Navigating Software Engineering Complexity With Observability
In the not-too-distant past, building software was relatively straightforward. The simplicity of LAMP stacks, Rails, and other well-defined web frameworks provided a stable foundation. Issues were isolated, systems failed in predictable ways, and engineers had time to innovate on new features for the business. And it was good.

By: Rox Williams


The Cost Crisis in Metrics Tooling
Learn MoreIn the not-too-distant past, building software was relatively straightforward. The simplicity of LAMP stacks, Rails, and other well-defined web frameworks provided a stable foundation. Issues were isolated, systems failed in predictable ways, and engineers had time to innovate on new features for the business. And it was good.
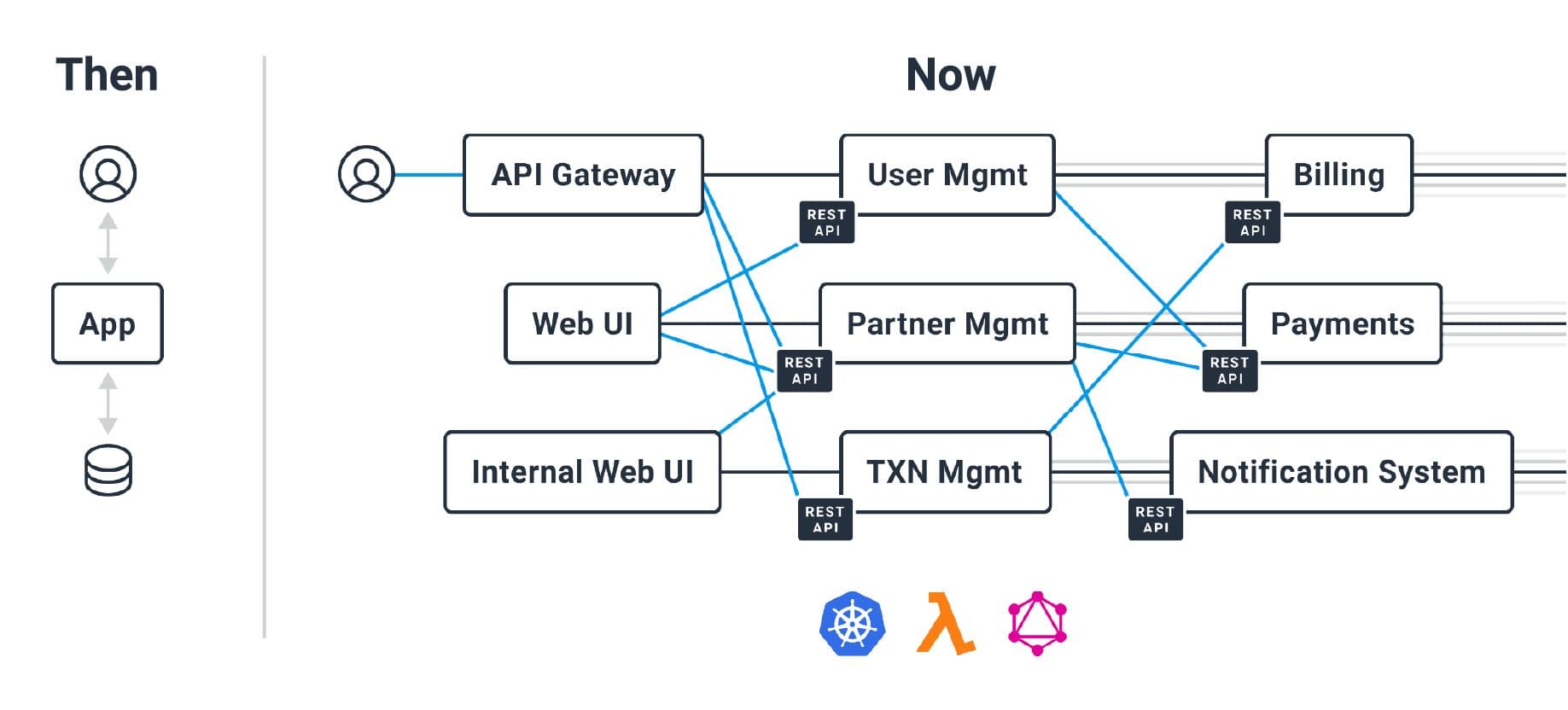
However, the landscape of software development has dramatically transformed, ushering in an era where traditional tools simply can’t keep pace with the complexities of cloud-native environments and distributed systems. That complexity is mighty, and comes with consequences.
The implications of increased complexity
Operational risk
Reactive firefighting becomes the norm, with teams often finding issues after customers do. This delays resolutions, impacts brand reputation, and results in missed revenue targets. Engineers are frustrated and burned out. Turnover becomes an issue.
Reduced innovation
When engineers spend so much time investigating issues rather than developing new features, innovation takes a backseat. This stifles creativity, resulting in fewer releases and missed market opportunities. Customer satisfaction dwindles. Churn is inevitable.

Decreased engineering efficiency
With junior engineers lacking system knowledge, senior engineers become bottlenecks. This inefficiency is compounded by tools that can’t scale with the org. High-impact work is delayed.
Increased cost of ownership
Disparate tools for logs, metrics, and traces come with their own costs, leading to a significant cost multiplier effect. As data accumulates, cost explodes while the value you get from these tools decreases. Check out Charity’s blog post on the cost crisis in observability tooling for more information.
Find out how to tackle the cost crisis in observability in our whitepaper.
In this evolving landscape, the critical question emerges: “How is my software doing, who does it suck for, and why?“
When legacy tools don’t meet the need
Traditional monitoring tools, while invaluable in the before times, were architected for very simple systems that failed in predictable ways. They are, for all intents and purposes, not built for today’s complex distributed systems.
Enter observability. I won’t go too much into what observability is—we have tons of content on that—but suffice it to say that unlike its traditional counterparts, observability embraces modern concepts:
- High-cardinality data
- Wide events
- Fast querying capabilities
- AI-powered features to make querying simpler
- Anomaly detection
- Service Level Objectives (SLOs)
- Frontend observability
- The list goes on and on 🎶
This approach empowers engineers to proactively identify and solve issues, optimize performance, and enhance the customer experience—all while reducing operational risk and costs, and increasing innovation.
Modern observability with Honeycomb
Honeycomb was purpose-built to thrive in the complexity of today’s software environments. With our emphasis on high-cardinality data and wide events, coupled with a blazing fast query engine and full-stack observability through our recent addition of Honeycomb for Frontend Observability, Honeycomb enables organizations to:
- Identify hidden issues: Pinpoint and mitigate issues affecting top customers before they impact the broader user base, and before they breach SLAs.
- Remove inefficiencies: Streamline platform services and improve team efficiency by reducing time spent on troubleshooting and enhancing time-to-resolution (TTR).
- Innovate effectively: Innovate on frontend user experiences and improve Core Web Vitals scores by leveraging actionable insights derived from comprehensive observability data.
Embracing the increasingly complex future of modern software
As we navigate the complexities of modern software development, the need for robust observability solutions like Honeycomb has never been clearer. The ability to answer questions about your software’s performance—how is my software doing, who does it suck for, and why?—allows companies to keep innovating on new features, deliver superior customer experiences, and drive sustained growth.
Observability represents a transformative opportunity. By embracing it, organizations can unlock new levels of efficiency, performance, innovation, and customer satisfaction—paving the way for a more resilient future in software engineering. Try it today.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.