Interview with Honeycomb Engineer Chris Toshok: Dogfooding OpenTelemetry
We often get questions about the difference between using our Beeline SDKs compared with other integrations, especially OpenTelemetry (abbreviated “OTel”). That’s why the team decided to do some integration dogfooding by instrumenting our own code with OpenTelemetry alongside existing Beeline instrumentation.

By: Shelby Spees

At Honeycomb, we talk a lot about eating our own dogfood. Since we use Honeycomb to observe Honeycomb, we have many opportunities to try out UX changes ourselves before rolling them out to all of our users.
UX doesn’t stop at the UI though! Developer experience matters too, especially when getting started with observability. We often get questions about the difference between using our Beeline SDKs compared with other integrations, especially OpenTelemetry (abbreviated “OTel”). That’s why the team decided to do some integration dogfooding by instrumenting our own code with OpenTelemetry alongside existing Beeline instrumentation.
Poodle is the frontend Go service that renders visualizations in the Honeycomb UI after getting query results and traces from the backend. Engineer Chris Toshok has been working on adding OpenTelemetry to the Poodle code and comparing it with our existing Beeline integration. I talked to Chris about his experience setting up OpenTelemetry from the perspective of a practitioner and service owner.
Interview with Chris Toshok
What were your thoughts going into the effort?
The main concern was schema compatibility. We have existing triggers, boards, SLOs, other things that relied on the schema that the Beeline generated. If we only sent to the existing Poodle dataset, we’d have to make sure that the OTel data would end up with the same field names and values as what’s already there, so it wouldn’t break the things that depend on the existing schema.
Alternatively, we could double-send: the Beeline data goes to one dataset and OTel data goes to another. We ended up going this way so that we can look at what the differences are between the two schemas without breaking existing dependencies in our Dogfood team.
Was there anything that surprised you in the process?
While there are lots of little differences between the APIs, the core concepts were the same. The only real sort of surprise was that the Beelines actually let you do stuff that’s kind of scary, because of how the data is stored.
With OTel, as soon as set a value for a field, you can’t modify that value, only replace it. In the Beeline, it’s just a reference to a Go struct. You can just change the values at any point before the data gets sent to Honeycomb. With some fields, like the team object within a span, changing that could be dangerous. But sometimes you want to change a certain value in the middle, like if you need to sanitize values before sending them to Honeycomb.
The configuration for OTel is a bit different from the Beeline, did you also work on getting set up with that?
We basically just set up the OpenTelemetry-Honeycomb Exporter for Go, written by [engineer] Alyson [van Hardenberg].
In the code, I used dependency injection to create an OTel-compatible initializer that works similarly to the Beeline. Beeline data and OTel data are stored a bit differently before they’re sent out, so we need to handle both cases. I added a shim that looks very similar to the OTel API, to wrap around both OTel and the Beeline and allow us to send to Honeycomb using either or both.
If you could give advice to a team starting today, would you recommend they use the Beeline or OTel for their Go app?
Beeline has a much more specific API that maps more closely to Honeycomb’s features. OTel is doing things at a more general layer, so it might not have all the interesting application bits that we have after several years of doing Honeycomb-specific work in the Go Beeline, which is an effect of the Beeline being something we built out alongside Honeycomb itself. We developed it to answer the questions we had about the service, and to make use of Honeycomb’s features.
What sort of differences have you found?
There were a couple small, but notable differences. OTel sends JSON blobs as strings, which don’t work with the JSON unfurling feature in Honeycomb.
Also, Beelines allow us to set trace-level attributes. Any span that we send can add a trace-level field. OTel doesn’t support trace-level fields added from child spans.
Have you noticed any performance changes in Poodle after adding OTel?
No change, but I’m wishing we had time over time queries. This is something I was interested in checking on and seeing in time series form.
Observing the impact
Toshok shared with me the queries he ran to check for any impact to Poodle’s performance. Here’s the baseline behavior from the week before Toshok’s change went out:
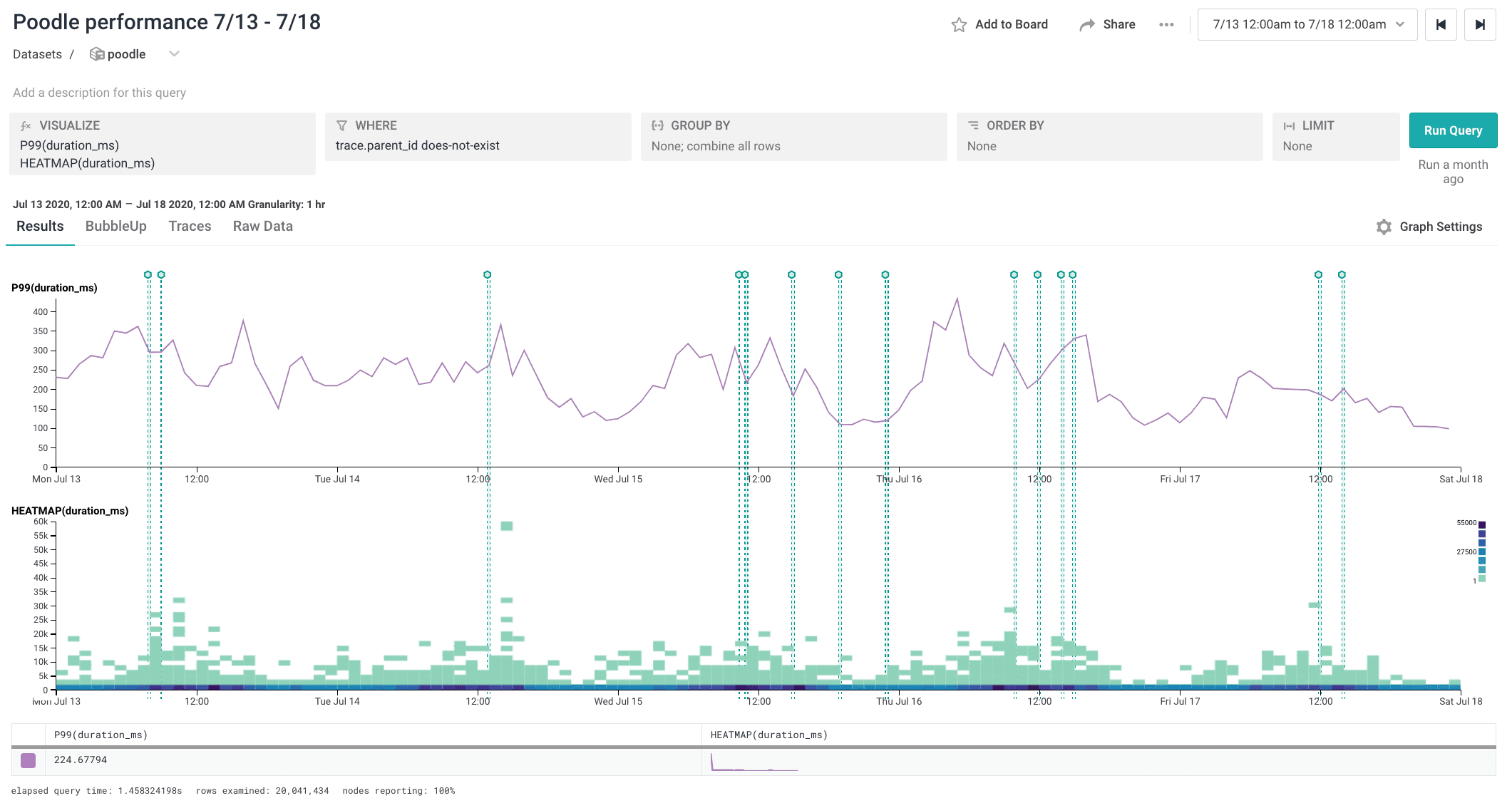
Here’s the same query, run on the following week. Toshok’s changes got rolled out on 7/21:
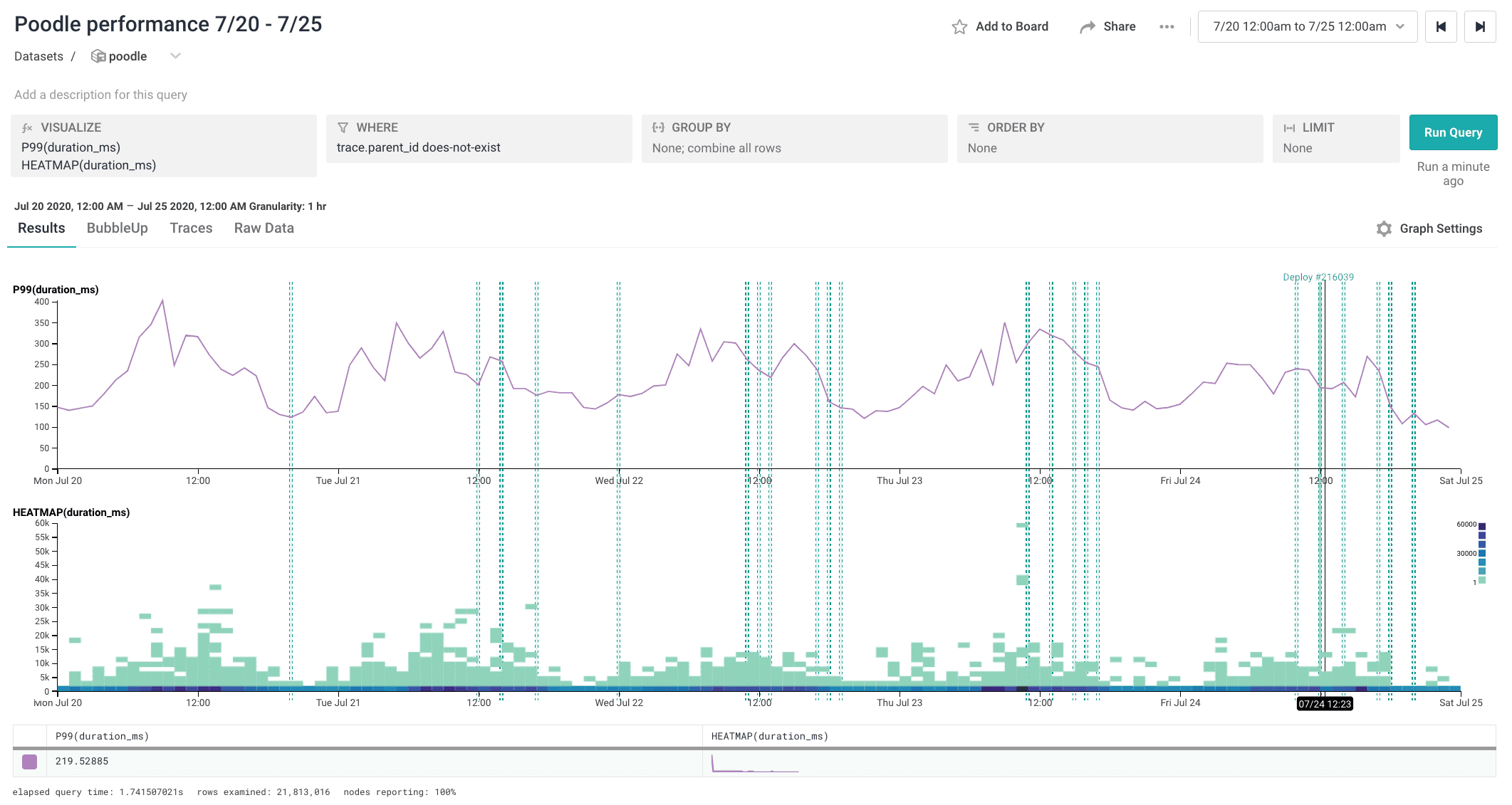
It makes sense that there would be minimal impact in this case because of how Toshok implemented the change, but it’s still neat to be able to query for it.
Try it yourself!
Interested in comparing OTel and Beeline? Here’s how Toshok did it. For the most part they were 1-1 changes using the new OTel-aligned shim API:
- span.AddField("error", err.Error())
+ span.SetAttribute("error", err.Error())Occasionally Toshok needed to do some type manipulation for compatibility with OTel:
- beeline.AddField(ctx, "error", err.Error())
+ span.SetAttributes(instr.AppString("error", err.Error()))But the overall shape of the instrumentation remained the same:
- ctx, span := beeline.StartSpan(ctx, "runQueries")
- defer span.Send()
+ ctx, span := instr.StartSpan(ctx, "runQueries")
+ defer span.End()If you’re starting out from scratch, follow our OpenTelemetry Go tutorial to get up and running with Honeycomb in no time!
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.