Alerting on the User Experience
When your alerts cover systems owned by different teams, who should be on call? We get this question a lot when talking about SLOs. We believe that great SLOs measure things that are close to the user experience. However, it becomes difficult to set up alerting on that SLO, because in any sufficiently complex system, the SLO is going to measure the interaction between multiple services owned by different teams. Therefore, the question becomes: who gets woken up at night when an SLO is burning through its error budget?

By: Nathan Lincoln

When your alerts cover systems owned by different teams, who should be on call?
We get this question a lot when talking about SLOs. We believe that great SLOs measure things that are close to the user experience. However, it becomes difficult to set up alerting on that SLO, because in any sufficiently complex system, the SLO is going to measure the interaction between multiple services owned by different teams. Therefore, the question becomes: who gets woken up at night when an SLO is burning through its error budget?
We’ve had a lot of discussion about this topic, from OnCallogy sessions, to long slack threads, to discussions in SRE team meetings. I’m going to condense our guidance on this issue in this blog post.
This is a hard socio-technical problem
Let’s start by talking about the ‘team dynamics’ problem. There are several questions you should think about:
- What is the relationship between the teams that impact this SLO? Are they friendly with each other?
- Do they all share the burden equally?
- Is there one team that is facing more challenges in operating their services?
While these questions won’t bring you to the correct answer, they’ll help you understand the context you’re operating in, and ultimately make it easier to make changes. For now, let’s go over the four routes you could take for alerting.
Three (and a half) ways to handle alerting
1. Don’t page anyone at night
Not all alerts need to wake someone up, and you should be cautious about creating opportunities to page someone. If the response to an alert can be handled during business hours, route alerts to a Slack channel instead. This keeps people calm, and allows them to engage with the alert in a way that is less disruptive to their lives.
2. Page the on-call engineer for every single alert
You can opt to page the on-call for every service involved, every time. People tend to bristle at this, and for good reason! Getting woken up at night is rough and contributes to burnout.
There’s a more insidious problem present here: paging everyone will cause friction between the teams that respond to pages. If one team is usually responsible (or perceived as responsible), then other teams will, at best, ignore pages—and at worst, will make things difficult for the scapegoat team. This brings us to option three.
3. Investigate first, then bring in others as needed
Pick a team and have them do the initial investigation, then bring other teams in as needed. This minimizes the number of people involved at first.
If you proceed with this option, it’s important that there’s a clear protocol for teams to hand each other the pager responsibility: if a team believes that the page should go somewhere else, there needs to be a way for that to happen. Avoid this route if your organization has a hard time adjusting alerts that are too noisy or don’t provide value.
Another problem lies in paging teams that have deep context of their own services, but can’t see the broader picture. Therefore, instead of paging one of the teams responsible for the SLO, you page a rotation of SREs. We call this the “switchboard” pattern. This way, you can identify when the problem lies in the interaction between the services.
This option highlights the need for SRE teams. As your organization grows, your ownership model will solidify, and your teams will become more independent. To compensate, you need to add teams that can take a more global view of the system.
Automation
It’s tempting to solve this problem with automation. Some tools are able to aggregate alerts, where they can route alerts by synthesizing many different signals. If you have access to this kind of tooling, great!
At the end of the day though, you are still picking a group of people to page, you’re just using more signals to determine who that group is. In cases where the failures are novel, you’ll have to have a fallback defined; the discussion above still applies. Define your fallbacks with care, and ensure that your automation gives you the results you expect.
The importance of measuring the user experience
Creating SLOs that match the user experience and properly alerting based on them takes time and effort. It can take time to see positive results, and there are many pitfalls along the way. In a world where you only have alerts tailored to a specific service, it can be tough to assess the impact of any of the pages you receive. If latency is up in your service, does that mean users are currently impacted? Do you need to wake someone up for this alert?
By alerting on the user experience, you create alerts that can give you more confidence that something worth paging about is happening. By synthesizing a user-impacting page with other information (such as service-specific alerts going off), you can form a clearer picture of the incident in less time.
A Real Example: E2E Alerts
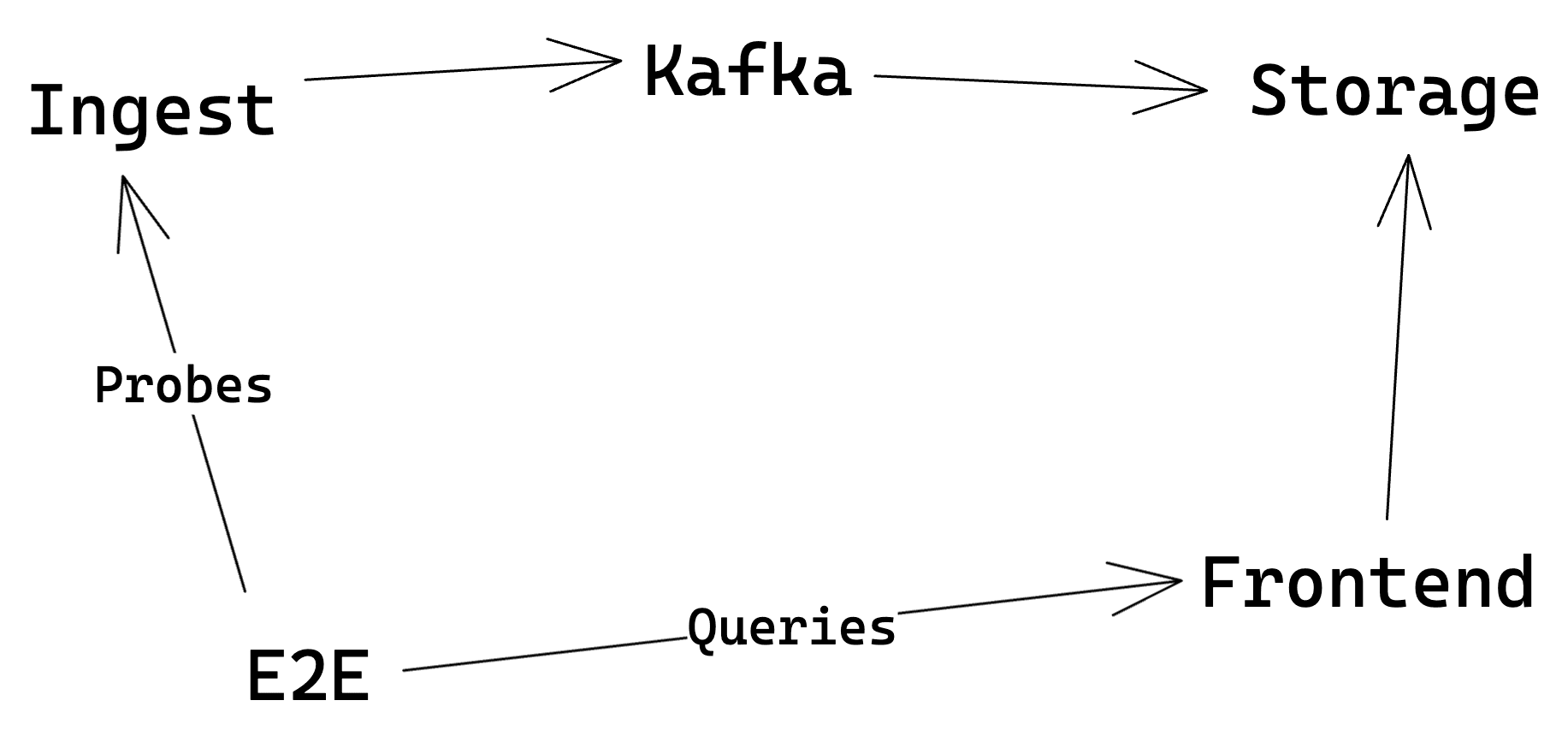
Here’s a concrete internal example: our E2E monitor. We’ve discussed this system before, but here’s the TL;DR:
At Honeycomb, we want to be confident that users can access the data they send us. We monitor this with a service that constantly writes data to our ingest service, then asserts that it is later able to query that data. If it can’t query the data after some time, it fails, and it pages the on-call engineer on our platform rotation.
The services involved are outlined in the illustration above, but it’s worth calling out that each “box” in there has its own challenges with regards to ownership. Different teams own different services—and with over five teams involved with E2E, it’s entirely possible for any of them to accidentally break the service.
So, who do we page?
For E2E, we picked the switchboard pattern. We page the combined SRE/platform on-call rotation. These are members of the organization with a lot of knowledge and experience, and they are typically well equipped to find and fix issues. In a recent case of flapping E2E alerts, we eventually had to bring in senior members of the storage team, who found and fixed a very subtle cache bug deep in our storage engine.
This situation works for our current needs, but it might not work for us long-term. At Honeycomb, everything is an experiment—and if we need to change this structure, we will.
This is a hard problem with no easy solution
While this post can give you a good starting point on alerting, ultimately, you know best. Solving this problem is going to involve an understanding of your organization’s culture and the kinds of solutions they’ll be amenable to. Honeycomb fits the bill well with our debuggable SLOs. I invite you to sign up for our free tier and see how we can make on-call engineer lives better.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.