Scaling Ingest With Ingest Telemetry
With the introduction of Environments & Services, we’ve seen a dramatic increase in the creation of new datasets. These new datasets are smaller than ones created with Honeycomb Classic, where customers would typically place all of their services under a single, large dataset. This change has presented some interesting scaling challenges, which I’ll detail in this post, along with the solution we used, and how we leveraged Honeycomb’s own telemetry to scale Honeycomb.

By: Nathan Lincoln

With the introduction of Environments & Services, we’ve seen a dramatic increase in the creation of new datasets. These new datasets are smaller than ones created with Honeycomb Classic, where customers would typically place all of their services under a single, large dataset. This change has presented some interesting scaling challenges, which I’ll detail in this post, along with the solution we used, and how we leveraged Honeycomb’s own telemetry to scale Honeycomb.
In Honeycomb, events are organized into datasets, which typically correspond 1:1 to services. Our ingest service, upon receiving an event, forwards it to Kafka. Each dataset is assigned to several Kafka partitions, and incoming events are evenly distributed among the assigned partitions. Balancing load among these partitions is one of the responsibilities of the SRE team at Honeycomb. If a customer begins sending us more data for a given dataset, we scale them out by adding more partitions to their assignment.
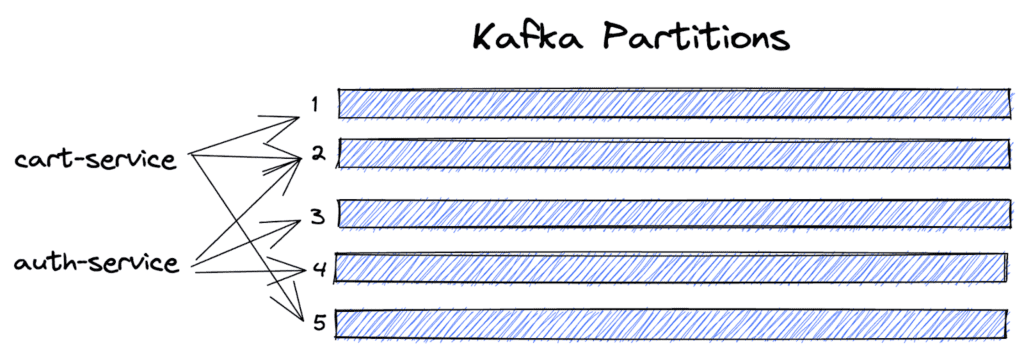
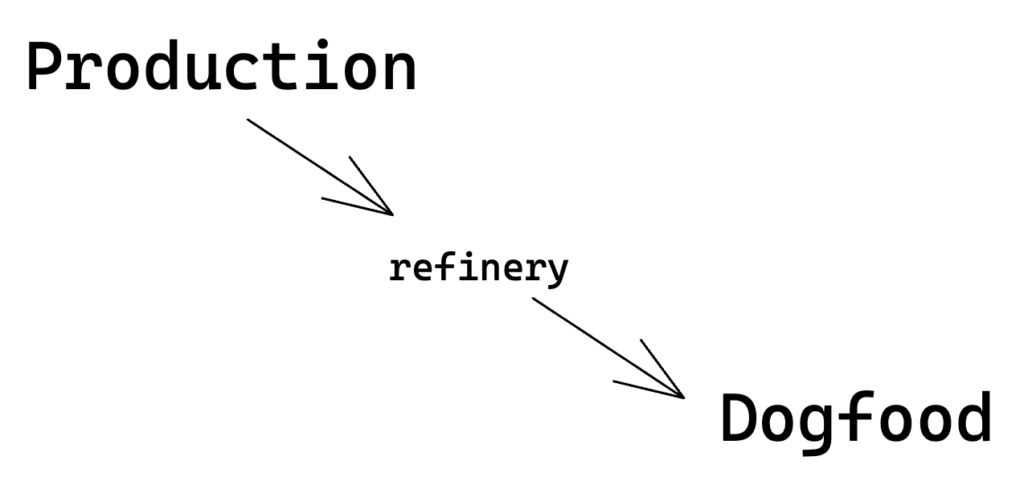
To gain observability into our ingest traffic, our ingest service emits to our dogfood Honeycomb instance for every event ingested. This telemetry contains information about the dataset the event is for, the Kafka partition the event was sent to, and the number of Kafka partitions assigned to that dataset. We use a Refinery instance to intelligently sample this traffic.
At Honeycomb, we consider a partition to be overloaded when too many events are being sent to it and we need to move incoming load over to other, less-burdened partitions to ensure the health of the system. This begs the question: how do we shift that incoming load?
One way would be to remove a dataset from that Kafka partition, causing future traffic to go to the remaining partitions. However, that runs the danger of overloading other partitions that now have to receive that load. A safer option would be to expand the datasets partition assignments to include another underloaded partition, thereby taking some of the traffic off of the overloaded partitions.
How, then, do you find the correct dataset to expand? SRE Fred Hebert developed a measure called the “Fractional Partition Weight” of a dataset.
We created a derived column for the telemetry our ingest service sends to our dogfood environment, called dc.fractional_partition_weight. This column was defined to be 1/num_partitions, and by summing up this value over a time period, we get events_sent_over_time_period/num_partitions. Scoping this value to a given Kafka partition will give us a rough measure of the amount of traffic that will be moved off of it.
Let’s dig into the solution
Let’s build up some intuition for why this measure works well. A first attempt at solving the problem might be to choose the dataset that is currently sending the most traffic to the overloaded partition. However, if that dataset already has a lot of Kafka partitions assigned to it, then adding one more will only move a tiny fraction of traffic off the overloaded partition.
This seems counter-intuitive, so I want to spend a bit more time on it. Since load is evenly distributed over all available partitions, the new partition will receive traffic that is “skimmed off the top” of the old partitions. For a dataset with three partitions, we’d end up skimming 25% off of each partition. However, if the dataset has 50 partitions, we’d only end up skimming 2% off of each partition.
If we want to get linear decreases in partition traffic, we’ll have to compensate for the diminishing returns by making exponential increases to the number of partitions for the dataset. Moving from one partition to two will decrease traffic by half, but to decrease traffic by half again requires moving to four, then eight, then 16, and so on. This is why we prefer datasets that have a lower number of partitions: early on, linear increases have more impact.

We’ve found good signals for determining when Kafka partitions are overloaded, and a good signal for which datasets to expand in order to efficiently move traffic off of the overloaded partition. For a long time we would rely on boards or handcrafted queries to determine what action to take, and then move over to an admin UI in order to make the changes. This worked fine in the Honeycomb Classic world, with its large monolithic datasets. In the Environments & Services world, however, we would be making these changes for multiple datasets at a time, creating toil for our on-call person.
To address this, we made some improvements to a tool we developed a year ago to automate some of the steps in expanding a datasets partitions. While the original version of this tool was able to make some recommendations, it was built before we developed the Query Data API. This meant that the data source we used to feed those recommendations didn’t have the full set of data we had available in our dogfood environment, and its recommendations weren’t trusted as a result. By changing the tool to request data from our dogfood Honeycomb instance via the Query Data API, we greatly improved the trust users have in the tool to make good recommendations.
Scaling: the solution to many of life’s problems
Scaling out partitioned setups can come with some subtleties. While small changes at a small scale can have large impacts, those same changes will have a tiny impact once you’ve reached a large scale. Instead of relying on limited data collected in production environments, using the Query Data API can allow you to distill insights about how to operate your services into your tooling.
Interested in trying Honeycomb? Get started with our very useful free tier today. We’re recently added new features, such as a Service Map and enhancements to BubbleUp, that are available now!
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.