Detect and debug customer experience issues early with SLOs
Catch critical customer experience impacting issues sooner and reduce alert fatigue with the most actionable Service Level Objective (SLOs).

Why you’ll love Honeycomb
All the context you need to debug
See trends of how your service is performing alongside all the underlying data needed to debug issues.
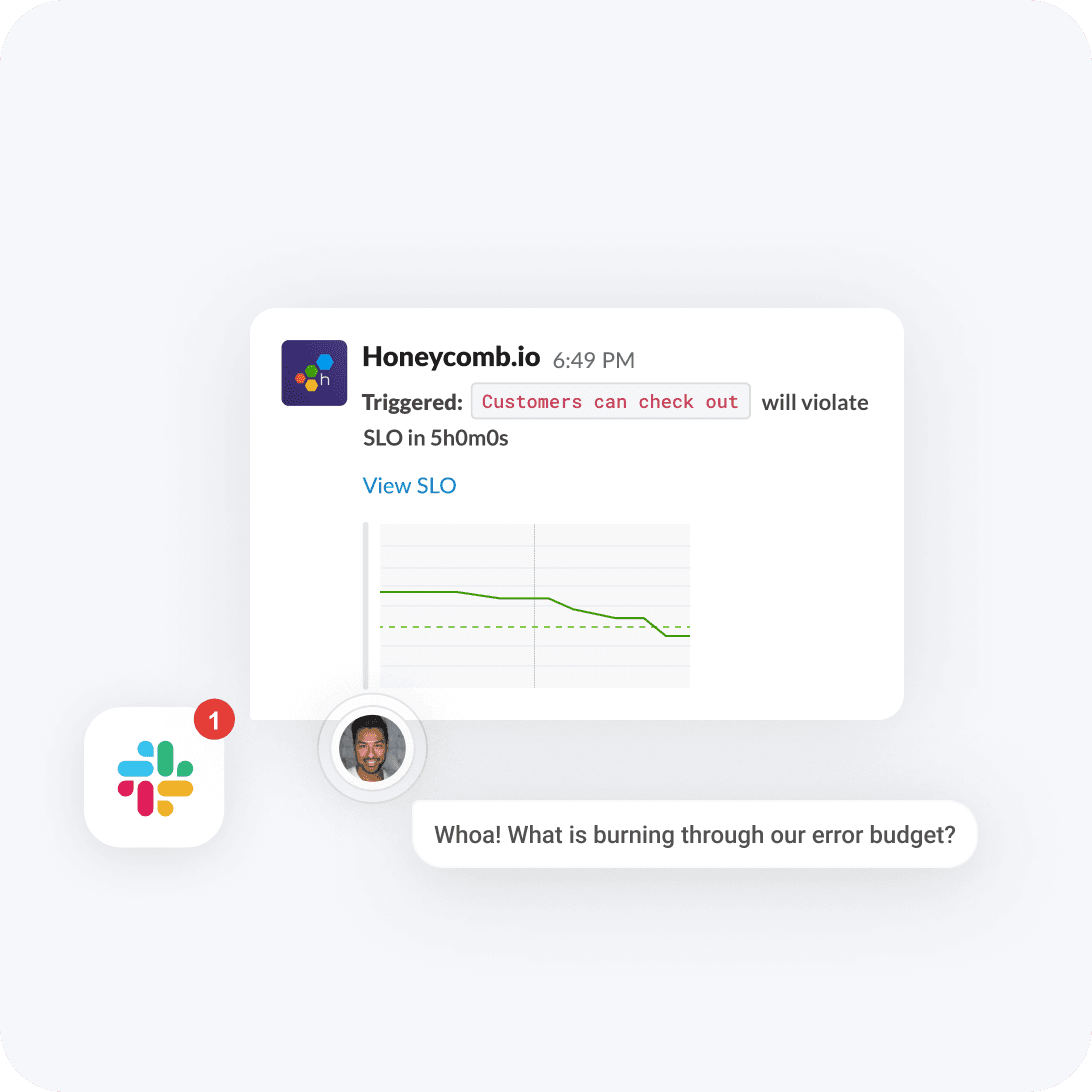
Get the alerts that matter
Prevent alert fatigue and resolve issues proactively with notifications that give you the time and context needed to avoid disruptions.
Make the right business decisions
Create SLOs that reflect your critical customer experiences. Teams have the clarity they need to prioritize issues, simplifying collaboration and reducing decision bottlenecks across teams.
Why use Honeycomb for Service Level Objectives?
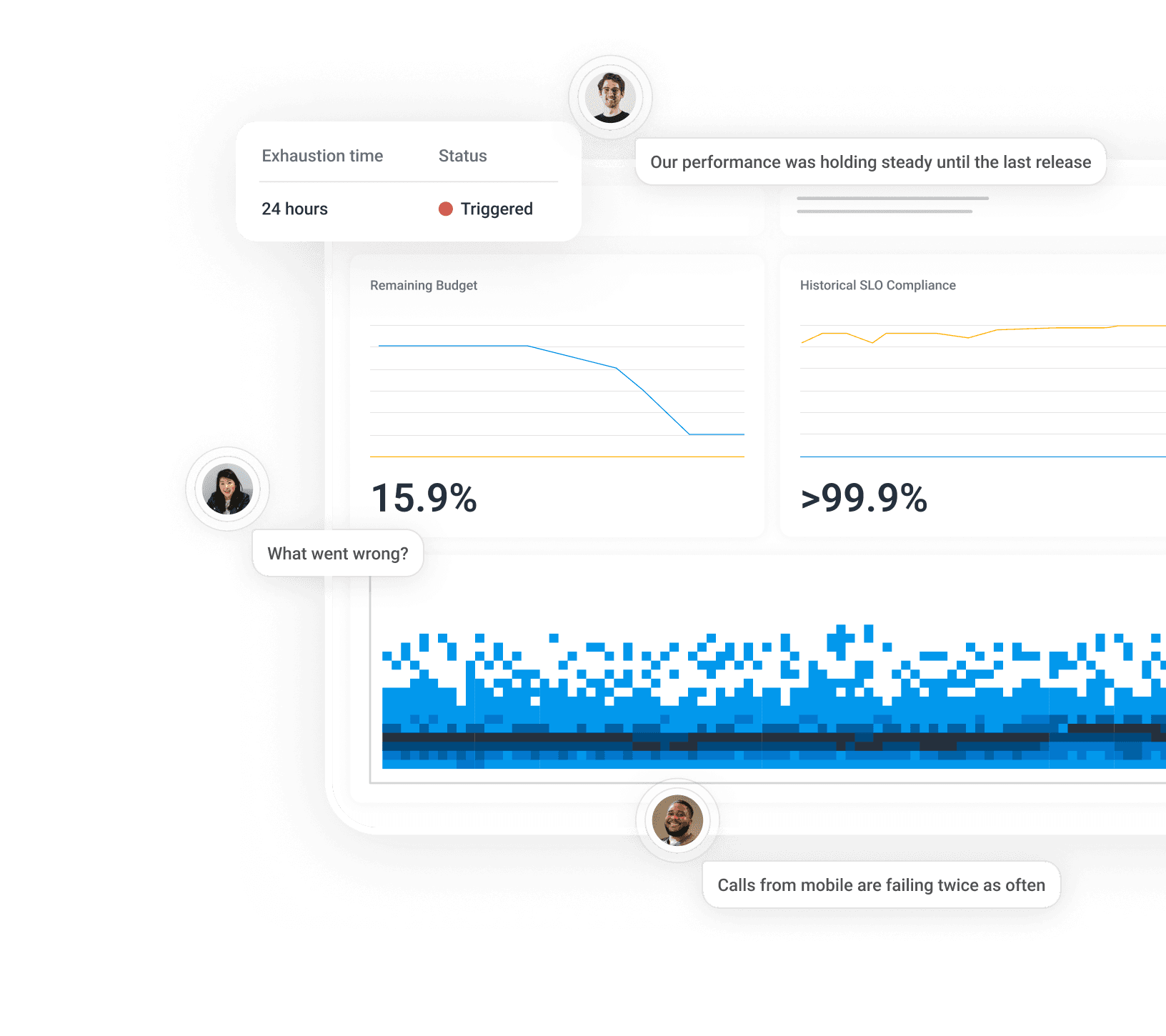
Take action faster
Honeycomb’s event-based SLOs calculate in real-time to represent your customer experiences. You can detect anomalies to correlate failures to their root causes, enabling you to see immediate impact and take action quickly. By focusing on individual customer experiences, you’re alerted to severe issues faster—before they escalate.
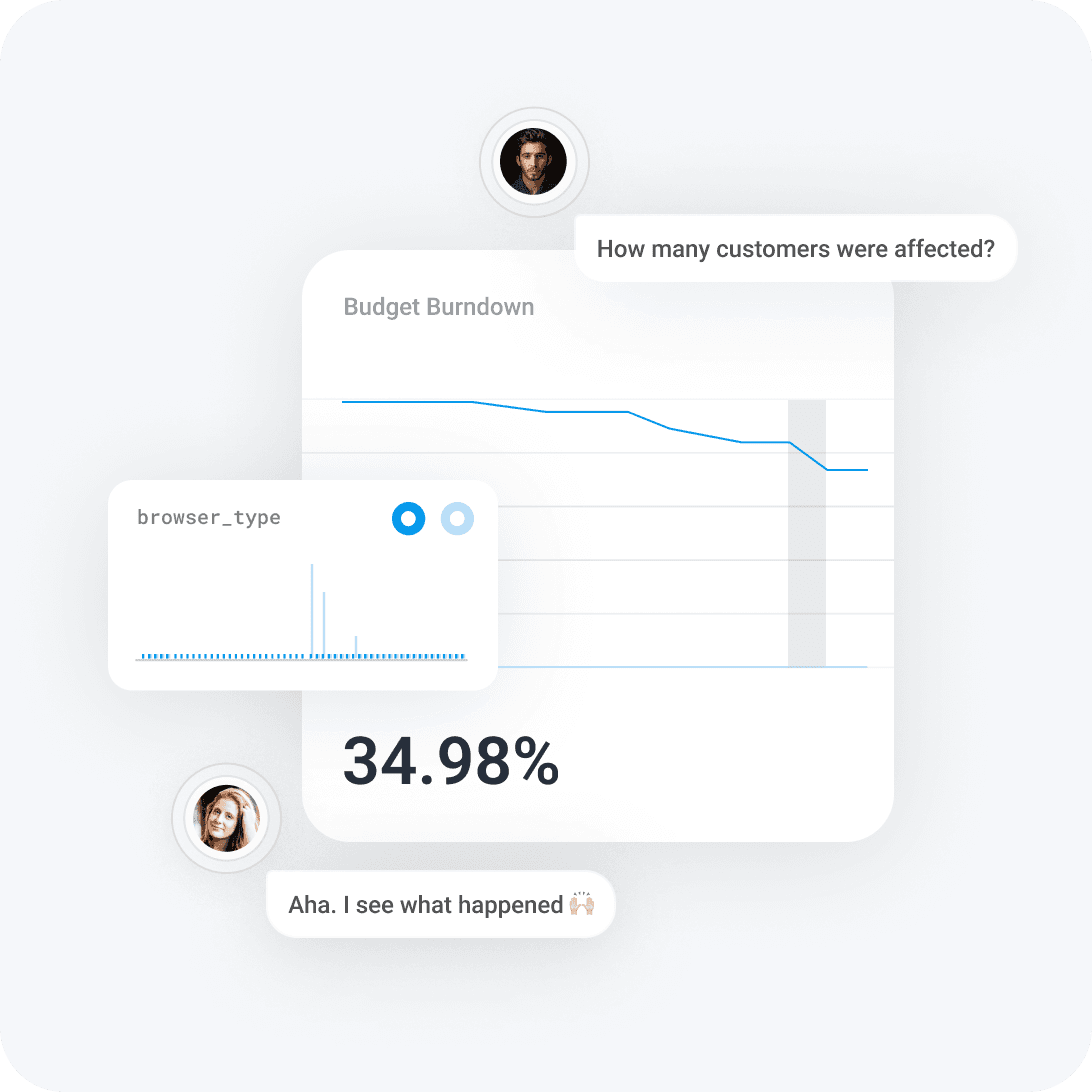
Notifications with context
Burn alerts deliver actionable notifications with full system context, integrating insights from across your environment. These alerts are seamlessly connected to your notification workflows via Slack or escalation workflows in PagerDuty, allowing teams to assess severity and impact quickly and make informed decisions.
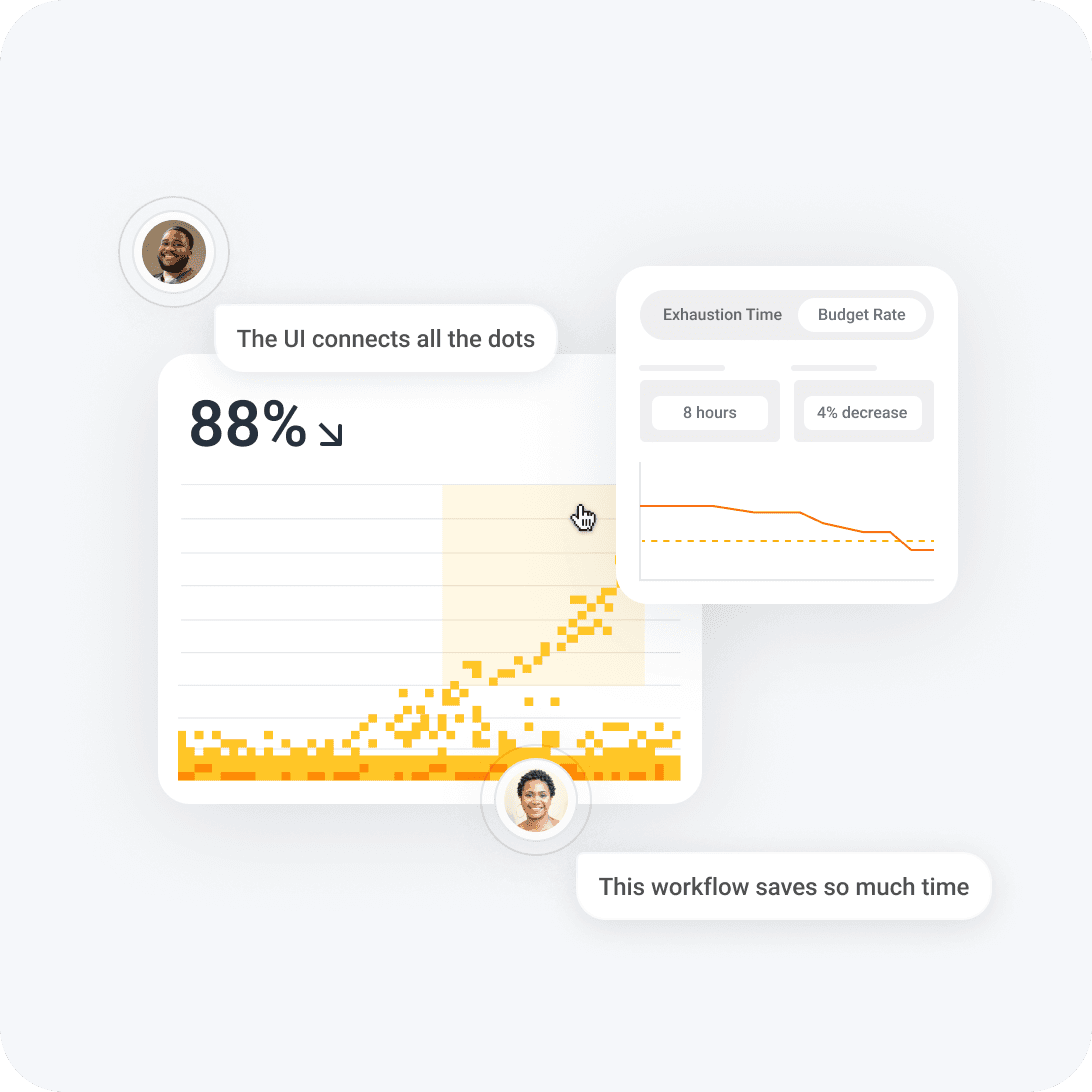
Track trends and debug in one UI
SLOs are debuggable within a single UI with all the underlying event data. Engineering teams can quickly dive in to pinpoint issues and their causes without switching tabs. Use built-in anomaly detection with BubbleUp to show suspicious performance bottlenecks on a heatmap and expose patterns.
Continuous improvement
Iterate on and continuously improve the health of your services by integrating SLOs into dynamic boards. With real-time visibility into your services’ performance, you can align engineering efforts with business priorities, ensuring your team stays focused on improvement without losing sight of the bigger picture.
The Engineer’s Guide to Service Level Objectives (SLOs)
Imagine a world where engineers get more sleep, friction between engineering and management decreases, and your monitoring processes become more efficient and cost-effective. Sounds too good to be true, right? Well, it’s possible with Service Level Objectives (SLOs). Getting started involves a bit more research than just jumping into setting targets.
- The fundamentals of SLOs
- Their benefits
- Best practices for setting them up
- How to align them with business goals

Hear from our community

SLOs become a negotiating and prioritization tool for your engineering teams… It forces discussions that, without the SLO, you wouldn’t have until a customer complained.

Introducing Honeycomb SLOs has been a gamechanger for us. They serve as a kind of contract between our product managers and engineers where we jointly define appropriate SLOs for each part of the product and agree that if an SLO isn’t met, it’s an indicator of customer impact. We then halt other work and prioritize resolving the issue.

Now when we do a deployment, we can see pretty instantly if we’ve regressed on performance and where specifically we’ve regressed. And we can decide whether to roll something back or close out the scope of work.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.