NS1 Implements Honeycomb to Democratize Their Code and Spark Customer Joy


The line from observability to customer joy is straighter than you think. We recently learned this from NS1, a managed DNS provider and Honeycomb customer, in a panel discussion with Nate Daly, Head of Architecture at NS1 and Chris Bertinato, Software Architect at NS1.
DNS is all about speed and reliability. “We aspire to have the fastest, most reliable API in the industry,” explained Nate. “We work with customers who need real-time control over their traffic, and they control us controlling their traffic through an API.” As NS1 continued to grow, they needed to be able to identify issues quickly and right down to the individual customer level so they could be resolved before causing any customer latency. That’s where Honeycomb for observability, and particularly SLOs, came into play.
A brief detour: What are SLOs again? And why do we care?
SLOs—service level objectives—provide a common language between business stakeholders and engineers. They help tie engineering and product decisions to customer outcomes. Honeycomb SLOs allow you to set configurable alerts for what matters most to your customers, so you can identify and resolve issues before they result in downtime for customers. Most of the time, they won’t even notice.
SLOs also help you decide where to focus precious engineering resources, based on what your customers value. Should you work on service availability or add a new feature? What has the biggest effect on the bottom line? These are conversations everyone—businesspeople, engineers, the office manager—can get behind.
SLOde to joy
Back to NS1. NS1 doesn’t want to be a managed DNS provider. They want to be the best managed DNS provider. That means setting SLOs that go way beyond the table stakes of just being up and running.
NS1 uses Honeycomb SLOs in a way “slightly different from the usual fare,” said Nate. “The SLOs we’re starting with from Honeycomb don’t represent customer pain if you violate them. Instead, they represent less customer joy than we intended.” This means that NS1 can see a potential issue developing and stop it dead in its tracks before it turns into a customer-noticeable problem. Their approach is all about making their customers happy all the time, not just making them happy again after something goes wrong and they fix it.
To achieve this, they first started by creating latency goals and burn alerts per endpoint and per http method in their API. These goals match current performance. They act as a net that keeps them from falling into the slow-erosion-over-time trap. “Now when we do a deployment, we can see pretty instantly if we’ve regressed on performance and where specifically we’ve regressed. And we can decide whether to roll something back or close out the scope of work.”
With that baseline in place to stop any bleeding, they’re setting percentage improvement targets toward performance optimization—little things that make a big difference to customers.
Embrace the hotness
Speaking of deployments, NS1 also began utilizing Honeymarkers to pinpoint exactly when they shipped a new release. Honeymarkers let users annotate their timelines so they can see if a recent deployment had a negative impact.
Chris Bertinato shared a story about how Nate made one of those small improvements that are the backbone of NS1’s approach to performance optimization. He himself described it as “the hotness,” and who are we to judge?
When Nate tried to see the improvement in Honeycomb, all he saw was that vast empty space to the right.
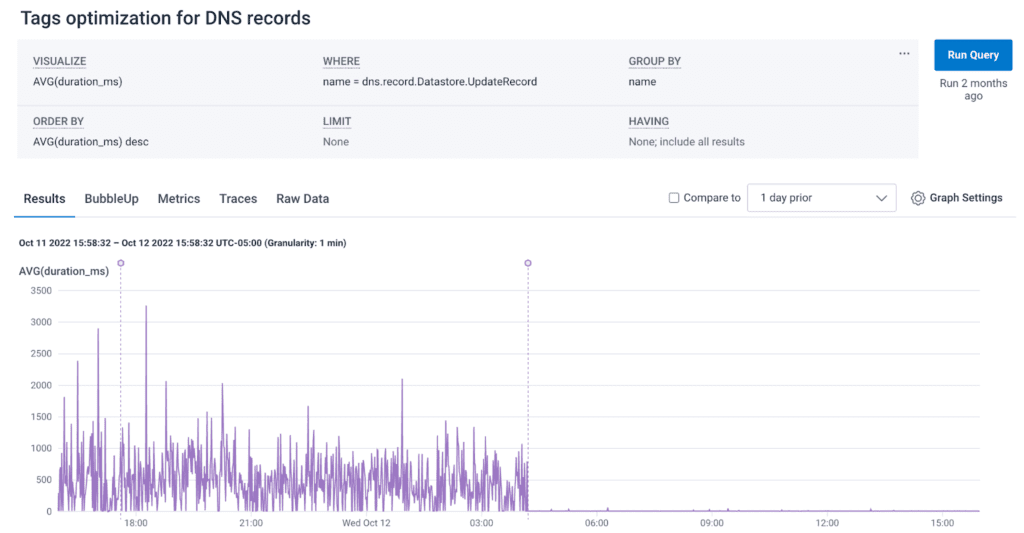
Nate described this experience: “I thought Honeycomb must be broken. It went from obviously doing something to not doing anything. Chris told me, ‘Nope, the team made a change to the tags implementation and it’s just that fast now.’ BS, I thought.”
So, what was up? Once Chris asked Nate to turn on deploy markers, Nate saw that the moment they deployed, the graph flatlined. And in this case, flatlining is a good thing—the hotness, even.
“This represents one of the valuable pieces of Honeycomb to us,” Nate shared. “I see the possibility for us to get to a kind of utopia where the Honeycomb artifact is used both as a demonstration that there is a problem and that it was solved.”
Democratized code
Anyone looking at that graph can see that something has changed. The same is true of Honeycomb Heatmap or BubbleUp visualizations that show anomalies and outliers. Because Honeycomb can take thousands of lines of code and huge amounts of event data and distill it down to easy-to-read, simple-to-query visualizations, anyone can see what’s going on with the system without having to be an expert in the code, or even a developer.
This democratizes the process of identifying potential issues. “At a certain point, the complexity exceeds the capacity of individual engineers to effectively trace through by hand and figure out where bottlenecks and things are,” Nate explained. “But along with improving our ability to do that, we’re trying to improve our ability to garner generic internal agreements between teams that line up with the business superlatives for this service.” This empowered NS1’s product and customer success teams to be able to identify issues and alleviate some of that burden from the developers, freeing up their time to work on what they like to work on the most: building and innovating.
Many good tech decisions start with Honeycomb
There was a moment when NS1 thought of creating their own distributed tracing system, before someone who had experience with Honeycomb recognized the madness. Honeycomb saved them the trouble and the danger—this blog touches on the build vs. buy debate. TL;DR: for most organizations, Honeycomb is the right choice if the goals are cost savings, increased revenue, and happier (more joyful?) engineers. Forrester Consulting thinks so, too.
NS1 customers also benefit. Nate told another story about a customer they recently upgraded to a newer, spiffier platform. Unfortunately, the customer didn’t see the value right away, but after using Honeycomb to identify where tweaks and adjustments needed to be made, NS1 was able to bring back that customer joy. “I told them that the reason we had this fixed so quickly was because we use Honeycomb. We have the core systems instrumented for distributed tracing, and it was obvious where the issue was. They said, ‘Oh, you use Honeycomb too?’”
“The most valuable thing I said in that 45-minute call is: we use Honeycomb. What our customer heard is that we make good tech decisions, just like they do.”
Want to learn more about the path from SLOs and observability to customer joy? Check out this blog where we get into effective SLOs and observability. If you want to give Honeycomb a try, sign up to get started.