There Are No Repeat Incidents
People seem to struggle with the idea that there are no repeat incidents. It is very easy and natural to see two distinct outages, with nearly identical failure modes, impacting the same components, and with no significant action items as repeat incidents. However, when we look at the responses and their variations, we can find key distinctions that shows the incidents as related, but not identical.

By: Fred Hebert

People seem to struggle with the idea that there are no repeat incidents. It is very easy and natural to see two distinct outages, with nearly identical failure modes, impacting the same components, and with no significant action items as repeat incidents. However, when we look at the responses and their variations, we can find key distinctions that shows the incidents as related, but not identical.
We preach transparency at Honeycomb, so here’s an example that happened to us not too long ago.
The first incident
Back in December 2021, in the midst of our EC2 to EKS migration, we suffered a long outage along with a lot of AWS users. Multiple APIs experienced elevated error rates in the us-east-1 region, and this outage unfortunately lasted hours. This incident had us improvise all sorts of solutions we never thought we’d need before—or again, for that matter.
As a background for the incident, we operate in us-east-1 exclusively (albeit within many redundant zones). Many of our runtime secrets and configuration are stored in AWS SSM, with a YAML file telling our services which secrets they need to load at boot time. It has a permissive format: it either names SSM parameters to fetch, or accepts cleartext fake values for CI or development environments.
When SSM started failing intermittently, our services and cron jobs couldn’t start, but those already running kept running. Some of our critical services are supported by frequently run tasks, so even long-running processes that weren’t disrupted still risked failing after many hours of supporting routines not running.
As soon as we noticed SSM failures, we pinned builds to avoid deployments that would restart servers and keep them down. Then, we rushed to keep our storage engine alive by manually spamming the cron jobs that would offload traffic to S3, so that their disks would not fill up. We also did a lot of internal traffic shaping by moving inbound events to hosts with more local disk storage in hopes we’d delay failures that are harder to address.
Meanwhile, our teams brainstormed how to fix the issue, given that we couldn’t access most of our credentials. A group of engineers figured out that they could use cleartext credentials in the secrets YAML manifest, as if the production environment was a developer’s machine. We could cycle these creds later once the system was stable.
Other services required more data, for which we had no stored copy. We had to query the sporadically failing SSM service repeatedly until we could extract all the credentials we needed.
As soon as this was done, we manually uploaded the tricked-out manifests to all failing hosts, recovered service, and then did the same with other environments.
We ran long internal incident reviews about this, and eventually came to the conclusion that this was such a rare and tricky issue that there was little we could do to plan for further mitigation. The failure mode in EKS post migration would look very different, and it wasn’t useful to tackle this right then.
Instead, we spent our time investigating how we adapted to unforeseen circumstances, how we came up with unexpected mechanisms to restore service, and the way we structured our response. Our conclusion was: this was likely a very rare event, so there were more general lessons to learn by looking at how we responded, rather than what we could do to prevent reoccurance.
Explore our Kubernetes Migration
The second incident
In September 2022, a similar outage happened where SSM would intermittently fail. This time, it did not take out most of us-east-1, but it was almost identical to us. We described it as a “repeat incident,” but looking back on it, things happened in a very different manner.
First, this time around, the incident happened right in the middle of a deployment. This meant that before we could even do anything, most of our query engine was down and unable to start. Rather than a weird, slowly evolving situation where we made huge efforts to keep the system alive, we were in the midst of a major outage where it was already too late.
Second, once we saw the error messages, we instantly knew what SSM failures meant, and knew how to work around them. We ran to Jeli, where we ran the previous investigation and tagged all significant events. The Commands search, for example, instantly gave us a list of all the troubleshooting commands we ran:
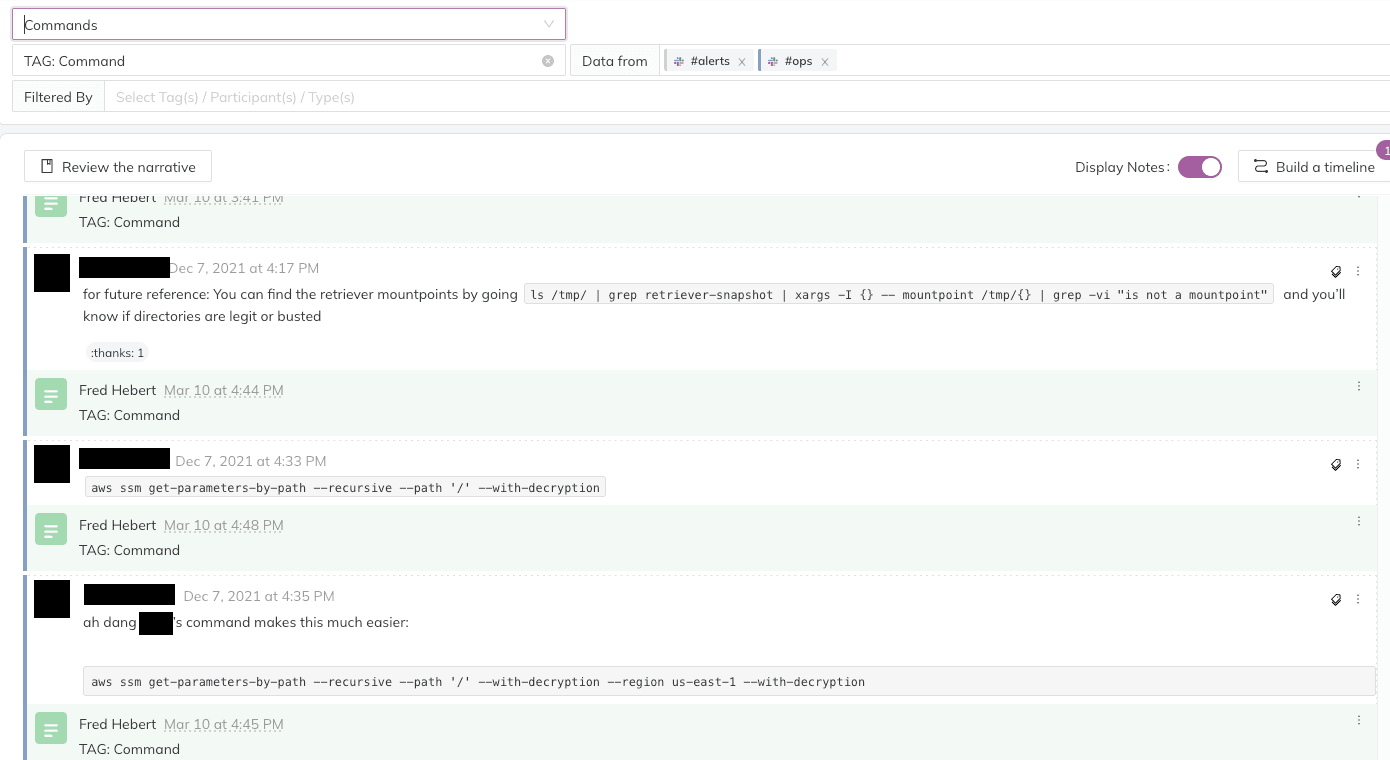
We had also searched for stored queries to show impact, tracked disk storage issues, listed all tricky coordination points we encountered, or public communications we sent out.
Writing a runbook for each incident would be demanding, but in this case, the incident investigation itself acted as a reference. We quickly gathered all the information into a single big plan, and pinned it to our incident channel:

We then could dispatch all these critical tasks to subgroups, focus on the elements that surfaced for the first time (“All the Retrievers are dying and need to be restarted”), and prevent the sort of degradation that took more than one day of clean-up last time.
One of the side effects I had not expected, however, is that this incident felt good. Not in the, “Oh cool, an incident, what great luck” sense, but compared to the incident we had just the day before, it was nice and orderly, and gave more room to improvise and improve on new dimensions.
The difference
Most things were under control. There was far less oh-shit-what’s-going-on energy this time around, and we came up with new approaches to fix the problem.
We set up mirrors of our secrets’ configuration (which later got automated), and wrote code fixes to let us move only secrets to different AWS regions. Whenever SSM would have an outage in us-east-1, we could keep running and booting our workloads there—without credential issues.
What I find particularly interesting about this approach is that it feels downright obvious. But why was it not so obvious in the past, for the first incident and its reviews? I can’t help but feel that this failure mode, which was brand new and very surprising to us all the first time around, took a lot of our energy and mental bandwidth just to scope out. Doing the most basic salvage work to prevent a total outage of the system (or data loss) drained us.
To put it another way, we needed all of our brains for mitigation, and there wasn’t a lot of brainpower left for improvements. But when a bunch of us got thrown back in that situation and all the groundwork was already done, it was much easier to go in and find ways to make things better in that context.
In the end, there are no repeat incidents. We gain experience, we accrue knowledge, and this alone changes everything about how a similar incident unfolds the second time around.
Want to learn more about how we do incident management at Honeycomb? Watch the webinar or read the blog.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.