Live on the Edge with Honeycomb and CloudFront
Here at Honeycomb, we know that you can get big benefits quickly by starting with observability at the edge. No, not that Edge. The other edge. That’s why today we’re pleased to announce the…

By: Nathan LeClaire

Here at Honeycomb, we know that you can get big benefits quickly by starting
with observability at the edge.
No, not that Edge. The other
edge.
That’s why today we’re pleased to announce the new Honeycomb integration for Amazon Web Services CloudFront access logs!
Observability for CDNs
Many modern infrastructure setups are running their servers in one or more
geographic regions, such as us-east-1, which is located on the East coast of
the United States. Deploying to a single region (perhaps with multiple
“availability zones” representing redundant datacenters within the region) is
simpler than deploying in multiple regions. But in today’s highly-connected age,
it’s very unlikely that the majority of your users are concentrated in one
geographic region. If they are hitting the origin servers directly, many users
face the possibility of a slow website, and even the best caching added at the
application layer will leave latency at the mercy of slow routes and dropped
packets on the way to your origin server.
Therefore services such as AWS Cloudfront,
a CDN provided by
Amazon to speed up your websites, have emerged.

However, CloudFront faces the same problem that much of the cloud magic we like
to use in modern deployments does: It’s hard to observe, to reason about, and
consequently to rule out as a source of issues for our users.
Hard Problems
It’s said that there are only two hard problems in Computer Science: Cache
invalidation and naming things.

We don’t have any solution for the latter – just the finest of organic local
bike sheds, cooked up with care right here at Honeycomb
HQ. However, with our new CloudFront integration we might be able to help you
make strides on when the former is happening, on a global scale.
Let’s say that some of your users are complaining about hitting a bug, and you
roll out a new patch to the JavaScript on your website intended to fix the
issue. You might tell your users to mash F5 and pray after you deploy the fix,
hoping that their cached static assets eventually catch up and you can verify
that the bug is fixed. This is, of course, time-consuming and frustrating.
It sure would be nice if we could somehow check on when the next cache miss
occurs for that asset so we can verify if our users are receiving the new file
(and consequently if the problem was successfully fixed or not). Naturally, we
can with the new Honeycomb CloudFront integration.
If we BREAK DOWN by:
- cs_uri_stem – the URI for the served content (e.g.: /main.js)
- x_edge_response_result – whether it was a cache Hit, Miss, or other
then we will be able to visualize calculations for each unique group of events
that this creates. For instance, we can CALCULATE the P99(time_taken) (the
99th percentile of the amount of time in milliseconds taken to serve content in
that group). We will be able to see where our CDN is performing well on both
cache hits and misses for all of our served content.
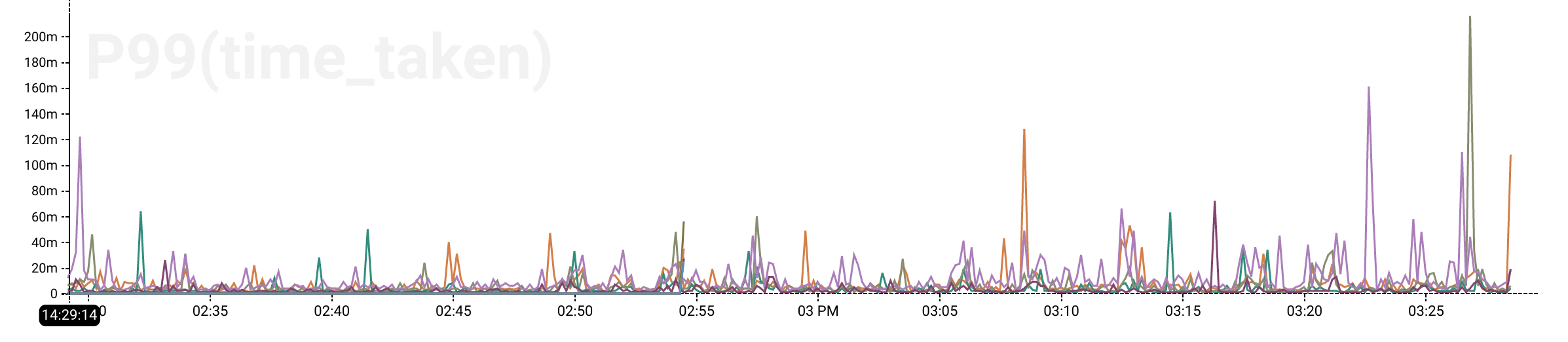
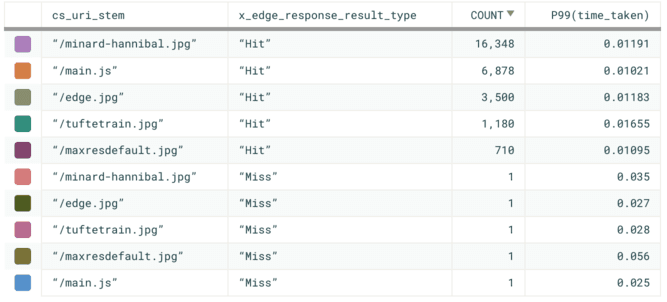
It’s easy to see that there are far more cache hits than cache misses, but we
can also see the cost of cache misses, and when the misses are occurring. If we
filter by cs_uri_stem = /main.js, we can spot the exact moment that CloudFront
had a cache miss serving the file and (presumably) our users started receiving
the new one. Thus, we can either verify that the bug was fixed by the new change
or go back to the drawing board.
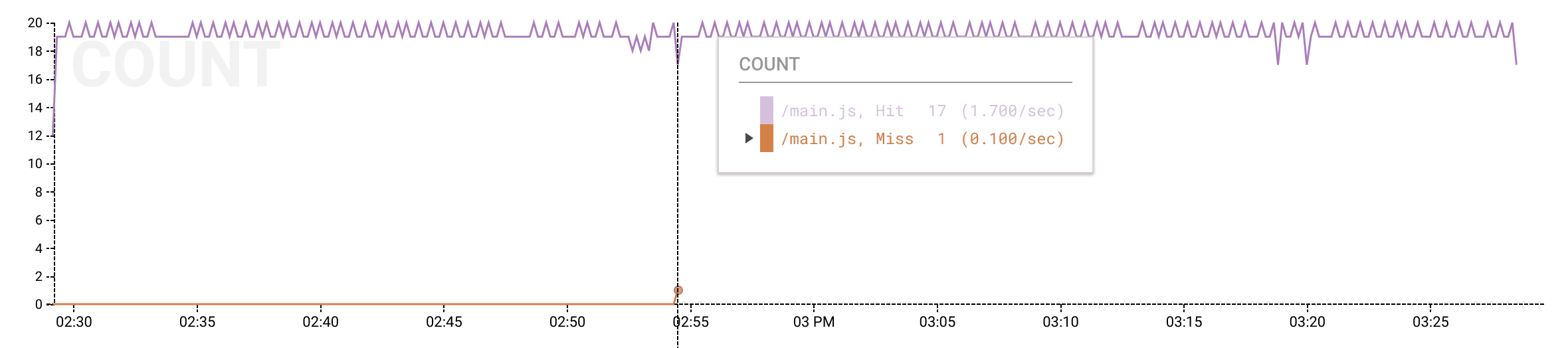
Because Honeycomb handles this kind of high
cardinality
data without issue, even if we were managing thousands or millions of different
URIs we would still be able to dig up exactly the information we are interested
in. We did not need to know exactly which things to measure ahead of time, only
that the information might be useful later on.
Try it Today
You can start using the new integration by following the documentation
here for the new CloudFront integration. Even if
you’re simply serving static content from S3 with CloudFront, we feel that the
CloudFront integration will give you an unprecedented level of visibility into
your CDN.
We hope you enjoy, and as always, we’d love it if you signed up for a free
trial to learn how to scan millions of data points in seconds to solve
your problems.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.