How We Manage Incident Response at Honeycomb
When I joined Honeycomb two years ago, we were entering a phase of growth where we could no longer expect to have the time to prevent or fix all issues before things got bad. All the early parts of the system needed to scale, but we would not have the bandwidth to tackle some of them graciously. We’d have to choose some fires to fight, and some to let burn.

By: Fred Hebert

When I joined Honeycomb two years ago, we were entering a phase of growth where we could no longer expect to have the time to prevent or fix all issues before things got bad. All the early parts of the system needed to scale, but we would not have the bandwidth to tackle some of them graciously. We’d have to choose some fires to fight, and some to let burn.
This approach to system scaling extends itself quite naturally to the realm of incidents, and of large complex systems always being in a partial state of failure. Incidents are normal; they’re the rolled-up history of decisions made a long time ago, thrown into a dynamic environment with rapidly shifting needs and people. While something may have worked great yesterday, it might not work great today. It’s normal for things to bend, creak, and snap under the weight of conflicting goals and pressure.
Incident response, then, is riding the far end of a cracking whip. You get to react quickly to past decision-making in your organization—and even your industry. That’s challenging, but also what makes it so interesting and rewarding. This vision is what influences how I try to shape, with the help of many coworkers, the way Honeycomb manages incident response.
This article is broken down in five sections that provide a somewhat coherent view of incident response at Honeycomb: dealing with the unknown, managing limited cognitive bandwidth, coordination patterns, maintaining psychological safety, and feeding information back into the organization.
This list is in flux, but it represents a decent high-level snapshot in time of what I think is important today.
Dealing with the unknown
Our quick growth had us transition from a small core engineering team where everyone knew everything into a larger organization with a few key people that knew its tangled history—and a bunch of new folks who knew only bits and pieces. We’ve reached the point where no one can hold the whole system in their head anymore. While we ramp up and reclaim expertise—and expand it by discovering scaling limits that weren’t necessary to know about before—we have to admit that we are operating in a state where some elements are not fully in our control.
When onboarding people to on-call, we tell them:
- We can’t teach them everything.
- They’ll carry a pager before they know most things, and that’s fine. No one is expected to know everything.
- They are expected to do a quick assessment and maybe fix or mitigate what they can, but anything else beyond that is a bonus.
- Their role as a pager-keeper is to field disruptions and triage on behalf of the rest of the team, on whom the overall responsibility lies.
- If they find themselves in a situation that goes beyond their current capacity, escalation is always fine.
This approach transpires everywhere, not just in the little speech we give them before they start shadowing someone else. Compared to other places I’ve worked, we have fewer runbooks with detailed instructions, and more alerts that describe what they’re looking for and how long responders have before things get more challenging.
When shipping a new feature, we don’t seek all the ways in which it might break to preempt them. Instead, we prepare ways for us to degrade service or turn off the new feature safely if it goes wrong. We don’t need to fix this at 2 a.m.; we can gracefully limit impact so we can look at it together during business hours.
We want to assume it will go wrong—we just don’t know how and want to have the means to deal with that. What are manual controls or overrides? What services are allowed to degrade, and what are invariants that are absolutely not allowed to be broken? And if they do break, what’s acceptable to prevent it from getting worse?
This demands alignment on what our core features are, what functionality is most critical, how we can plan for shutting peripheral components down to salvage core ones, and encourages us to have honest discussions about business and engineering priorities. You can then deal with surprises better.
Managing limited cognitive bandwidth
People who are woken up by an alarm have less ability to think than during the day. The increased pressure of incident response—regardless of how ok you say it is to have outages—narrows your field of perception. Debugging systems at rest is hard, and debugging them in times of stress, while also managing all other sorts of incident-shaped things, is harder.
Operating a system in the heat of the moment is done by a version of yourself that is busier, sleepier, more stressed and therefore relatively less capable of careful, calm, and attentive reasoning than the one currently reading this.
Dealing with the unknown asks for quickly actionable controls such that they conveniently bring us to a manageable state, which creates more room to think and act, and supports this point.
Additional support can be provided at other levels, such as alert hygiene and design. If you have to spend time knowing whether an alert is urgent or not, real or fake, or a cause or a consequence, you are taken away from the actual situation. We’re not doing a perfect job here, but we try to have alerts that are helpful:
- There are different burn alerts for low-level warnings and high-urgency ones, going through different channels according to how much work/time they’ll require.
- Critical pages come with a related BubbleUp query (either automated for service-level objectives (SLOs) or in the description for triggers) to orient you toward good signals or common sources of noise.
- We try to raise the thresholds of flapping alerts we can’t tackle now; we don’t want to hide new escalations in pre-triggered alarms, and want to avoid alert fatigue.
Your interaction with the system as an on-call user begins with the alert. Therefore, whatever query or signal we use in the alert has to include clues about the context of the event and the specifics of how it’s being triggered right now.
For example, when looking for failed builds, adding a GROUP BY on the build URL so the error in Slack already contains a link that lets you jump directly to the relevant data. They’re little details that save bandwidth and let you focus on the right thing.

Coordination Patterns
We’ve so far resisted adopting any ready-made incident command framework, even though we’ve studied them and inspired ourselves from them. The key issues we are trying to balance are:
- Avoiding the incident framework being more demanding to the operator than solving the issue. We push back on having to discuss severities or strict rules about what is or isn’t a public incident and default to being more open.
- Providing support and tools that are effective to people with less on-call experience and for whom clearer rules and guidelines are helpful.
As a compromise, we use Jeli’s incident response bot, which is a lightweight way for us to create dedicated investigation channels, assign minimal roles, and keep a history of updates for participants that join later, along with other stakeholders. This avoids constraining response patterns, but provides enough support to make sure information is broadcasted internally with limited overhead.
During an incident, there are signals and behaviors that hint at cultural bits of self-organization that I particularly enjoy:
- Announcing you’re going to do something before doing it, so that everyone around knows about it and has a chance to support or counter it.
- The use of Reactji for quick reactions without interrupting anyone’s flow.
- People creating threads for sub-investigations, with a final “also send to #channel” message that reinjects the findings in the main discussion flow.
- Honeycomb queries with useful information are linked in the channel, and people from different parts of the organizations collaboratively enrich the query with new perspectives until we reach insights that nobody could have had in isolation.
- Sometimes, threading goes too deep and we spin off subchannels, video calls, or improvise new patterns to avoid confusion.
- Responders keep an eye on the flow of the incident, partly at an emotional level. They make comments like “this is starting to feel confusing,” “is anyone else overwhelmed right now?” or “are there too many people in here?” and take these as a signal to reorganize response.
- Sometimes, letting newer people gain experience even if it makes response slower now is healthier for the team—and the product—in the long term.
These aren’t things you’d find in a general incident framework, which often tries to bring clarity to large and diverse response groups by making responsibilities explicit. The coordination patterns I have found here and that I now try to reinforce are local, and about getting a good feel for when we need to change what we’re doing.
In the aftermath, when we run incident reviews, we can look at all the challenges we encountered, surface the interesting patterns that came up to deal with them, and add them to our toolkit for next time.
Maintaining psychological safety
It’s not realistic to tell an organization “we’re gonna make sure we can shut things down fast” or “please let everyone know if you feel like there’s too much going on” and expect it to just happen.
These behaviors become possible only once your people feel they are safe, that they are allowed not to know things, and that if we encounter challenges, we’ll work together to address them rather than finding who needs to shape up and do better. The responsibility is shared, and it is the whole system that is accountable for improving the situation, rather than whoever had the generosity of accepting to be on call at the time.
When we last onboarded new engineers to our call rotations, rather than explaining how the components work—which they’ll learn over time—we held a discussion in one of our weekly sessions about what is in this post: that we are expected to not know what is going on, that this is okay, and that responsibility is shared and we are fully aware of the situation they’re being put in.
This is followed with rounds of shadowing, reverse-shadowing, giving people time off after off-hour pages, and making sure we actually call out pager escalations (once someone feels they need help) as a desirable outcome. Any incident we decide is worthy of a retrospective is done by adhering to these principles as well.
But all this work is ongoing work, and maintaining psychological safety is one of the highest priorities we have in mind around operational work.
Feeding information about the outcomes back into the organization
Incidents need to be part of a feedback loop. This is where the rubber meets the road, and the things we learn there are related to much older decisions based on the organizational culture, its priorities, and its practices.
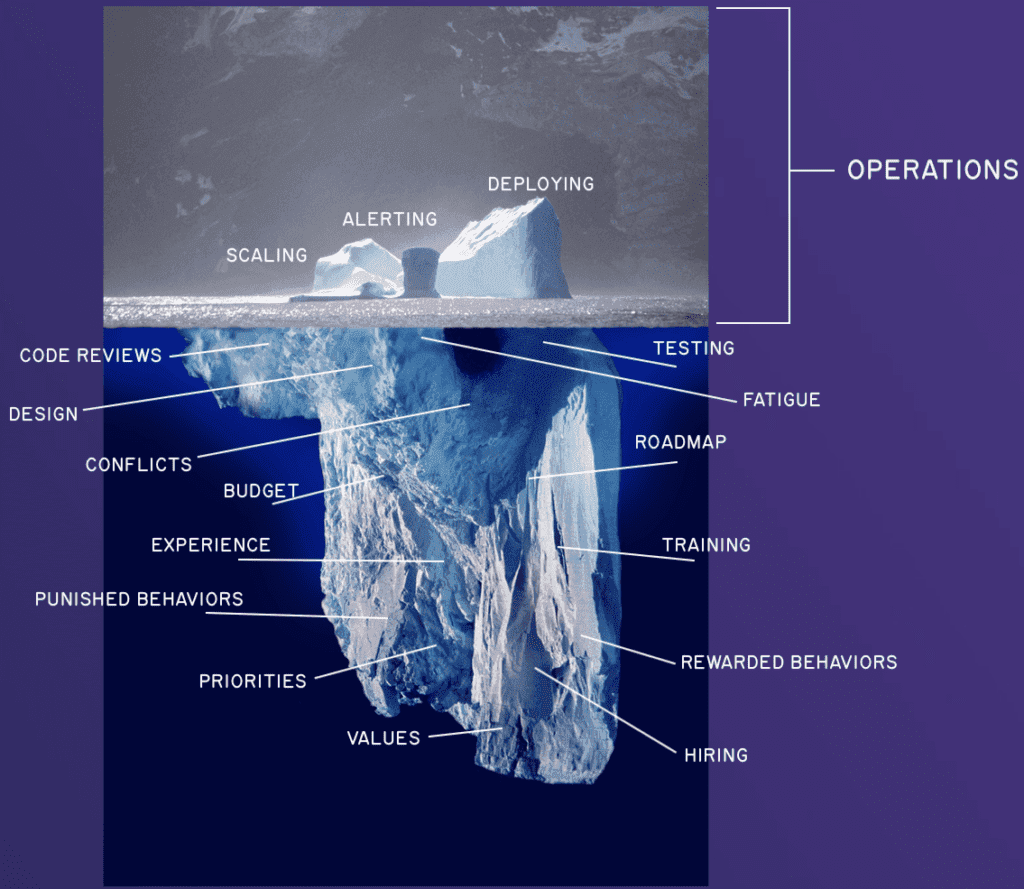
We have a responsibility to use incidents judiciously, as learning opportunities about the work we do. Learning is most effective when you can associate actions to outcomes, and having incidents without taking the time to think about their implications is throwing away fantastic opportunities served to us on a (often scorching hot and unpleasant) silver platter.
From that understanding, and with enough trust and agency given to people within the organization, we are able to improve our processes, change how we work, and get in a better position for tomorrow’s challenges.
Want to learn more about how we do incident response?
While incident response at Honeycomb is richer than what I presented—and probably more structured than I implied—these high-level abstract priorities guide whatever method we adopt or adjust. They change with time, and if you want to see a more detailed, ground-level view of what it looks like, we have a talk about that!
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.