From Oops to Ops: SLOs Get Budget Rate Alerts
As someone living the Honeycomb ops life for a while, SLOs have been the bread and butter of our most critical and useful alerting. However, they had severe, long-standing limitations. In this post, I will describe these limitations, and how our brand new feature, budget rate alerts, addresses them.

By: Fred Hebert
As someone living the Honeycomb ops life for a while, SLOs have been the bread and butter of our most critical and useful alerting. However, they had severe, long-standing limitations. In this post, I will describe these limitations, and how our brand new feature, budget rate alerts, addresses them. We usually don’t have SREs writing product announcements, but I’m so excited about this one that I said, “Screw it, I’m doing it!”
SLOs in practice
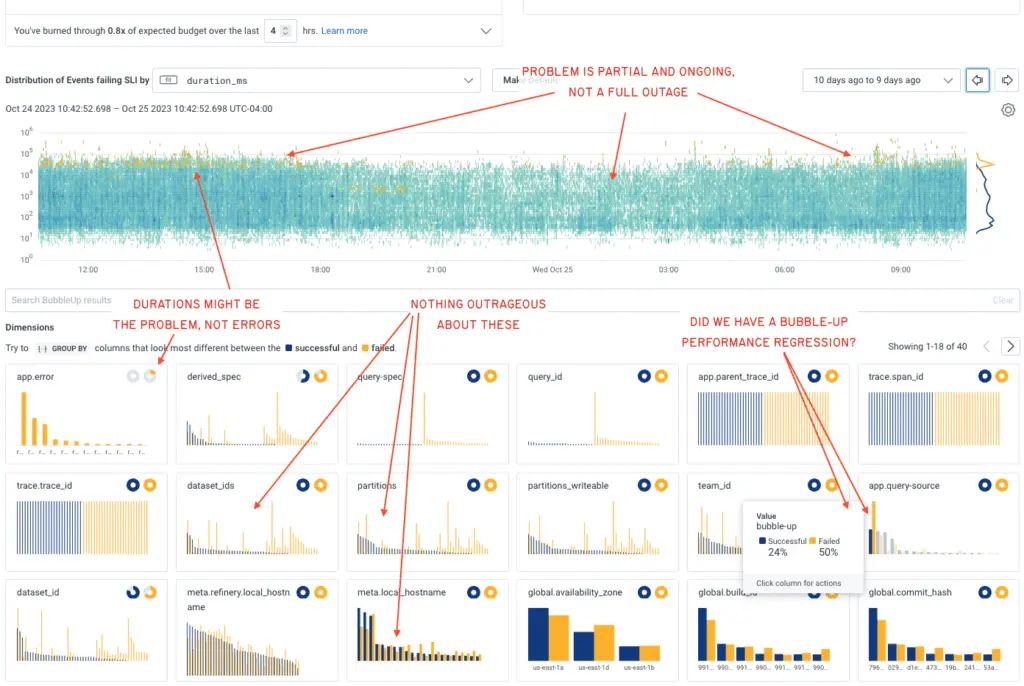
SLOs are one of the best tools to improve incident response alert-driven workflows: they tie the alert to historical data, along with a rich description. They also put all that data on a page with a heatmap and a BubbleUp query that lets you quickly filter out easily-correlated outliers, a potential sign of a false alarm, or trivial issues—leaving you only with severe, real problems to dig through.
If I get an alert, this is how I can scan the page:
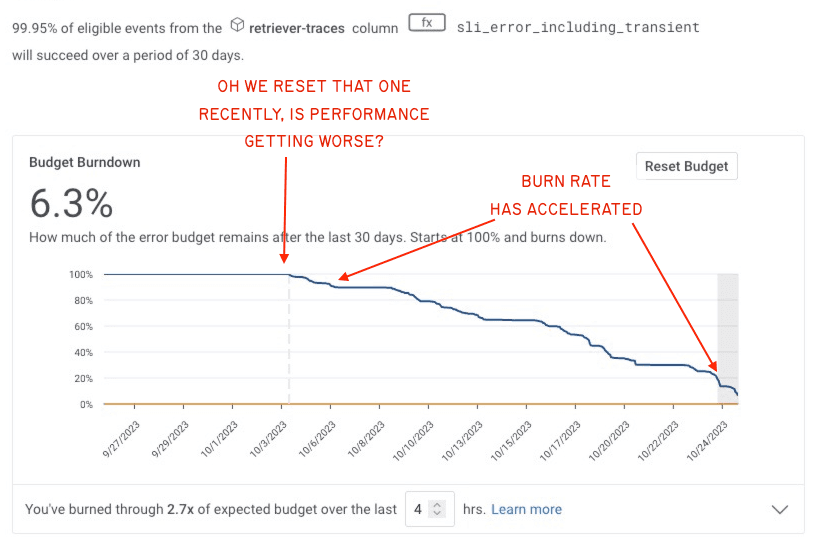
SLOs are based on error budgets. The allowed error budget is calculated based on an SLO’s entire duration and event volume. This means that alerts automatically take into account the event volume you’re going to see: a bad minute where 50% of the events fail but only four events were seen won’t alert you, and you won’t need to maintain any thresholds (“only tell me if more than 250 events were seen before alerting me”). In short, SLOs based on events—like ours—reduce the amount of flappy false alarms we get in a hands-off manner.
This makes them an ideal tool for people who deal with operations and carry a pager, as it means they’ll get high-quality alarms based on user impact.
However, SLOs play another role at the organization level. The error budget, once calibrated properly, lets engineers, project managers, and directors/executives know whether targets are met and which part of the organization may need to prioritize things differently.
A fast budget burn may hint at an outage or major issue, while a slow budget burn may hint at hitting a change in usage patterns or nearing a scaling inflection point. Fast burns are often manageable by roles that shoulder an operational burden as part of their function, and slow burns may require scheduling optimization times and corrective project work—or even recalibrating the SLO to reflect what is adequate. These tend to fall outside of the usual scope of on-call. We’ve hinted at some of these uses in Touching Grass with SLOs.
Tradeoffs with Honeycomb SLOs
SLOs are tools that can be used by multiple roles in an organization. While it speaks to their power, the reality is that making a tool that works for everyone—regardless of their role—tends to be a challenge.
For example, we can make a distinction between operations, which are often reactive, and roadmapping, which leans more heavily into planning:
- Operations-friendly staff want to know if something’s on fire right now because that’s actionable within their scope of responsibilities.
- Decision-makers want to be able to set priorities or know about their product’s health by looking at the budget, and help schedule more work upstream to prevent all corrective work from happening during outages.
While SLOs can be good for both, Honeycomb’s implementation often emphasized the tension between these roles by giving them a single tool. Because our alerts functioned purely by budget exhaustion, once an organization’s budget hit 0%, they would no longer get additional alarms until the previous events aged out or until the budget was manually reset.
Honeycomb users had to pick whether to emphasize operations or decision-making with their SLOs, then create coping mechanisms for the other. We’ve done and heard of practices such as resetting the budget and noting it down somewhere else, re-computing it out of band, or using triggers instead of SLOs to avoid resetting budgets.
Introducing budget rate alerts in SLOs
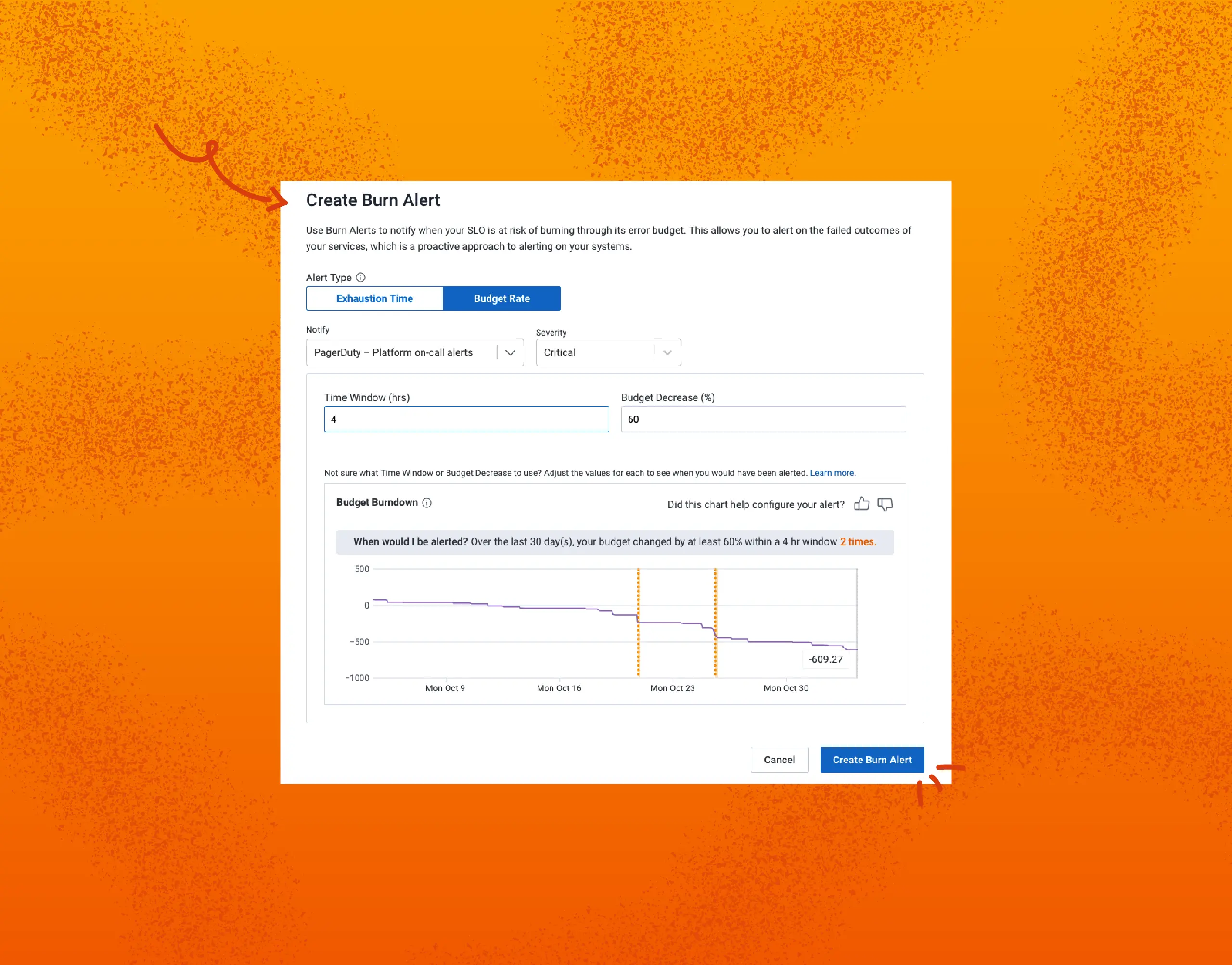
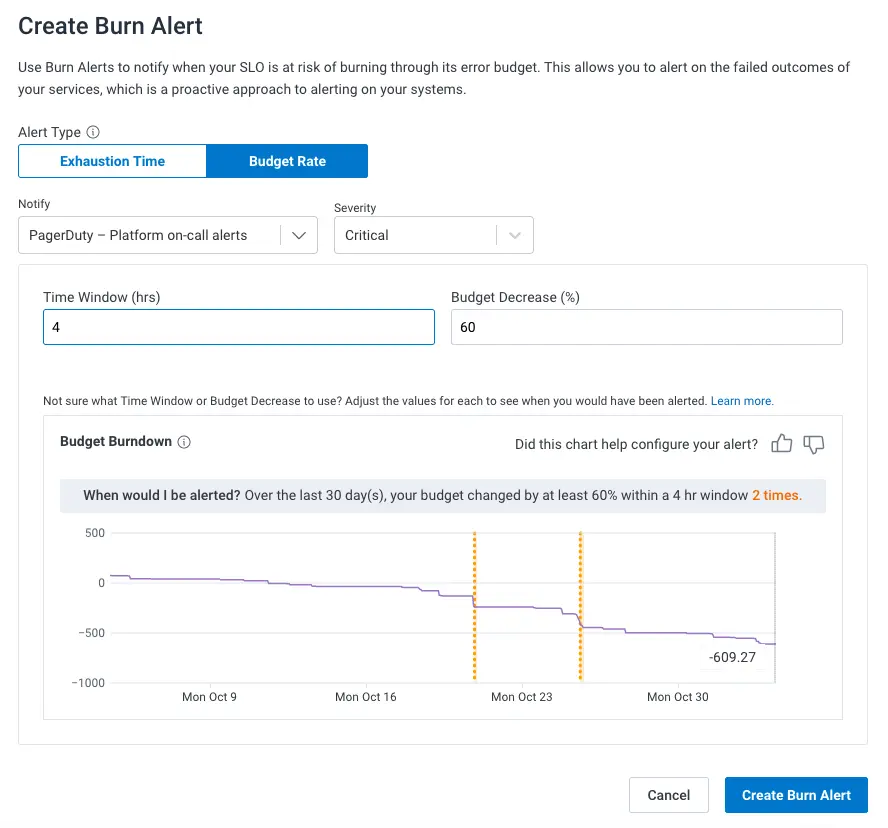
The release of budget rate alerts changes that: we can now do both well! A budget rate alert will let you know if you’ve burned more than X% of your budget during a given time window, even if the budget is below 0%. It will respect, but not require, budget resets.
See a budget dip that’s a bit too high? Set up an alert and be notified regardless of what budget is left. If your event volume changes, there’s no need to adjust thresholds like you might have needed to for triggers:
With two alert types, one that is based on budget exhaustion for decision-makers and one that is based on the ongoing burn rate for operational use cases, you no longer need to compromise. If triggers were good at pointing out “things are not okay right now,” SLOs can cover them well while also borrowing from the error budget to add “and it is affecting users.”
Additionally, because budget rate alerts are tied to the overall budget, they won’t page you for high error rates during low-traffic periods or when the budget is nearly exhausted. They’ll keep a generally uniform sensitivity whether you have 100%, 10%, or -1,000% budget left.
Let’s talk about the configuration window in the previous image. You no longer need experts to carefully craft alerts to make sure they won’t over- or under-alert you. If you have data, you won’t need to create a fake low-disruption alert to tweak until it gives you the right volume. You simply look at the budget burndown chart, pick a window and percentage, and tweak it until it gives you alerts in the correct range.
This interactive chart lets you distill a lot of expertise or long-winded experimentation periods into a few minutes.
Get started with budget rate alerts
I can’t say how excited I am about budget rate alerts! It’s one of the features I requested as an internal user of Honeycomb. In fact, I pushed early prototypes through hackathons.
We’re already converting many of our operational budget exhaustion alerts to budget rate alerts internally. We suggest you do the same:
- Look at older outages, see how much budget they dropped, and set budget rate alerts so you are notified when they happen—regardless of the budget that’s left in the future.
- Pick SLOs where any slight burn is bad and you want quick notifications, and create a budget rate alert to be notified immediately about service degradation, even if there’s a lot of budget left.
- Think about who needs to know about budget exhaustion without being involved in an on-call incident, and talk to them about where they might like getting notifications—set up non-urgent exhaustion alerts that communicate user pain to decision-makers in your org.
Learn all about how to get started in our documentation which also includes tips to better calibrate your SLOs on all levels. If you’re an Enterprise or Pro customer, you can try out budget rate alerts today. If not, you can get started with our Pro plan in minutes or reach out to sales for a free trial.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.