Honeycomb at Tapjoy: Faster Time to Confidence with Observability

By: Varsha Patel

About
Tapjoy maximizes mobile engagement and monetization for leading advertisers and app developers. Their SDK is currently embedded in over 15,000 mobile apps and reaches over 520 million active users per month.
Environment
- Monolithic Rails app
- Many high-volume 3rd-party attribution partners
Goals
Tapjoy processes millions of requests per minute as a mobile ad network. In support of their ad-serving platform, they have performance and infrastructure monitoring systems, large data pipelines that feed ad selection algorithms, and backing datastores that engineers regularly access to understand how their code interacts with the data moving through their systems. As part of the mobile advertising ecosystem, they also share data with “third party attribution” partners, who collect data from multiple ad networks and decide which ad network gets credit for any specific billable user event.
We spoke to Tapjoy engineer Dan Kleiman soon after a couple of their engineering teams had been exploring Honeycomb as a way to gain additional insights. Dan had recently completed a migration of some of Tapjoy’s critical third party services and told us the quick wins he got from using Honeycomb to monitor this cutover.
Since we rarely change our integration endpoints with our high-volume 3rd party attribution partners, we don’t have the same processes in place for this kind of cutover that we do for more routine events. When we have to make changes like this, we take it slow. We’d do it in batches, one partner or app at a time, to make sure nothing broke and limit scope if it did.
Dan Kleiman
Engineer at Tapjoy
What They Needed
- Greater visibility into the migration process as it was happening
- The ability to immediately investigate problems across high-cardinality fields such as unique customer app IDs attached to relevant events and metrics
Honeycomb @ Tapjoy
Tapjoy’s engineers primarily use Honeycomb’s Go library and NGINX agent to instrument their API services and then use Honeycomb to investigate the behavior of those services.
We used the NGINX log parser because it was essentially zero-effort.
Dan Kleiman
Engineer at Tapjoy
They got a lot of value “right out of the box” by just sending their existing access logs, with no additional instrumentation.
The speed with which I can figure out the source of a spike in 422 errors is amazing; I can ask ‘is it a partner, is it an integration partner, is it a specific app that has a misconfigured SDK?’ and get immediate results. So, so easy to do.
Dan Kleiman
Engineer at Tapjoy
One specific example of immediate ROI is the time and labor Tapjoy saved when cutting over their high-volume partner integrations to a new endpoint. Historically, these migrations were done incrementally, moving a subset of the traffic over at a time to ensure visibility into the behavior immediately after the cutover. When problems occurred, it could take 10 or 15 minutes for the necessary data to get through ETL to where the engineers could begin to analyze it and discover the problem.
Confidence doesn’t have to take so much time
Before Honeycomb, these migrations could take days, with staff from Tapjoy and the partner organization on a phone bridge, watching the cutovers happen. But once the Tapjoy team began using Honeycomb, they cut that time down from 2-3 days to a few hours or less.
We felt confident cutting over in much faster cycles, almost all at once, because we knew we’d see anything wrong immediately, in real-time—AND we’d be able to dig into it and find the root cause in minutes.
Dan Kleiman
Engineer at Tapjoy
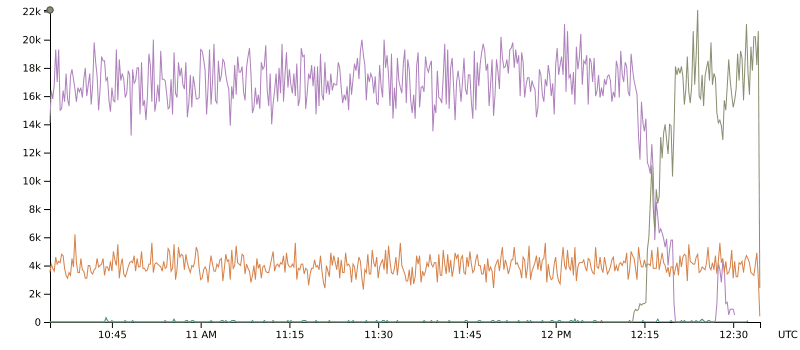
The graph shows the cutover; a third party being migrated from one endpoint to another in one rollout.
I feel 100% on top of the cutover the whole time.
Dan Kleiman
Engineer at Tapjoy
Their partners are just as happy for the saved time on their end.