
Exploring different schemas is another step the team would like to take, especially with the 60-day data retention policy included with every Honeycomb account. Dark’s platform has standard context fields from one event to the next such as request path, timestamp, and path normalization. For other data that’s inconsistent, the team would like to say “here are the top 10 schemas in our events and these are the ones I get from my web framework, database and other parts of the system.”
Having visibility across a single trace view would be ideal. The team wants to look at condensing columns and by coalescing schemas, get a clear picture of what’s happening across their entire data set. With a 60 day look-back, they can start to see trends and patterns that will help with post-incident retrospectives.
The result has been that Dark has turned off Stackdriver in favor of Honeycomb. Besides Pingdom for monitoring some endpoints, the team relies on Honeycomb for pretty much everything.
“Being a small team, adding more tooling means losing an engineer for a period of time. Right now that’s not a useful thing for us and we don’t feel the pressure to do so.”
Ian Smith
Download the Dark Case Study today.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.