The Fast Path to More Useful Telemetry


Honeycomb & OpenTelemetry for in-depth observability
Learn MoreOver and over, we’ve seen that teams who invest in adding rich, relevant context to their telemetry end up debugging faster and collaborating more effectively during incidents. Getting meaningful context added can feel like a big cross-team project, but some of the highest-leverage improvements don’t require app code changes or coordination across services.
In this post, we’ll focus on steps you can take that give you a lot of benefit with low effort, by leveraging CI/CD systems, resource attributes, and a bit of standardization.
Use resource attributes
With OpenTelemetry resource attributes, you can use environment variables to define attributes that will be available on every event sent to Honeycomb. The different language auto-instrumentation libraries typically already have “resource detectors,” which automatically capture information. For example, the NodeJS Opentelemetry resource detector for AWS captures things like cloud.region or cloud.availability_zone, which in turn allow you to slice your data as needed during an incident.
In a similar vein, ask yourself this question: “Are there any attributes that don’t change with the application code itself, but would be useful to have on every span?”
By using resource attributes, you can provide critical context to make decisions without any application code change. Here are a few examples:
service.tierif you have the concept of a tier for your servicesservice.teamto instantly know which team owns the spans being debuggedservice.slack_channelto know how to reach the team in question
Many teams already capture some of this metadata in manifest-type files that live with application or infrastructure code. Or perhaps this information is available in environment variables during your build pipelines. Either way, you could add a build step that converts these to a comma-separated list in the environment variable OTEL_RESOURCE_ATTRIBUTES.
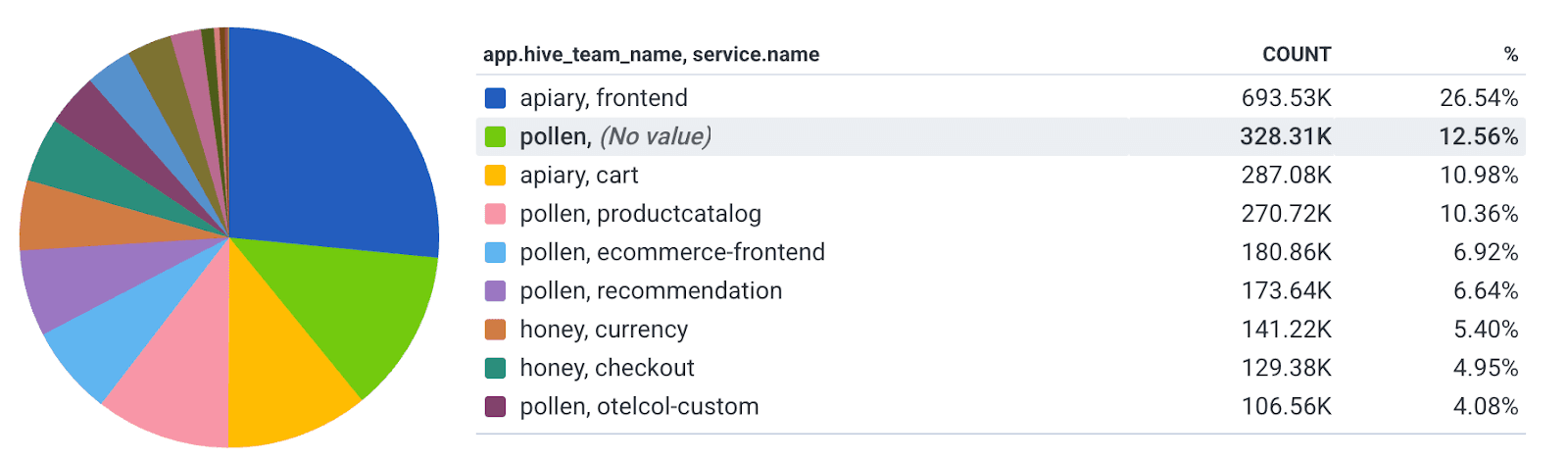
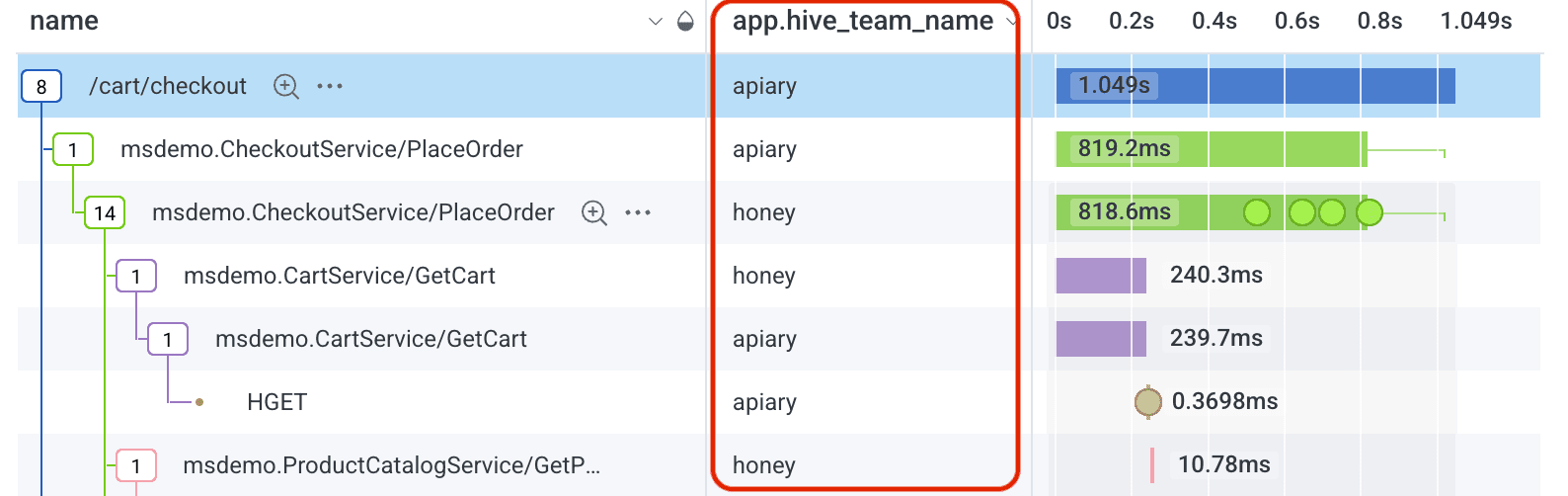
Now, anyone navigating a trace or querying can easily know which team to contact if there’s an issue. What other critical information could you add to your telemetry like this?
Leverage your CI/CD platforms
Correlating your build and deployment information with telemetry is essential to getting to root causes. Leveraging existing information from build systems is one of the easiest quick wins you can give users of your observability platform, because any regressions introduced by code changes will benefit from that context in order to be fixed.
Most CI/CD platforms will offer a set of default environment variables available in every runtime environment. For example, by checking the GitHub Actions documentation, we can find a lot of information that would be really useful to find attached to spans:
GITHUB_REPOSITORY, so you know exactly where to go if there’s an issueGITHUB_SHA, so you know which specific code is runningGITHUB_JOB, so you can even go back to the job that ran it- etc.
Using resource attributes makes it trivial to add these attributes to every span. If every service is consistently doing this with their deployments, no one in your organization will ever have to wonder where to go if there’s an issue.
Another simple change you can make to your build pipelines is to add markers that represent a deployment in the UI. This makes it very easy to correlate what you’re seeing in your Honeycomb queries with deployment events. Adding this is as simple as adding an API call or CLI command as a build step in deployment pipelines.
Create abstractions and/or a centralized library
If your organization is large enough, you’ll eventually run into the issue of too many attributes without a clear naming convention, or missing the right attribute or span in the right place. Imagine trying to debug an issue for a specific customer, but in one service you’re using customer_id as the attribute, and in another you’re using customerId. That’s unnecessary time lost in an incident, and this telemetry drift is incredibly common and easy to fall into.
For this reason, we highly recommend that a team taking care of observability build some abstractions to make it easy to do the right thing. Depending on the language you’re using, you’ll have different options available to you, but the general idea of this is to do things like:
- Making sure important information, like version, team names, etc. are present in attributes
- Making sure any custom attribute created is under the right prefix
- Enforcing naming conventions and other best practices
In this example repo, I created some of these abstractions in a TypeScript project:
- Creates a middleware to make it easy to capture attributes in the root span for that service, similar to what Jeremy Morrell recommends in his A Practitioner’s Guide to Wide Events
- Creates abstraction functions for attributes, to make sure they are prefixed consistently and camel cased
- Leverages a compiler to automatically wrap function calls (experimental)
The result is a much more context-rich trace in Honeycomb that has spans for each function call, naming conventions for attributes and hoisted attributes to the root span, with almost no code changes:

A lot of the examples in this repo could be extracted into a library that can be reused by different teams in your company. This means you can enforce telemetry standards across your organization, and any change to that is automatically rolled out to everyone.
Be intentional to review practices during incidents
Incidents can often be a stressful time, but they are also excellent learning opportunities. Not only can you learn about the places in your system that are more likely to fail (and therefore may require better observability), but you also get to understand the steps taken by engineers in getting to the root cause, as well as the time it takes to debug and solve issues.
Most organizations should have an incident review process to potentially generate a root cause analysis document. As part of that, we highly encourage you to actively think about what is and isn’t working well when it comes to observability. For example, you can add a small step in that process to ask those involved a few targeted questions:
- How many different tools did you have to use to find the issue?
- What pieces of data (e.g., spans, attributes in spans) were important in finding the root cause?
- Were there any gaps in the available data that you noticed (e.g., missing business context, versioning, etc.)?
A centralized team (e.g., a dedicated platform team, or a team of champions) should then review these periodically to find patterns or easy wins, making sure that a roadmap for telemetry is in place and in line with what users actually need.
Send more, get more
To get the most out of any telemetry tool, you need context. While it’s extremely valuable to add deep business context from within your application code, there is so much you can already get with very little effort. Be intentional about getting these in place early, and you’ll find that other users will also start wondering about what other attributes they can add to make their lives easier.
New to Honeycomb? Get your free account today.
Get access to distributed tracing, BubbleUp, triggers, and more.
Up to 20 million events per month included.