Meet the Author

Fred Hebert
Staff Site Reliability Engineer at Honeycomb.io
Fred is a Staff Site Reliability Engineer (SRE) who has worked as a software engineer for over a decade and ended up with a healthy dislike of computers and clumsy automation. He’s a published technical author who loves distributed systems, systems engineering, and has a strong interest in resilience engineering and human factors.
Explore Author's Blog
Honeycomb Incident Report: Kafka Maintenance on May 4 and 7, 2026
On May 4th in the EU instance, and May 7th in the US instance, Honeycomb ran its only scheduled maintenance session with major planned downtime in the last five years. The maintenance aimed to replace the decade-old Kafka cluster at the core of event ingestion in all of Honeycomb with a newer, more reliable and scalable cluster.
Incident Report: Exercises, Cleanups, and Evacuations
On December 5th, 2025, we suffered a major outage in our EU region, with the last recovery steps for it extending until December 17th, 2025. For multiple hours, all of Honeycomb’s event ingestion endpoints were down. Most of the duration was spent in a degraded mode where only Activity Log data was impacted. A general timeline is available on our status page, but in this report, we’ll look at a broader analysis of what happened.

Gotta Go Slow
I anticipated this would be a challenging time and that I would be exhausted. So, the plan became: do all the demanding things, take my sabbatical in May, and use April as an ‘in-between’ period with a bit less pressure. I would willingly step off the gas and let other SREs on the team cover pressing matters, as a sort of pre-game for my full month away.

AI: Where in the Loop Should Humans Go?
AI is everywhere, and its impressive claims are leading to rapid adoption. At this stage, I’d qualify it as charismatic technology—something that under-delivers on what it promises, but promises so much that the industry still leverages it because we believe it will eventually deliver on these claims.
Slicing Up—and Iterating on—SLOs
One of the main pieces of advice about Service Level Objectives (SLOs) is that they should focus on the user experience. Invariably, this leads to people further down the stack asking, “But how do I make my work fit the users?”—to which the answer is to redefine what we mean by “user.” In the end, a user is anyone who uses whatever it is you’re measuring.

Restructuring How We Think About Alerts
Back in Alerts Are Fundamentally Messy, I made the point that the events we monitor are often fuzzy and uncertain. To make a distinction between what is valid or invalid as an event, context is needed, and since context doesn’t tend to exist within a metric, humans go around and validate alerts to add this context. As such, humans are part of the alerting loop, and alerts can be framed as devices used to redirect our attention.

Against Incident Severities and in Favor of Incident Types
About a year ago, Honeycomb kicked off an internal experiment to structure how we do incident response. We looked at the usual severity-based approach (usually using a SEV scale), but decided to adopt an approach based on types, aiming to better play the role of quick definitions for multiple departments put together. This post is a short report on our experience doing it.


Making Room for Some Lint
It’s one of my strongly held beliefs that errors are constructed, not discovered. However we frame an incident’s causes, contributing factors, and context ends up influencing the shape of the corrective items (if any) that get created. I’ll cover these ideas by using our June 3rd incident where a database migration caused a large outage by locking up a shared database and making it run out of connections.

Negotiating Priorities Around Incident Investigations
There are countless challenges around incident investigations and reports. Aside from sensitive situations revolving around blame and corrections, tricky problems come up when having discussions with multiple stakeholders. The problems I’ll explore in this blog—from the SRE perspective—are about time pressures (when to ship the investigation) and the type of report people expect.

Alerts Are Fundamentally Messy
Good alerting hygiene consists of a few components: chasing down alert conditions, reflecting on incidents, and thinking of what makes a signal good or bad. The hope is that we can get our alerts to the stage where they will page us when they should, and they won’t when they shouldn’t. However, the reality of alerting in a socio-technical system must cater not only to the mess around the signal, but also to the longer term interpretation of alerts by people and automation acting on them. This post will expand on this messiness and why Honeycomb favors an iterative approach to setting our alerts.
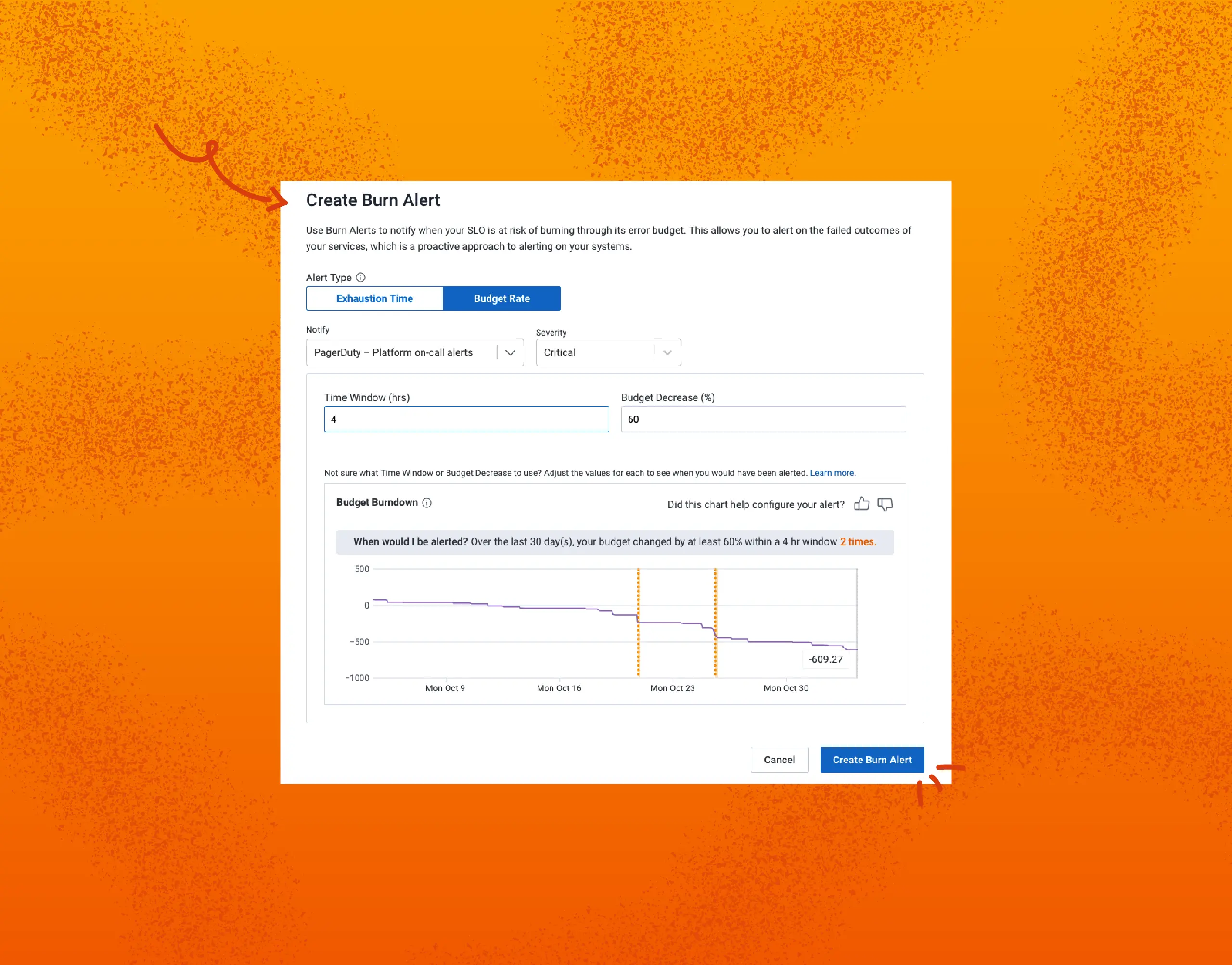
From Oops to Ops: SLOs Get Budget Rate Alerts
As someone living the Honeycomb ops life for a while, SLOs have been the bread and butter of our most critical and useful alerting. However, they had severe, long-standing limitations. In this post, I will describe these limitations, and how our brand new feature, budget rate alerts, addresses them.
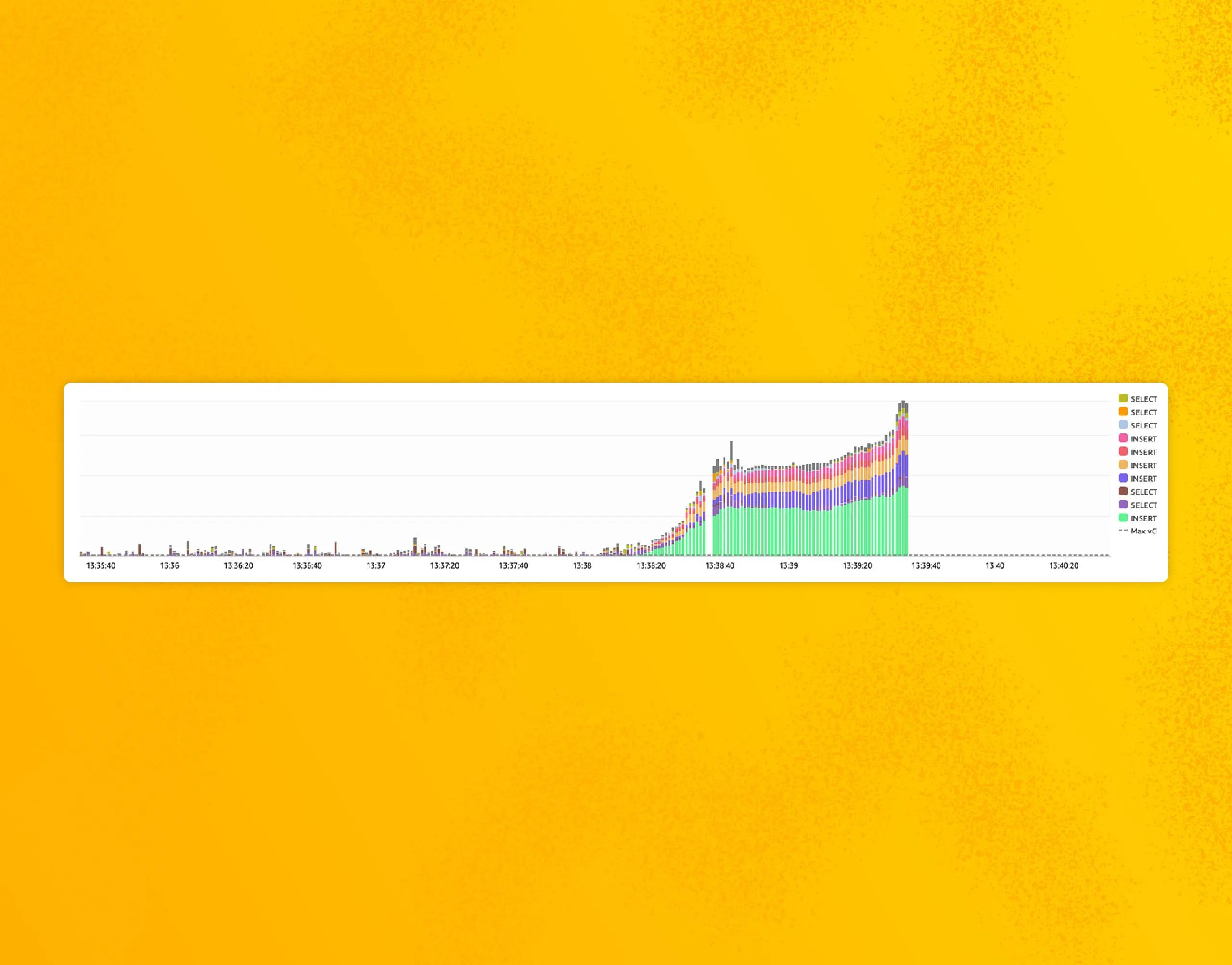
Incident Review: What Comes Up Must First Go Down
On July 25th, 2023, we experienced a total Honeycomb outage. It impacted all user-facing components from 1:40 p.m. UTC to 2:48 p.m. UTC, during which no data could be processed or accessed. This outage is the most severe we’ve had since we had paying customers. In this review, we will cover the incident itself, and then we’ll zoom back out for an analysis of multiple contributing elements, our response, and the aftermath.

There Are No Repeat Incidents
People seem to struggle with the idea that there are no repeat incidents. It is very easy and natural to see two distinct outages, with nearly identical failure modes, impacting the same components, and with no significant action items as repeat incidents. However, when we look at the responses and their variations, we can find key distinctions that shows the incidents as related, but not identical.

How We Define SRE Work, as a Team
The SRE team is now four engineers and a manager, and we are involved in all sorts of things across the organization, across all sorts of spheres. We are embedded in teams and we handle training, vendor management, capacity planning, cluster updates, tooling, and so on. After growing the team to a point where we could get a better grasp on our mission and identity, we decided to revisit our charter. It is a living document after all, and it was exciting for me to let other folks get their hands in it.

How We Manage Incident Response at Honeycomb
When I joined Honeycomb two years ago, we were entering a phase of growth where we could no longer expect to have the time to prevent or fix all issues before things got bad. All the early parts of the system needed to scale, but we would not have the bandwidth to tackle some of them graciously. We’d have to choose some fires to fight, and some to let burn.

Counting Forest Fires: Incident Response Metrics
There are limits to what individuals or teams on the ground can do, and while counting fires or their acreage can be useful to know the burden or impact they have, it isn’t a legitimate measure of success. Knowing whether your firefighters or whether your prevention campaigns are useful can’t rely on these high-level observations, because they’ll be drowned in the noise of a messy unpredictable world.
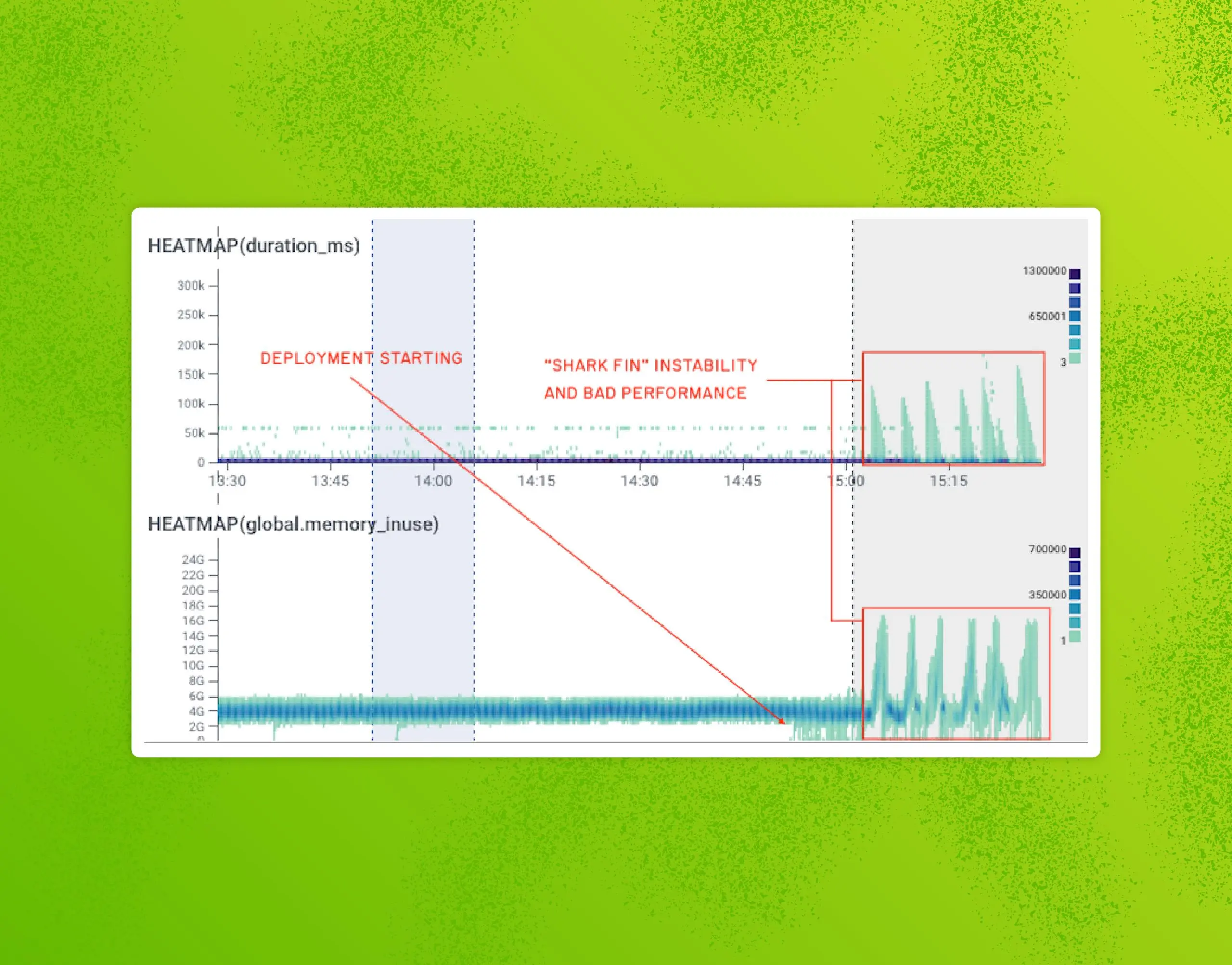
Incident Review: Shepherd Cache Delays
In this incident review, we’ll cover the outage from September 8th, 2022, where our ingest system went down repeatedly and caused interruptions for over eight hours. We will first cover the background behind the incident with a high-level view of the relevant architecture, how we tried to investigate and fix the system, and finally, we’ll go over some meaningful elements that surfaced from our incident review process.
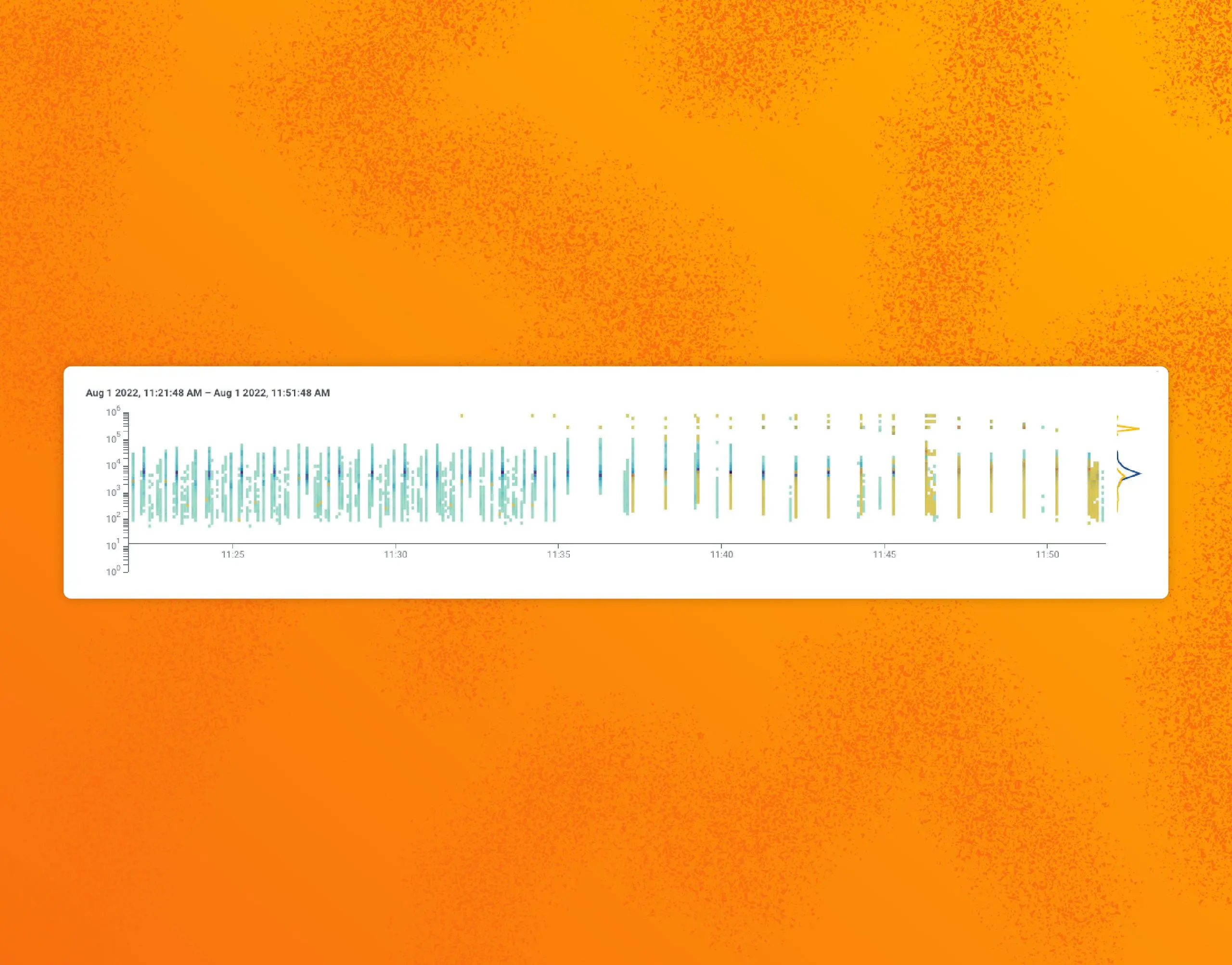
Incident Review: Working as Designed, But Still Failing
A few weeks ago, we had a couple of incidents that ended up impacting query performance and alerting via triggers and SLOs. These incidents were notable because of how challenging their investigation turned out to be. In this review, we’ll go over interesting patterns associated with growth, and complex systems—and how these patterns challenged our operations.

On Counting Alerts
A while ago, I wrote about how we track on-call health, and I heard from various people about how “expecting to be woken up” can be extremely unhealthy, or how tracking the number of disruptions would actually be useful. I took that feedback to heart and wanted to address the issues they raised, and also provide some numbers that explain the position I took with these metrics.