Data Availability Isn’t Observability
But it’s better than nothing… Most of the industry is racing to adopt better observability practices, and they’re discovering lots of power in being able to see and measure what their systems are doing….

By: Fred Hebert
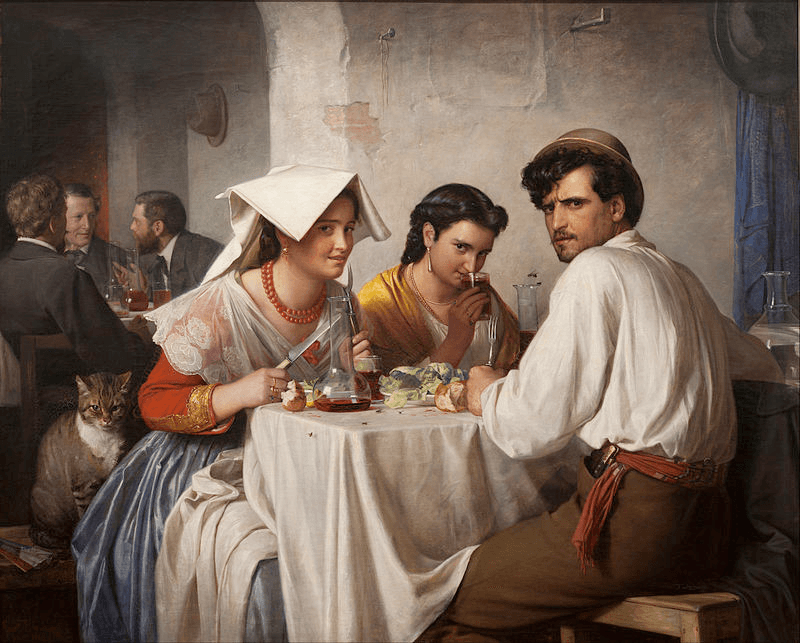
But it’s better than nothing…
Most of the industry is racing to adopt better observability practices, and they’re discovering lots of power in being able to see and measure what their systems are doing. High data availability is better than none, so for the time being, what we get is often impressive.
There’s a qualitative difference between observability and data availability, and this post aims to highlight it and orient how we structure our telemetry.
The big difference
We tend to explain observability with definitions from control theory, such as, “a measure of how well internal states of a system can be inferred from knowledge of its external outputs.” Folks in cognitive systems engineering have described observability as “feedback that provides insight into a process and the work needed to extract meaning from available data.” It sounds similar to the common definition, but it highlights that the work to extract meaning is an intrinsic part of observability, something that we software engineers tend to forget about.
For a visual example, I’ll use a painting from 1866 named “In a Roman Osteria,“ by Danish painter Carl Bloch, which I like to believe would today be titled, ”Picking a Seat Near the Sales Staff at Lunch.“ If you’ve never seen it, the effect I’m showing should have more of an impact as I’m using it to show two ways of representing the same information. Here they are:

The first one is an outline, and the second is a jigsaw puzzle version (at least all the pieces are right-side up with the correct orientation).
The jigsaw puzzle has 100% data availability. All of the information is there and you can fully reconstruct the initial painting. The outlined version has a lot less data available, but if you’ve never seen the painting before, you will get a ton more information from it in absolutely no time compared to the jigsaw, which might be critical during a high-stakes situation like a production outage.
For reference, the full picture is right here. This is a painting with plenty of details and a bunch of things going on. Once we see it, the details are obvious: We can describe the three people in front (and their disdain), the three people in the back, the cat, the couple of hats on hat racks, the food and the tables, some damaged walls with an arch, and so on.
To me, this shows the critical difference between data availability and observability, where observability caters to the work to extract meaning. Having the data available is not sufficient. Having just the outline isn’t enough to get the full picture, but it’s much better to get a decent idea of it. Effective understanding comes from being able to give additional structure to data and adding to the outline.
There are multiple ways to support that work, from being able to more rapidly sort the pieces of the jigsaw puzzle—something closer to what Honeycomb can help you do for your system—to having the data itself be closer to telling a story (as with the outline) so that we can aid mental model formation.
Aiding mental model formation
If you’ve seen the painting before and you know what to look for, data availability can be sufficient. That’s because you’ve got a mental model already built of what the image should be, and you can use it to guide and help predict what sort of information should be there and what it would look like.
With software, we have such mental models guiding how we search data based on what we know about the system—its architecture, the code organization, its prior history. A good model keeps the relevant and sheds the irrelevant, and this can change with time. When we see a pile of logs, traces, or events, we get an idea of what to look for based on how we know things are structured, even if very little of that information remains by the time you’ve sent it to a product like Honeycomb.
But what is it like for people who don’t have a mental model yet? In those cases, what people tend to do is emit events that are making sense within the context of source code and align that with all the project history that already exists in their heads. They then consult and interpret the data with that context. This is the jigsaw approach. If the events reflect the structure of the code, then you have to understand some of the code in order to understand what the events mean. Mental model formation is therefore dependent on having access to the code, reading it, and grasping its structure.
The outline approach is one that is more easily described as reflecting features or a user’s journey. Someone with a grasp of the product can reflect on your data and use it to make predictions. This helps model formation because understanding the product’s broad structure is arguably simpler than understanding its code, and you can bring all of that to the operational environment.
An example at Honeycomb
We’ve recently had discussions about this within Honeycomb. When data makes it to us, it goes through a load balancer, then through a gateway (shepherd), which pushes it onto Kafka, and it gets stored in a query-friendly format by our in-house database (retriever).
The way our service level objectives (SLOs) are defined internally tend to align with user journeys. We have SLOs for queries, ingestion, triggers, SLOs themselves, and so on. This is because SLOs should alert us when our users suffer, not just when something may be going wrong in unnoticeable ways or for such a short period of time we couldn’t act on it.
But our SLOs currently are split up less effectively than they could be. Right now, we’ve defined ingest SLOs three times over:
- Once for our event input from Beelines
- Once for OTLP endpoints
- And one time extra using load balancer metrics
Many of our endpoints are instrumented using the internal Go framework’s handler names and structures. This has many implications: If a thing in the back end goes really bad, we can be paged 3+ times for a single type of failure, which creates more noise per signal. If we change something in the implementation or rename non-public elements, we may silently break our SLOs (this happened at least once already). If you want to understand the traces and events, they presuppose understanding the underlying frameworks, servers, and architecture used to get the most out of them, which can impact debugging.
A better way to do things would be to keep the data around, but actually name the spans and events according to what they mean. Rather than having something like handler.method: /opentelemetry.proto.collector.trace.v1.TraceService/Export as the main instrumentation key, you may want something more connected to user flows such as “ingest“, with a label such as ingest.type: OTLP, and then keep the specific handler.method attribute as metadata to provide information grounded in a richer context.
You now have the ability to define a single SLO for all your ingestion points. You can then use our BubbleUp feature to figure out issues when they happen, and automatically expand your alerting to cover new or changing endpoints. If some of your ingestion endpoints are very low traffic though, volume may make it necessary to still split them, but at least it’s intentional.
Increased data availability—often driven by automated instrumentation—is generally a good thing (unless it all becomes too noisy). However, observability implies an ability to extract meaning. Augmenting the data by injecting product-level concepts to provide an outline of what it means makes interpretation more robust and aids mental model formation. It also means that your content will be easier to use for non-engineers, and your observability tools can become huge helpers for other parts of your organization.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.