Bitten by a Kafka Bug – Postmortem
Dearest honeycombers, Yesterday, on Tuesday, Oct 17th, we experienced a partial service outage for some customers, and a small amount of data was dropped during ingestion (not any previously stored data). In terms of…

By: Charity Majors
Dearest honeycombers,
Yesterday, on Tuesday, Oct 17th, we experienced a partial service outage for some customers, and a small amount of data was dropped during ingestion (not any previously stored data).
In terms of impact, 33% of users actively sending data during the incident window experienced partial loss of writes between 6:03 AM and 10:45 AM PDT. Of those, most lost less than half of their writes. In addition to this, a majority of users experienced a 30 minute period of partial read availability between 10:50 and 11:20 AM PDT.
The type of outage we experienced was a new one for this team. But it was also a particularly constructive outage, because it helped several members of team level up substantially on their kafka knowledge and their mental model of how to recover from any operationally degraded kafka scenario.
We use Honeycomb (in a wholly separate environment) to understand and debug the Honeycomb that serves our customers, so we figured we would walk you through what happened and how we debugged it.
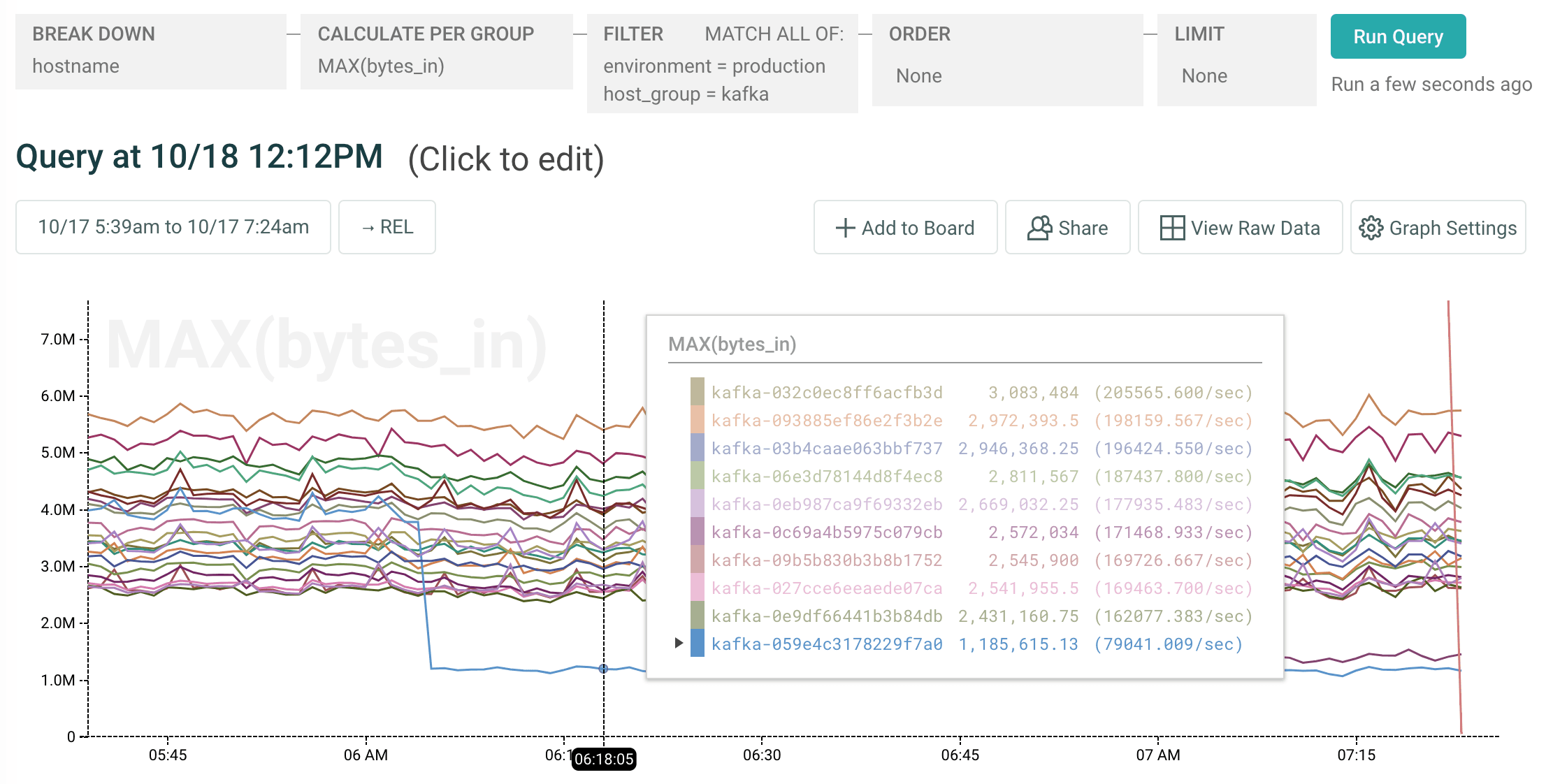
At 6:15 am, PagerDuty started alerting that our end-to-end production checks were failing on a few partitions. But data and storage nodes all seemed healthy, so we checked kafka. As you can see, one of the kafka nodes had effectively no network traffic flowing into it.
Below, a graph showing inbound network traffic sharply decreasing for a suspect kafka node:
We checked kafka output, and sure enough, that node was marked as ISR for the partitions (5, 6, 32, 33) that corresponded to the alerting data nodes. At 7:07 we noticed that the “bad” brokers didn’t recognize any of the other brokers as part of their clusters, while the “good” brokers thought all brokers were healthy and all partitions had offsets that were increasing (except for 5, 6, 32, 33).
Below, a graph tracking our end-to-end successes and failures. dataset values here map to individual Kafka partitions, so we had a clear picture of the ongoing failures as we tried to resolve the issue:

We tried bringing up a new kafka node, but it didn’t know about any of the “good” brokers… only the “bad” brokers. We tried restarting a node or two, while carefully preserving the balance of replicas and leaving all partitions with a quorum… which turned out to be important, because after a restart, the nodes were only aware of the “bad” brokers.
Much debugging and googling of error messages ensued, with several red herrings, including some flights down zookeeper paths of fancy that were ultimately useless.
Eventually we realized we had a split brain between the nodes that had been restarted (not serving traffic, could see each other) and the ones that had not (were serving traffic, could not see restarted nodes). And at 9:37, we found a jira ticket that was three years old but sounded very familiar. We realize that the “bad” brokers were actually good ones, and the good ones were actually bad. We needed to do a rolling restart of the entire world.
After restarting all kafka nodes (which we did with perhaps too much caution and care… it was a first time for the engineers working the outage), it turned out that the data nodes had an offset far ahead of the acknowledged offset, because kafka had kept accepting writes even though zookeeper didn’t acknowledge them as being part of the world.
So we had to manually reset the offset on the data nodes and restart or bootstrap them as well. By 12:03pm the world was restored to order.
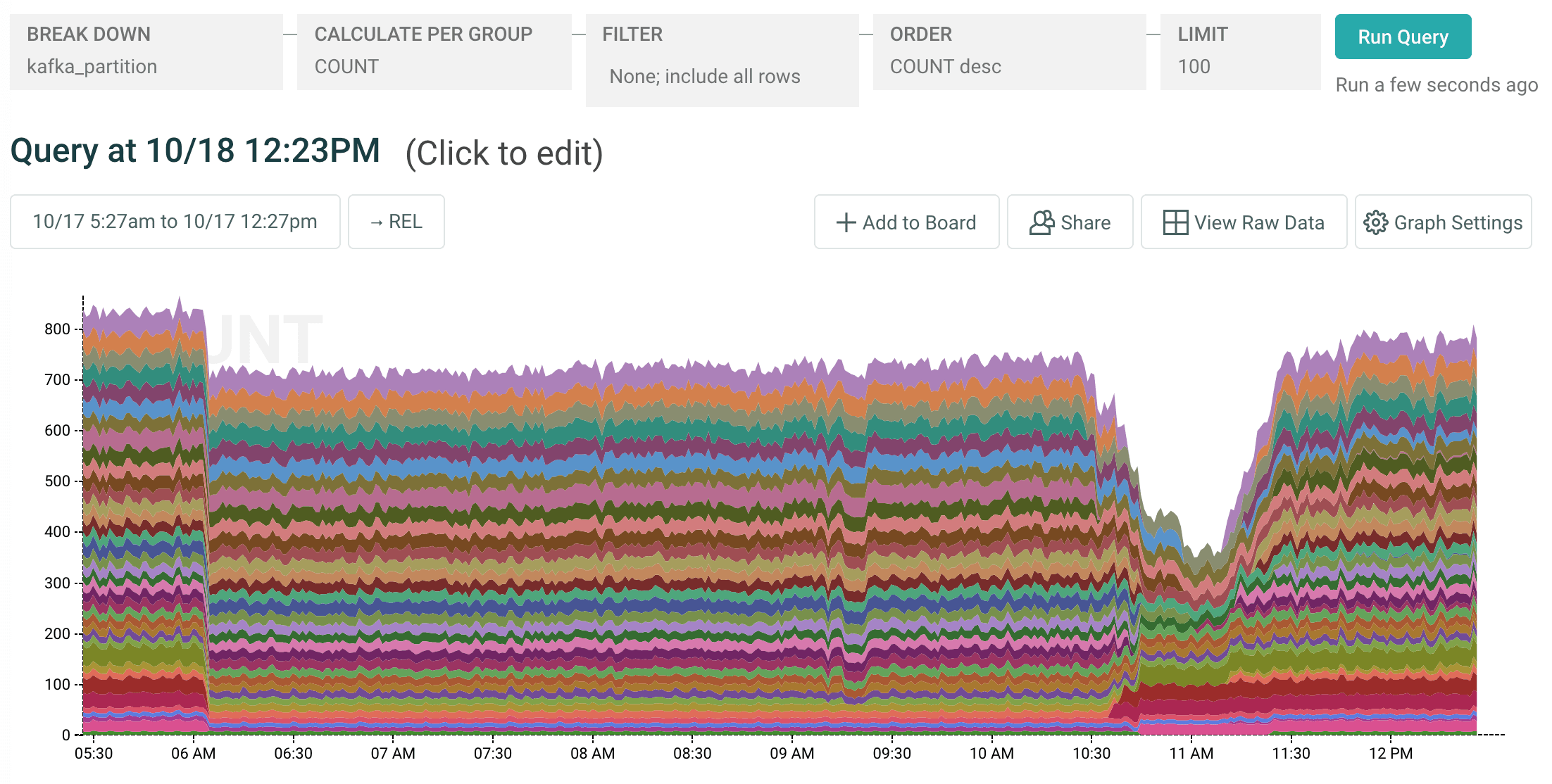
Below, a stacked graph showing successful writes to our storage nodes broken down by kafka partition. You can see the initial drop shortly after 6am of those 4 failing partitions, some blips around 9:15am as our engineers tried restarting the thought-were-bad-but-actually-good brokers, and some broader ingest problems between 10:45-11:20 as we restarted the world:
What we learned
Well… we learned a LOT. Frankly, I’m really happy that so much of our team got to experience their first big kafka incident, and leveled up commensurately at their kafka skills. I think the entire team now has a much broader skill set and richer mental model for how kafka really works. In some ways this was inevitable, and it’s a relief that it happened sooner rather than later.
In retrospect, the incident was actually seeded last night when our zookeeper cluster experienced a network partition. We just didn’t know about it until the controller thread did Something™ around 6 am, which caused it to finally be symptomatic.
This is apparently all due to a number of issues that have been fixed by kafka 0.10.2.1, so we need to upgrade our cluster ASAP. Other action items on our plates are:
- Get better instrumentation for kafka and zookeeper into honeycomb
- Get the retriever kafka partition into ec2 instance tags, write shell functions for printing retriever/partition mappings
- Instrumentation for failed writes to kafka (consume sarama response queue?)
- Change the way data nodes handle invariants, to avoid manual intervention when it has with a kafka offset ahead of the broker’s
- Document the bash snippets, command lines, and other bits we used to debug retriever and kafka and create a production runbook for them
We apologize for the outage, and to the customers who were affected. We know you rely on us, and we take that very seriously.
We were heartened to see all the traffic going to our status.honeycomb.io page, and thought it was lovely that our customers were watching our shiny new status page instead of pinging us on intercom to ask what’s up. We have wonderful customers. 🙂
Thanks for hanging in there. Til next time,
the honeybees.
P.S. A huge thanks to John Moore of Eventador for helping confirm some of our suspicions, providing pointers to known kafka issues, and suggesting fixes along the way.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.