Scaling Kafka at Honeycomb
When you send telemetry into Honeycomb, our infrastructure needs to buffer your data before processing it in our “retriever” columnar storage database. For the entirety of Honeycomb’s existence, we have used Apache Kafka to…

By: Liz Fong-Jones
When you send telemetry into Honeycomb, our infrastructure needs to buffer your data before processing it in our “retriever” columnar storage database. For the entirety of Honeycomb’s existence, we have used Apache Kafka to perform this buffering function in our observability pipeline.
In this post, we’ll review the history of how we got here, why we’re so picky about Kafka software and hardware, and how we qualified and adopted the new AWS Graviton2-based storage instances. Lastly, at the end of this post, we’ll discuss the decrease in price per megabyte of throughput after the cumulative optimizations we’ve made in the past two years. Let’s dive in.
A brief overview of Kafka at Honeycomb
Using Apache Kafka to buffer the data between ingest and storage benefits both our customers by way of durability/reliability and our engineering teams in terms of operability. This improved operability helps us scale to meet demand and to innovate more quickly by shipping to each service, even our stateful ones, a dozen times per day.
How does Kafka help us achieve these results? First, Kafka has well-audited, battle-tested mechanisms for guaranteeing ordering and persistence of individual messages, allowing us to not spend innovation tokens on writing our own Paxos/Raft implementation or worrying about low-level filesystem flushes in our ingest workers.
Second, Kafka ensures that multiple readers, such as redundant retriever nodes responsible for a given partition or beagle nodes computing Service Level Objectives (SLOs), can be in agreement about the data they are receiving.
Third and finally, using Kafka allows us to decouple the stateless “shepherd” ingest workers from the stateful “retriever” storage engine, allowing us to perform rolling restarts and updates without causing downtime for our customers.
AWS recently announced that the Amazon EC2 Im4gn instance family, powered by AWS Graviton2 processors, is now generally available, and we’re excited to adopt it as the next generation that will power our Kafka clusters for the coming years. It also represents the last workload we had to make architecture-agnostic—each service at Honeycomb is now capable of running at production scale across both amd64 and arm64 platforms.
Adapting Kafka for our use case
There are many Kafka implementations available for self-hosting, including the pure Apache-licensed Apache Kafka, Confluent’s Community Edition distribution, Cloudera’s DataFlow product, and even RedPanda, a scratch backend rewrite in C++ that is client API compatible. Kafka as a managed service also exists in the form of Amazon Managed Streaming for Apache Kafka (MSK), Confluent Cloud, and others. Instead of using a managed service, we’ve chosen to build expertise in-house, treating outages as unscheduled learning opportunities rather than reasons to fear Kafka.
In the words of our platform engineering manager, Ben Hartshorne, Kafka is the “beating heart” of Honeycomb, powering our 99.99% ingest availability SLO. It would not be acceptable for us to leave our customers in a degraded state until a vendor responded to a support ticket or have our Kafka topics locked into a vendor’s hosted brokers forever. However, this didn’t necessarily mean doing all the packaging ourselves, so in July 2019 we did a rolling restart to convert from self-packaged Kafka 0.10.0 to Confluent Community 5.3 (Kafka 2.3), making our future validation and upgrade path easier.
Sizing Kafka appropriately is a challenging but important question to us as it represents a significant infrastructure expenditure and driver of Cost of Goods Sold (COGS). Kafka needs to be tuned to store the correct amount of data and needs to be fed with appropriate network, memory, and compute. Historically, our business requirements have meant keeping a buffer of 24 to 48 hours of data to guard against the risk of a bug in retriever corrupting customer data. If we caught a bug within a few days of release, we could replay and reconstruct the data to preserve data integrity. Besides the long-term data integrity use case, we also make use of a shorter-term recall within the window of data buffered by Kafka as part of ordinary operations.
When we restart a retriever process to deploy a new build, we preserve the data it has on disk, but it will need to replay the data written in the few minutes while it was down. And whenever AWS retires an instance that retriever is being hosted on, we need to get that node caught up to speed from scratch. A new retriever node simply needs to obtain the latest hourly full filesystem snapshot of its predecessor, along with the Kafka offset that the snapshot was taken from. Then, it connects to Kafka and replays for at most two hours, starting from the offset forward to the present. Since instance failures are rare, we also deliberately exercise this buffer and validate our disaster recovery plans by terminating and replacing one retriever node per week.
But the case of needing to replay days of data is rarely exercised, whereas we need the data from the past hour back very quickly if we’re trying to get a new retriever node caught up. But maybe there is a better solution than spending hundreds of thousands of dollars per year on storage and CPU we weren’t going to use except in case of emergencies. Thus, over the nearly three years I’ve been at Honeycomb, we’ve evolved the instance configurations powering our Kafka cluster three times, each time balancing performance, cost, and utilization against the best available hardware at the time.
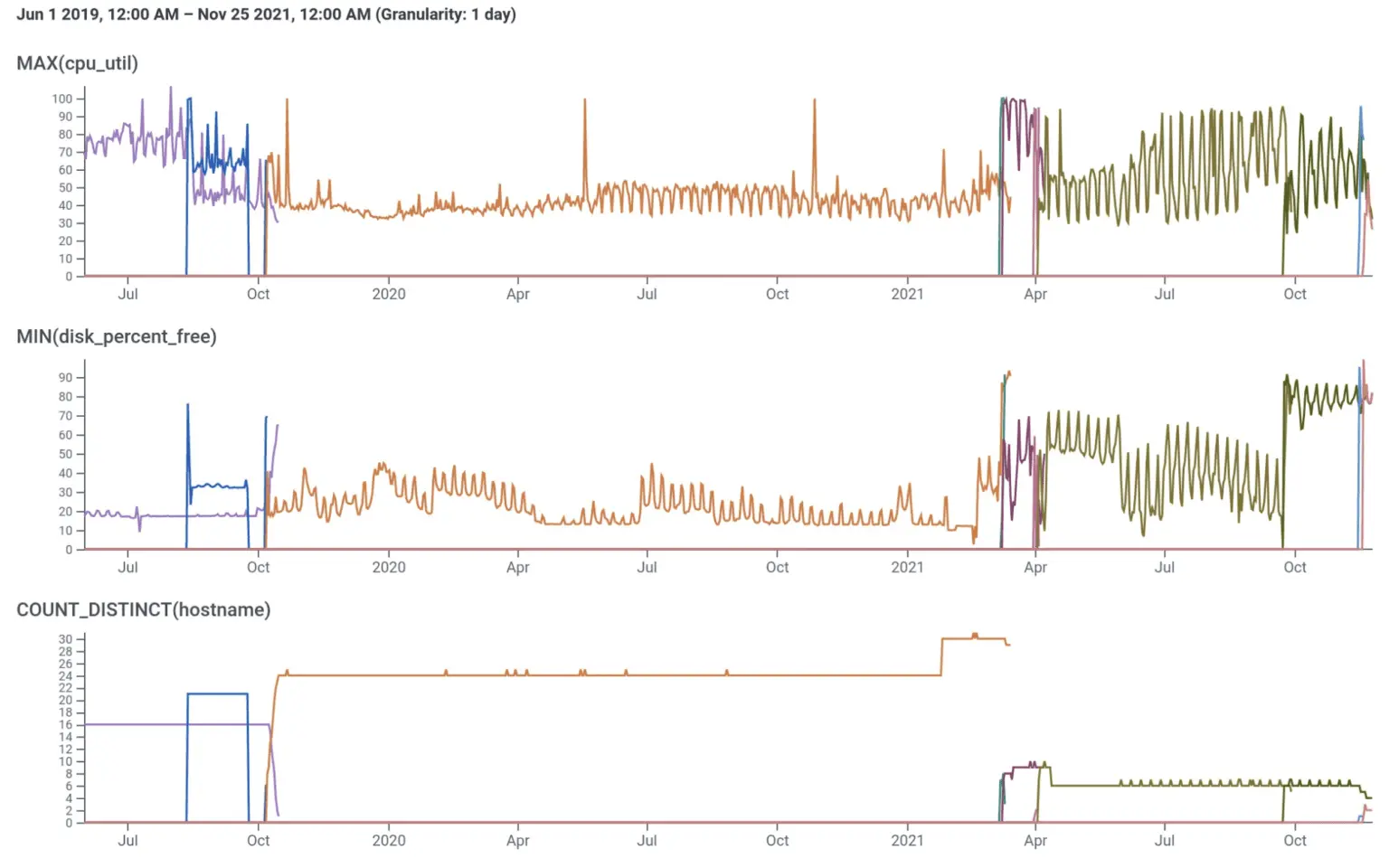
Earlier evolutions of our Kafka cluster
Prior to July 2019, we had been using 16 c5.xlarge instances as our Kafka brokers, saturating 80% of the CPU on each, and using gp2 EBS storage with disks sized appropriately to also utilize 80% of their capacity. However, there were three significant drawbacks:
- That gp2 block storage had uneven tail latency for our workload
- That gp2 was very expensive at 10c per GB-month, without the possibility of committed use discounts, and
- That EBS forced us to pay for even if we didn’t utilize the durability and persistence of volumes independent of instance hardware. So instead of reusing broker identity across physical hardware, we destroyed and recreated new volumes using Kafka’s own replication mechanisms (after all, EBS volumes also do sometimes fail, so it’s safer to never assume EBS will survive instance replacement).
In August to September 2019, we began the “spinning rust” experiment—to use sc1 or st1 EBS hard disks (which cost only 2.5c per GB-month) to provide the majority of our longer-term archival and to keep only the latest few hours of data on the NVMe instance storage of 21 i3en.large instances. At the time, however, the Kafka software itself had no awareness of tiering, so we needed to use LVM block caching to do the tiering. The results were suboptimal with p99.9 latency far in excess of our tolerances whenever the LVM pool was pending a flush to or from HDD. We also stumbled head-first into the pain of EBS “burst balances” in which AWS would let us exceed the IOPS of the disk temporarily, only to cause reliability problems by pulling the rug several hours later once the burst balance exhausted.
Given that that cost reduction experiment hadn’t worked, we became resigned to keeping all 24-plus hours of data on SSD. But that didn’t necessarily mean we had to continuously pay for gp2 storage. Our calculations showed that with purchase of Reserved Instances or a Compute Savings Plan, that it would be cheaper than EBS on a cost-per-gigabyte basis to use the instance storage on i3en.xlarge instances (8c per GB-month) and would also give us the CPU and RAM to run the brokers “for free.” So in October 2019, we scheduled a migration from the 16 c5.xlarge instances onto 24 i3en.xlarge instances. This configuration proved stable for the following year, consistently utilizing 40% of the CPU across the brokers and providing low single-millisecond produce times for our shepherd ingest workers (better latencies than we saw with gp2).
But as Honeycomb’s business grew, we found that our 48 hours of safety margin first shrank to 24 hours, and then less than 20 hours of space on disk (at 85% utilization to avoid write amplification). Even with the decrease in bandwidth and disk size from using Zstandard compression, our clusters were struggling to keep up. The toil of handling reassigning partitions during broker replacement by hand every time one of the instances was terminated by AWS began to grate upon us. We knew we’d need to buy ourselves both time in the short term by increasing the size of the cluster by 25%, to a total of 30 brokers, as well as explore better long-term solutions.
Confluent tiered storage frees us from being storage-bound
In October 2020, Confluent announced Confluent Platform 6.0 with Tiered Storage support. This promised a supported, tested solution rather than the hack we’d explored in August 2019. We could significantly shrink our cluster to hold on local NVMe SSD only the latest two to four hours of data corresponding to our usage pattern, get better CPU and network utilization of the very expensive i3en instances, and pay only two cents per GB for the deduplicated older data, which had been archived to S3.
As a bonus, tiered data is only stored once on S3 rather than consuming SSD on all three replicas (e.g., 24 cents per input GB in total). If we needed older data off Kafka, we could replay four hours of data per hour. And Confluent’s built-in deployment of LinkedIn Cruise-control rebalancing would ease our toil (and improve safe utilization through leveling out load imbalances). The subscription fee would easily be paid for with our projected near-term savings, with more savings over time from not needing to expand our broker pool as much as our data volume grew.
Our initial thought was to try the combination of newly announced gp3 EBS with the Graviton2 instances we know and love to truly decouple storage and compute sizing, and allow us to independently control each. Perhaps our earlier experiences with gp2 had been solved by the new generation of storage. And we knew that Graviton2 offered great price-performance improvements overall. Running the Confluent Platform distribution of Kafka was straightforward on Graviton2 because Kafka is a JVM app (Java+Scala), and its JNI dependencies already had arm64 native shared libraries packed with it. After resolving the obvious performance low-hanging fruit (needing to use libc6-lse and the Corretto Java distribution to eliminate futex thrashing), we had Kafka running on Graviton2. This was going to be an easy win and case study for the AWS and Confluent blogs, right?
After validating the technology in our dogfood environment in November and contract negotiations in December, we began deploying it in production in February 2021. Unfortunately, our dogfood results were too good to be true. As we were the first to deploy at scale Kafka on Graviton2 and gp3, we encountered saturation dimensions we’d never hit before (and thus weren’t measuring) and tickled hypervisor and storage reliability bugs. Even after switching to c6gn.xlarge instances for more compute and network bandwidth in production (prod) than the m6gd instances we’d used for the dogfood proof of concept, we couldn’t get the stability we needed. Despite the best efforts and partnership of the Confluent and AWS teams, we couldn’t make it work for us. It was time to go back to boring and revert to temporarily running 9x i3en.2xlarge as our base platform for tiered storage.
By April 2021, we had stabilized the system and were able to consolidate onto 6x i3en.2xlarge, with older data tiered to S3. The catch was that Confluent licensing costs were per steady-state broker, so we needed to move to vertical scaling for our future growth needs. As you can see in Figure 1, we began to saturate the CPU and networking of the i3en.2xlarge instances in July (especially during rebalances), and by September it was clear that we needed to upsize to .3xlarge. Even after resizing, some of the nodes in the Kafka cluster were showing over 50% CPU utilization during weekday peak traffic, indicating that we did not have headroom to scale with Honeycomb’s growth. This pattern was not at all sustainable for us, as we’d soon need .6xlarge instances or to expand the cluster to nine brokers with a corresponding increase in our license fee to Confluent, or both.
AWS innovation enables us to scale at lower cost
Fortunately for us, the AWS team invited us to preview the Is4gen and Im4gn instance types earlier this month (November 2021). It was time to review our requirements and see how those instances squared against our existing configuration and potential alternative configurations.
For us, Kafka is a compute-intensive workload (requiring at least 12 Intel cores per instance at our current traffic levels) and high network bandwidth (12.5 Gbps burstable to 25 Gbps). Because of our use of tiered storage, we only were using 1.5T of NVMe per broker, despite having 7.5T available per instance on i3en.3xlarge. We were already stretching the limits of i3en.3xlarge on every dimension except the amount of SSD provided as instance storage. And we were still growing.
Thus, we knew that to serve double the traffic per instance, our next generation of Kafka brokers would need to have at least 3T of storage, 16 Graviton2 or 20 Intel cores, and 25 Gbps networking. In addition to i3en.6xlarge and im4gn.4xlarge, we also considered c6gd.12xlarge (48 cores, 96G ram, 2.8T SSD, 20 Gbps)—which would be price uncompetitive—strand CPU, and saturate network at a lower threshold.
We’d already (thanks to our earlier 2020 experiments) validated that Confluent Kafka ran on Graviton2, so it was simple to rebuild the AMI from our previous Packer recipes and boot it up. After a brief stress test of one is4gen.2xlarge instance in prod to push its limits (test passed, 50%-90% cpu utilization, no latency degradation, but we didn’t want to double the load from there), we set two out of three of our Kafka brokers running im4gn.xlarge in dogfood, and two out of six of our Kafka brokers running im4gn.4xlarge in production.
That last step was critical to us given our hard lessons from January 2021 in which a configuration failed the critical test of production traffic even though we thought we’d performed exhaustive testing in dogfood. Yes, there was risk involved, but given our replication factor of three, we knew we could tolerate losing the experimental instances without damaging uptime or durability. After all, we already terminate Kafka instances every week, just like we terminate retrievers, so we can continuously verify that our automation works and there is enough headroom to replace nodes. And if things do go wrong, we’d rather find out when our team is at work paying close attention.
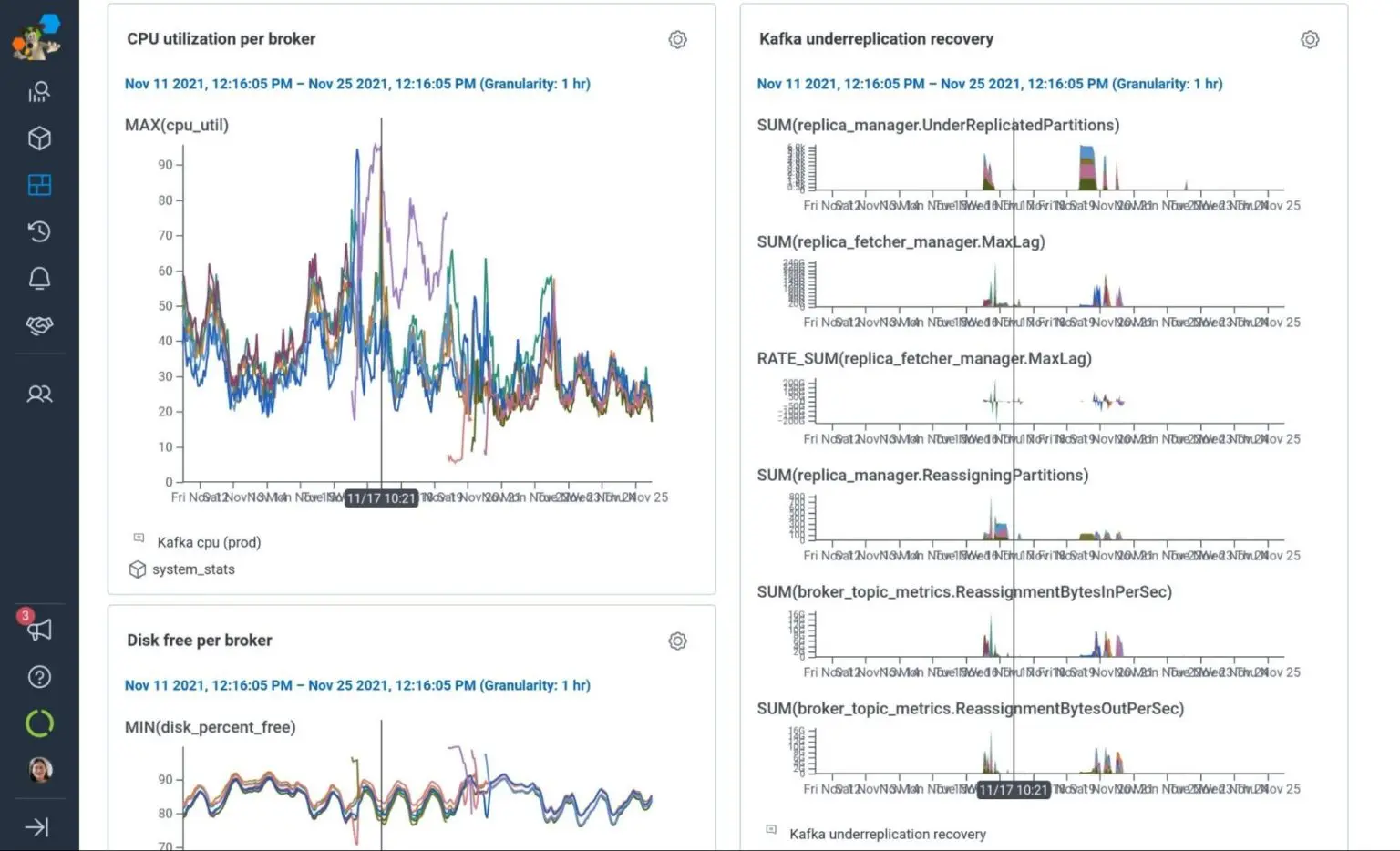
Our experience during the preview program showed that im4gn.4xlarge was able to give us the best possible scalability and future-proofing. For our current workload, im4gn.4xlarge runs at 30% peak CPU utilization, 20% disk utilization, and can sustain without network throttling the Kafka message bursts that occur during peak traffic or broker loss/replication. It is twice as fast to replicate in and restore full redundancy compared to i3en.3xlarge instances. And it costs only 14% more than our current i3en.3xlarge instances (and is 43% less expensive than the i3en.6xlarge we’d otherwise need to upsize to soon).
Conclusion
By giving us the right ratio of compute, SSD, and network throughput, Im4gn is the most attractive instance family to us to sustain our long-term growth. In the 4xlarge size, it has guaranteed (e.g., not just burst w/ half that as steady-state) 25 Gbps of bandwidth, plenty of CPU (utilizing its 16 more efficient Graviton2 cores), and 7.5T of instance storage. We believe we’ll be able to scale our traffic over the next 6-12 months using this instance type before needing to further vertically or horizontally scale.
We hope hearing how we managed our Kafka-based telemetry ingest pipeline is helpful to you in scaling your own Kafka clusters. We’ve grown 10x in two years while TCO1 for Kafka has only gone up 20%—in other words, an 87%2 cumulative reduction in cost per MB of incoming data. We do not have any engineers dedicated full time to the care and feeding of Kafka, and have preserved about the same number of engineers fluent in Kafka debugging as needed through training with incidents. This means our toil has not significantly increased even as the data scope increased.
But if you’re thinking about building your own telemetry ingest and indexing pipeline, our advice to you is to not reinvent the wheel. We are experts in this, and we have figured out a ton of tricks for making it reliable and efficient, in partnership with the AWS and Confluent teams. Let us manage your observability ingest and visualization, giving you the economy and scale of Honeycomb’s backend and the insight of Honeycomb’s frontend. Discover your unknown unknowns from day one, rather than starting off deep in the hole of technical debt from fighting with Kafka. Sign up for a free Honeycomb account today to send up to 20 million trace spans per month as long as you like, and we’ll grow with you all the way up to trillions of events per year with Honeycomb Enterprise.
1Inclusive of compute, storage, and licensing costs, but excluding cross-AZ network costs.
2Breakdown: 25% savings from Zstandard, 20% savings from c5+gp2 to i3en reserved instances, 65% savings from tiered storage, and 43% savings from i3en to im4gn. These add to more than 100%, because cumulative savings is 1-(1-X)(1-Y)(1-Z)… rather than X+Y+Z.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.