Authors’ Cut—Not-So-Distant Early Warning: Making the Move to Observability-Driven Development
Observability is about understanding systems, which means more than just production. Moving from logs to tracing and showing causality can be done locally, as well. We can give developers the same superpowers that SREs have: observability-driven development.

By: Martin Thwaites

This is how the developer story used to go: You do your coding work once, then you ship it to production—only to find out the code (or its dependencies) has security or other vulnerabilities. So, you go back and repeat your work to fix all those issues.
But what if that all changed? What if observability were applied before everything was on fire?
After all, observability is about understanding systems, which means more than just production. Moving from logs to tracing and showing causality can be done locally, as well. We can give developers the same superpowers that SREs have: observability-driven development.
Observability-driven development is the subject of Chapter 11 in our new O’Reilly Book: Observability Engineering: Achieving Production Excellence, and our interactive Authors’ Cut webinar. During that webinar, I introduced something cutting edge that Honeycomb’s been working on. In this blog, I’ll recap the highlights.
TDD goes platinum
We’ve been living in a “shift-left” or “shift testing left” world for a while with test-driven development (TDD). TDD is considered the gold standard of shift-left testing for a reason. For the last two decades, TDD has caught and prevented many potential problems long before they reached production. In fact, by testing in isolation, removing guesswork, and providing consistency, TDD really uplifts the quality of code. But nothing’s perfect. TDD’s consistency and isolation do not translate well to production.
Observability-driven development, which I also call tracing during development (yes, another TDD), takes the gold standard platinum by using instrumentation to help surface the code that needs debugging locally. Dev is a nicer place for this to happen than when you’ve got 100,000 customers using your application. And, you can write and ship better code. Plus, you don’t have to switch contexts or drain your brain because you are using the same tools in development and production for debugging.
Slicing through multi-threaded applications with cutting-edge observability-driven dev: An example
Bringing tracing closer sounds cool and all, but how do you make it work? Honeycomb has developed something that can answer that question. The difficulty of using debuggers for multi-threaded applications and other scenarios inspired this cutting-edge solution for bringing observability into development, giving developers access to using OpenTelemetry and all the auto instrumentation it has.
To illustrate how it works, we’re using a Microsoft solution with a SQL-like database and a UI that creates loads of logs when it runs. We add in an ASP.NET core, Entity Frameworks, OpenTelemetry, and Honeycomb.
With our new setting, enable local visualizations, the developer experience is improved while tracing.
When they run this setup, developers get a set of results that looks like this.

They can click on each trace in the results and see causality. Here’s an example.
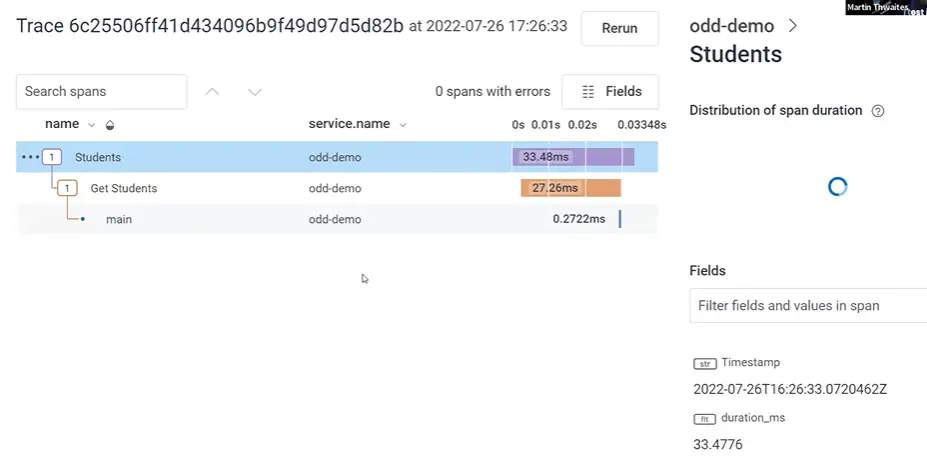
Because all this is also set up in production, developers can go straight from that code all the way through. But wait, there’s more! With observability-driven development:
- Attaching a debugger isn’t necessary
- No one has to hit individual API calls and hope they all work together because more of the site runs locally
- The same information and debugging cycle are in production
Knowing how Honeycomb technology can enable observability-driven development is an important part of getting people in your organization to buy into the idea.
Shifting culture left: How to change practices for observability-driven development
Code is a powerful motivator, for sure. But shifting observability left also requires a culture change. Let’s look at how you can make that happen.
Start by realizing that although observability-driven development brings development and operational concerns closer together, it’s a major change that might not be met with emojis and enthusiastic exclamation points. The good news is that this shift is possible despite initial resistance. Here are my recommendations for how it can be done:
- Produce a “whoa” or “aha” moment that gets developers excited about how observability-driven development actually makes their lives easier
- Start small and demonstrate value quickly
- Work iteratively by adding more instrumentation after an incident or resolution
- Once you gain confidence, deploy what you have into production to get a more complete picture
Sweetening the observability pot
Observability-driven development is the icing on the observability cake, showing developers how code will behave in production before it gets there. We’ve only hit some of its sweet spots in this blog. To go deeper into the topic, check out our O’Reilly book.
If you want to give Honeycomb a try, sign up to get started.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.