Notes from Observability Roundtables
The Velocity conference happened recently, and as part of it we (Honeycomb) hosted a sort of reverse-panel discussion, where you talked, and we listened. You may be aware that we’re in the process of…

By: Rachel Perkins

The Velocity conference happened recently, and as part of it we (Honeycomb) hosted a sort of reverse-panel discussion, where you talked, and we listened. You may be aware that we’re in the process of developing a maturity model for the practice of observability–and we’re taking every opportunity we have to ask questions and get feedback from those of you who are somewhere along the path.
In case you weren’t aware, it’s no longer plausible to rely solely on aggregate metrics and dashboards designed to highlight the problems of the past. The complexity of today’s production environments combined with the speed at which an org must ship code to maintain customer satisfaction means engineers need the ability to quickly and easily explore, dig in deeply to find the individual events contributing to an issue, and share that knowledge across the team. These teams need the power to ask new questions of their data without having to ship new code–they need observability.
As the industry evolves, organizations are realizing that in addition to their need for observability when shipping software and running modern infrastructures in production, access to observability and the cultural shift it represents also provides the groundwork for enabling happier developers as well as happy customers.
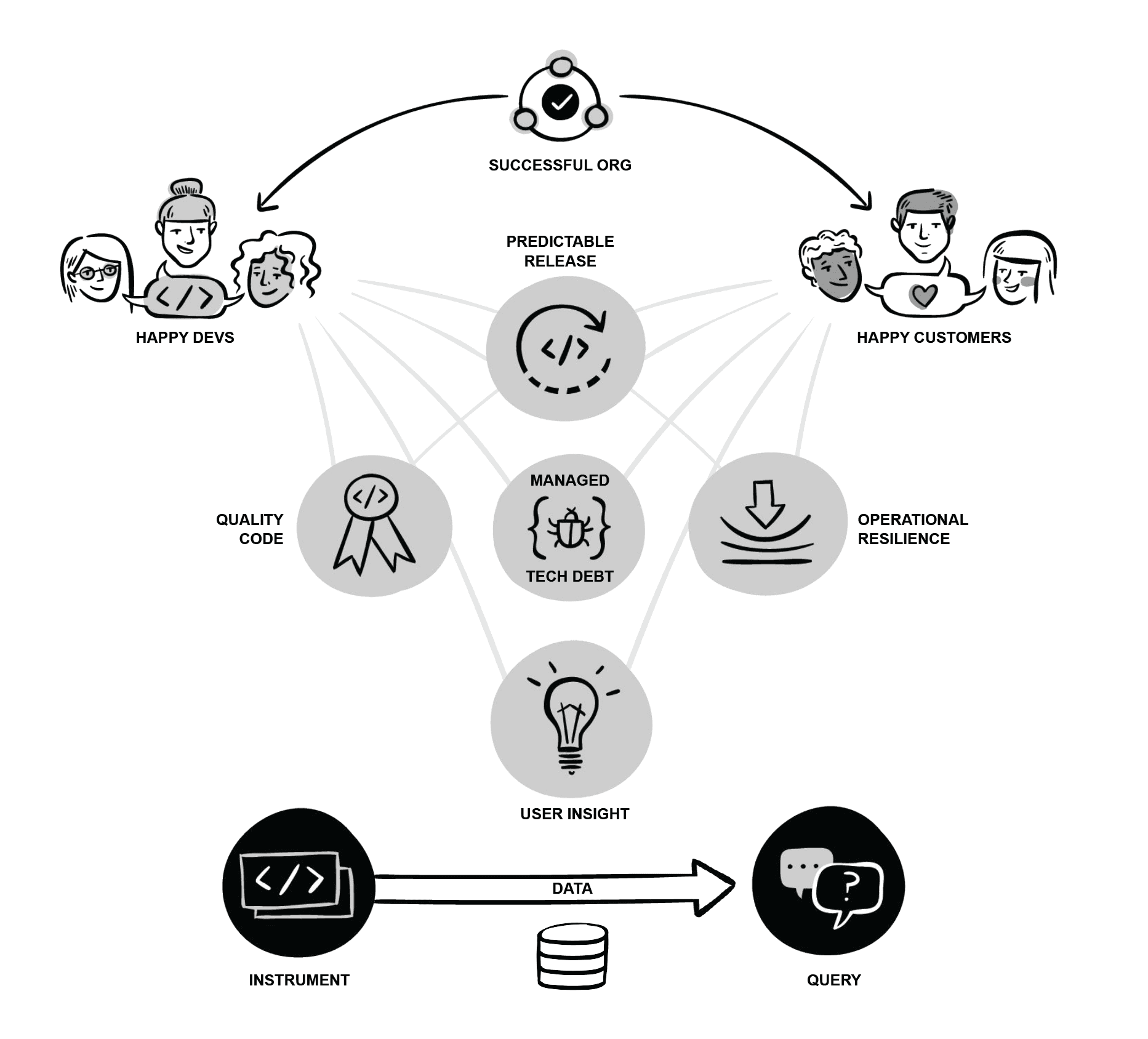
But how to get to there from…wherever you are right now? We’re hoping to answer that question with the Maturity Model for Observability that we’re working on–and as I said earlier, the first step is to ask questions and get feedback–to find out where orgs are with their observability practice, where they are experiencing challenges, and where they need guidance.
So–we listened. And some themes emerged. Here are a handful that caught my eye:
Understanding the business goals isn’t just for product managers and marketing people
The code you run in production is literally the manifestation of your company’s business goals, mitigated by your architecture choices. If the people writing the code don’t have a clear view of what your customer is supposed to experience, outcomes will be suboptimal. In particular, observability relies on thorough, thoughtful instrumentation with events and traces that reflect what matters to the business–which can’t happen unless those instrumenting the code know what those things are.
Unchecked technical debt means you can’t hire junior engineers
If your organization is mired in technical debt, a lot of bad things happen. Some of the more obvious ones: your shipping velocity slows, your outages/incidents increase, your uptime decreases, etc. But it can also mean your engineers fear making changes to the code because they don’t know what else might break. As legacy code and infrastructure become more fragile and inflexible, fewer members of the team can confidently handle an oncall rotation, let alone explain to a new team member what to pay attention to and what you can safely ignore. Over time, it will take more, and more senior engineers to support a given service.
A particularly interesting note: outdated processes can also count as technical debt.
The future of observability is not AI, it’s enhancing human abilities
The human ability to explore, pattern-match, and generate new theories still vastly outstrips that of any ML/AI solution on the market or in research today. Trying to use ML/AI to achieve observability on their own is like relying on dashboards you made in response to an incident that happened yesterday to show you the problems of today–to solve the proliferation of new problems facing engineering teams every day, it’s more useful to support human troubleshooting processes by automating away repetitive calculations–as one of the members of our discussion groups said, “take humans out of being the API for the system.”
Where we’ve been and where we’re going
As we begin the process of gathering statistically significant data around the observability journey, we’re working based on a framework we’ve developed. You can download the Framework for an Observability Model and find an HTML version here. We recently hosted a webcast discussion as well, click through to review it.

In the coming weeks, we’ll be developing and distributing a survey to inform a more formal report and publication–keep your eyes open for your invitation 🙂
Until then, find out what observability can do for you with no strings attached: check out Honeycomb Play.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.