One Year of Graviton2 at Honeycomb
A year ago, we wrote about our experiences as early adopters of Graviton2, and how we were able to see 30% price-performance improvements on one dogfood workload from switching to the arm64 architecture. In…

By: Liz Fong-Jones
A year ago, we wrote about our experiences as early adopters of Graviton2, and how we were able to see 30% price-performance improvements on one dogfood workload from switching to the arm64 architecture. In those initial experiments, we validated running 20% fewer shepherd ingest workers, using the m6g instance type, which cost 10% less per instance compared to c5 instances. We didn’t need to change any of Honeycomb’s go codebase to port it to arm64, only needing to update our continuous integration pipeline to create build artifacts for different architectures. (A quick refresh: Honeycomb consists of our ingest workers [called “shepherd”], Kafka, query workers [“retriever”], and frontends [“poodle”]. We also run a “dogfood” copy of these services for analyzing telemetry from the production cluster.)
As part of our proof-of-concept work, we made significant operability and manageability improvements to our base Amazon Machine Image and Chef recipes. And we shared our improvements with the world by testing and releasing for the first time arm64 compatible native agents such as our own honeytail, honeyvent, and Refinery. We ensured community projects such as osquery and the OpenTelemetry Collector were tested and built on arm64 out of the box, to benefit future arm64 adopters.
In May, once the m6g general-purpose instance types went generally available with Honeycomb as a launch partner, we began to scale out our ingest workload in production using Graviton2. With the launch of c6g compute-focused instances in June, and the availability of m6g and c6g in all the availability zones we needed later that fall, our savings on ingest rose to over 40% versus c5 when comparing spot-to-spot and on-demand to on-demand. But we certainly weren’t going to stop with just one workload after investing in the capability to run any of our workloads on Graviton2.
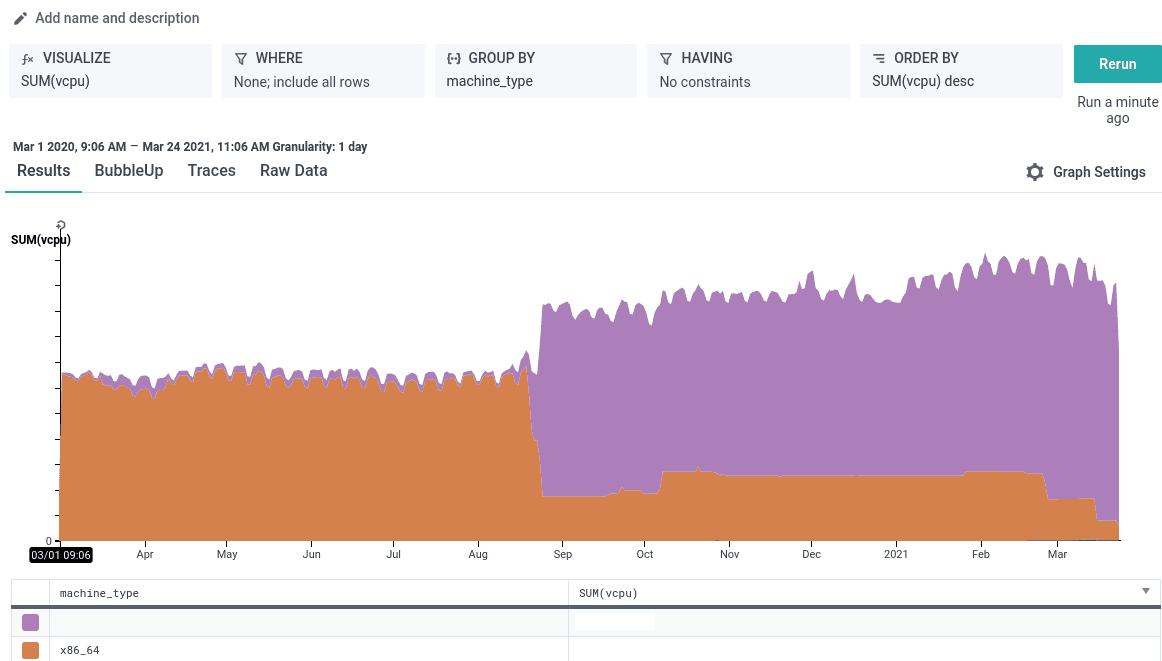
A year out from our initial Graviton2 dogfood experiments, we can report that 92% of vCPUs in use by Honeycomb are arm64, spanning virtually all of our workloads and all of our environments. The investment we put into tooling for service standardization paid off, as we were able to push-button migrate multiple individual services over the year with a minimum of service-specific wrangling. The change to Graviton2 has been transparent to all of our developers, and in fact, having already deployed arm64 in production has ensured the transition to M1 Apple Silicon Macs has been smooth for our development team’s local testing.
Traffic to Honeycomb has surged in the past year, but the expense for serving and the complexity of our services hasn’t. Graviton2 is a large part of how we do it. We proactively were able to double the number of threads (and dramatically improve the performance per thread) available to our “retriever” query engine when we switched from i3.xlarge instances to m6gd.2xlarge instances, without needing to double the cost. We’ve profiled our new Refinery sampling agent on both Intel and Arm instances for our own dogfood workload. We can wholeheartedly recommend Graviton2 given that the same size Refinery cluster runs cheaper and at higher throughput on Graviton2. Furthermore, we include support for Refinery with Honeycomb Enterprise plans, no matter which architecture you’re using.
We hope that sharing our trail-blazing experience has inspired you to try Graviton2, whether you’re a Honeycomb customer or not. (If you haven’t yet, you can sign up for a free Honeycomb account and get started today.) End-user visible latency, throughput, and cost are important dimensions to optimize. And if you are a Honeycomb customer, we’re Graviton Ready Partners here for the transition right alongside you with agents and real-word experience with performance optimizations for the platform. Honeycomb can tell you where the performance bottlenecks are, and Graviton2 is an easy win for compute-bound workloads once you’ve identified the bottlenecks.
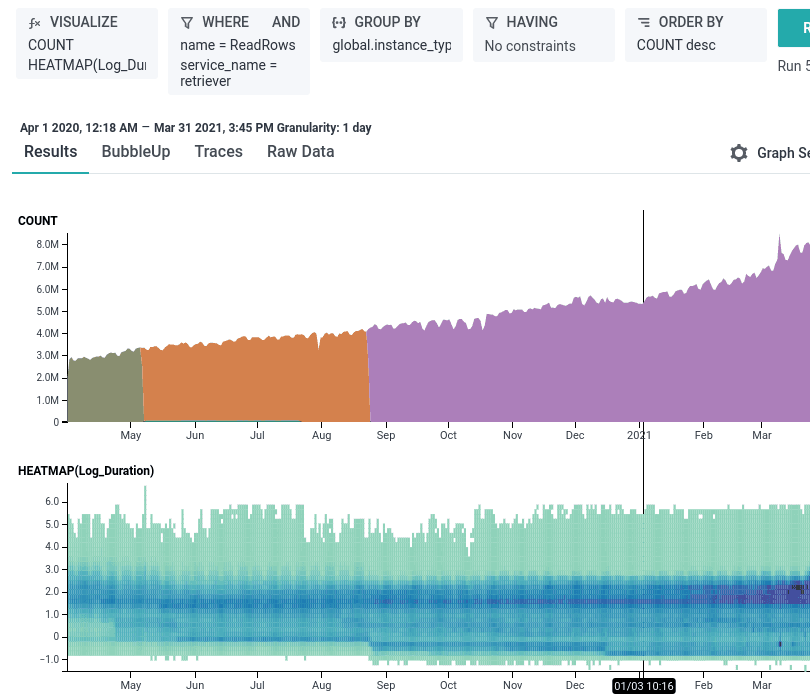
Keep an eye out in the next few weeks for a blog where I’ll show how Graviton2 instances enabled us to serve more than double the traffic from customer queries, triggers, and Service Level Objectives (SLOs) on the same number of shards while keeping reliability, latency, and cost about the same! Here’s a sneak peek of one of the queries:
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.