The Case for SLOs
With one key practice, it’s possible to help your engineers sleep more, reduce friction between engineering and management, and simplify your monitoring to save money. No, really. We’re here to make the case that setting service level objectives (SLOs) is the game changer your team has been looking for.

With one key practice, it’s possible to help your engineers sleep more, reduce friction between engineering and management, and simplify your monitoring to save money. No, really. We’re here to make the case that setting service level objectives (SLOs) is the game changer your team has been looking for.
What is an SLO? A part of the “service level” family, an SLO is a reliability target (for example, “99%”) driven by an SLI (which is a metric like “requests completed without error”) that organizations use to ensure user experiences are smooth and customer contracts are being met. An alert based on an SLO might tell us of an impending performance problem, degraded user journey, or delayed workflow. They can be internal or external for an organization, and can be used to judge if SLAs are being met with hard data. Finally, SLOs can help answer the question so often asked from other business units to engineering: “are we up, and how do we know?”
But SLOs aren’t just drop-in replacements for traditional alerting, and engineers and the business side don’t have too much shared language or tools to talk about reliability together. If teams create too many SLOs merely to replace their existing alerting or set targets that are aspirational instead of realistic, nobody will reap the benefits.
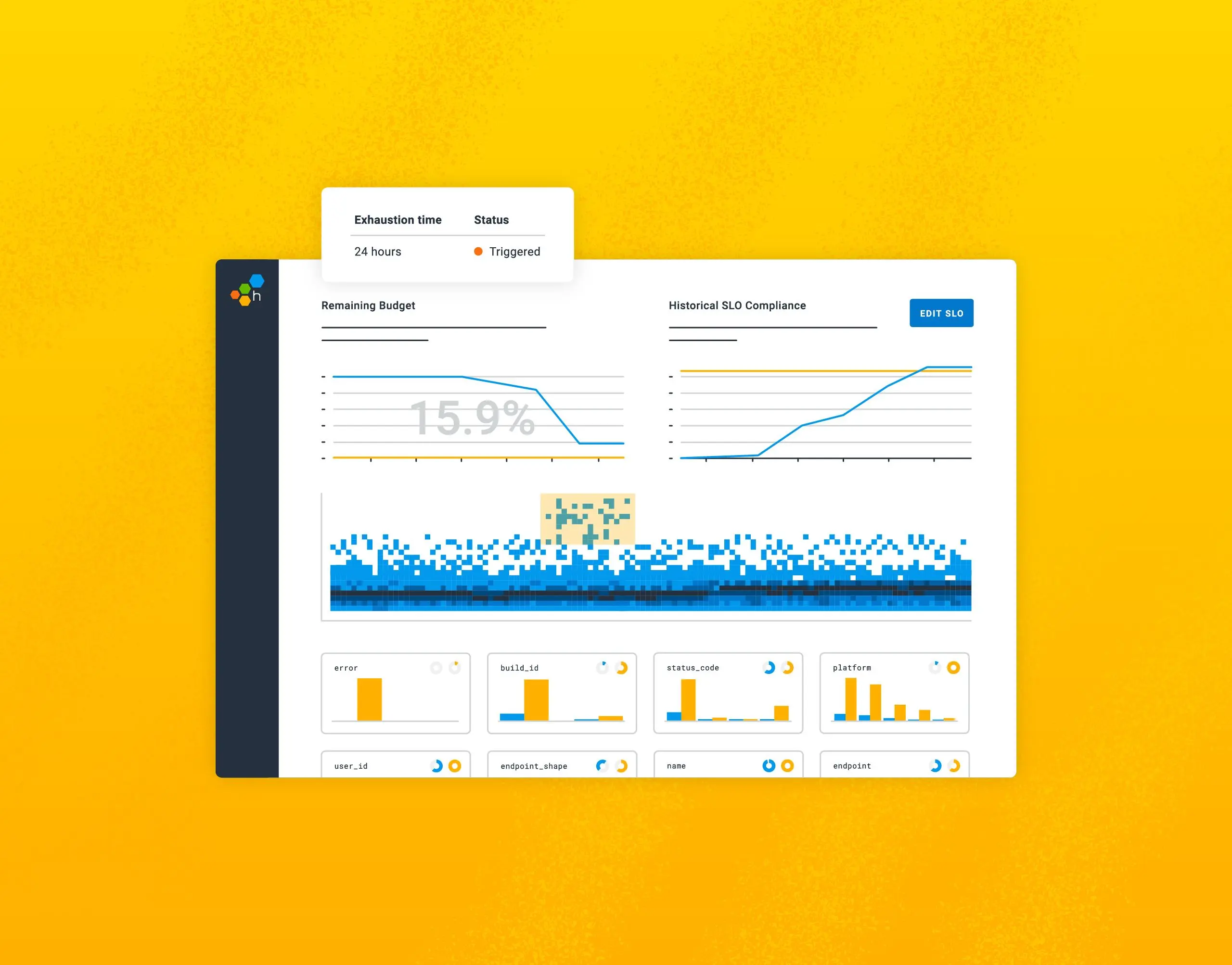
If SLOs are created thoughtfully, tied to key business metrics or user experiences and based on data points that matter, they can be more powerful than traditional monitoring. And we should know: monitoring missed a partial degradation we experienced at Honeycomb, but our SLOs made it clear we (and our customers) were indeed having a problem.
Here’s our best advice for how to set your team up for success with SLOs.
Make it a service level… minimum
It’s key to remember that whatever SLOs are decided upon, they’re performance minimums, not maximums. Don’t overcomplicate it: SLOs should reflect the minimum level of service needed to stay compliant and meet SLAs (or to ensure a healthy user experience).
Get everyone aligned
One reason SLOs can get a bad rap is because they can be vague, difficult to understand, and potentially measure things that don’t actually matter to customers. So it’s key to get everyone—developers, SREs, platform engineers, and even the business side—to discuss the user journeys that matter, decide whether SLOs should tie directly to SLAs or just be an “early warning” system, and pick what SLIs (metrics—like HTTP requests to a load balancer, or traces from the application) are best.
Narrow it down, make it make sense
Teams getting started with SLOs should be careful not to SLO all the things. Less is more here, so make sure to choose wisely.
One way to give an SLO a reality check or makeover is to ask the following questions:
- Is it meaningful? If so, does it warn us ahead of time or only after our customers are angry?
- Is it measurable? Can we express this in clear language with common-sense metrics?
- Is it possible? Do we know that 6 “nines” means 31.6 seconds of downtime a year?
- Once an SLO alert is tripped, will teams be able to take action?
- Should it wake somebody up, or just be a warning signal?
Here’s our general recommendation: set one SLO for each user journey and have it targeted on errors and timing. For example: over the last 30 days, 99% of legitimate sign-up attempts will succeed within one second.
Embrace the business benefits
Software development doesn’t exist in a vacuum, and there needs to be dialogue and alignment between product-focused teams, platform/DevOps/SRE teams, and the organization as a whole. Teams should have clear charters, understand the organization’s KPIs (key performance indicators), and feel confident they know how they contribute to them.
Done right, SLOs provide that ideal information “bridge” that can help both engineering and the business side—SLOs provide a shared language and tools to understand product performance. A co-created SLO alert can be dual purpose: the business side gets an early heads up about a potential performance risk at the same time an engineer is getting pinged. The SLO ensures both sides are in sync when it comes to incident resolution, cost, and risks to compliance and reputation, all without time-wasting explanations. Both sides are invested and have ownership, all thanks to a humble SLO.
For supercharged SLOs, add observability
If you want to give the humble SLO an upgrade (and bonus, reduce alert fatigue, have happier developers, and maybe even world peace), tie it to observability and watch the magic happen.
Obviously we’re biased but we think SLOs + observability is the ultimate combination for the fastest incident resolution. Observability gives SLOs access to a wide variety of data, the ability to ask new questions without adding instrumentation, and leaves past biases about previous incidents behind. Base an SLO on wide structured event data and the on-call engineer will have more tools to resolve an issue expeditiously—not to mention the benefits of fewer alerts overall.
We love SLOs, and you will too. Learn more about how Honeycomb can help modernize your alerts.
More on SLOs:
- SLOs explained in this video
- Build a simple SLO
- Set business goals with SLOs
This post was written by Valerie Silverthorne.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.