Observability, Meet Natural Language Querying with Query Assistant
Engineers know best. No machine or tool will ever match the context and capacity that engineers have to make judgment calls about what a system should or shouldn’t do. We built Honeycomb to augment human intuition, not replace it.

By: Phillip Carter

8 Best Practices to Understand and Build Generative AI Applications Effectively
Learn MoreEngineers know best. No machine or tool will ever match the context and capacity that engineers have to make judgment calls about what a system should or shouldn’t do. We built Honeycomb to augment human intuition, not replace it.
However, translating that intuition has proven challenging. A common pitfall in many observability tools is mandating use of a query language, which seems to result in a dynamic where only a small percentage of power users in an organization know how to use it. We’ve invested in solutions like Query Builder UI to make Honeycomb easier to use, but we recognize that even this hasn’t truly made observability feel like it’s something anyone on any team can participate in. Today, we’re having another go at this problem.
We’re thrilled to announce the launch of Query Assistant today to all users at no additional cost. With Query Assistant, you can describe or ask things in plain English like “slow endpoints by status code” and Query Assistant will generate a relevant Honeycomb query for you to iterate on. As with all features in Honeycomb, it’s meant to be interactive and iterative. We want you to take what Query Assistant builds for you and tweak it with the Query Builder UI, run it again, or share it with a teammate!
Query Assistant merely scratches the surface when it comes to how we can thoughtfully apply AI to observability, but it’s an exciting first step. Let’s dive into how you can use Query Assistant today.
Get the guide on best practices for building GenAI apps.
How to get started using Query Assistant
Getting started with the Query Assistant is super easy—which is kind of the whole point! Head on over to the New Query Page:

Type what you want, or click on one of our suggested prompts below, hit Enter or click “Get Query,” and Honeycomb will generate a query and run it for you:
Query Assistant tips for success
We’ve experimented and tuned Query Assistant to produce “useful” queries. Admittedly, that’s a very loose term. It’s impossible for Honeycomb to know up front what the perfect query for you is. However, since we work with a lot of users, we know there are general patterns in queries that people universally find helpful. These patterns are baked into the Query Assistant. As a result, you may find it more robust than you initially thought, especially if you’re new to Honeycomb and unsure of querying best practices.
Here are a few tips to maximize the usefulness of the Query Assistant.
Tip: Try to be more specific
The more vague your inputs are, the more vague the outputs will be. If you say something like “show me something interesting,” don’t be surprised if you don’t get a query. If you say something like “what’s slow” you should probably still get a query, but that query will be a jumping-off point for a latency investigation, not a query that narrows in on the thing that’s slow.
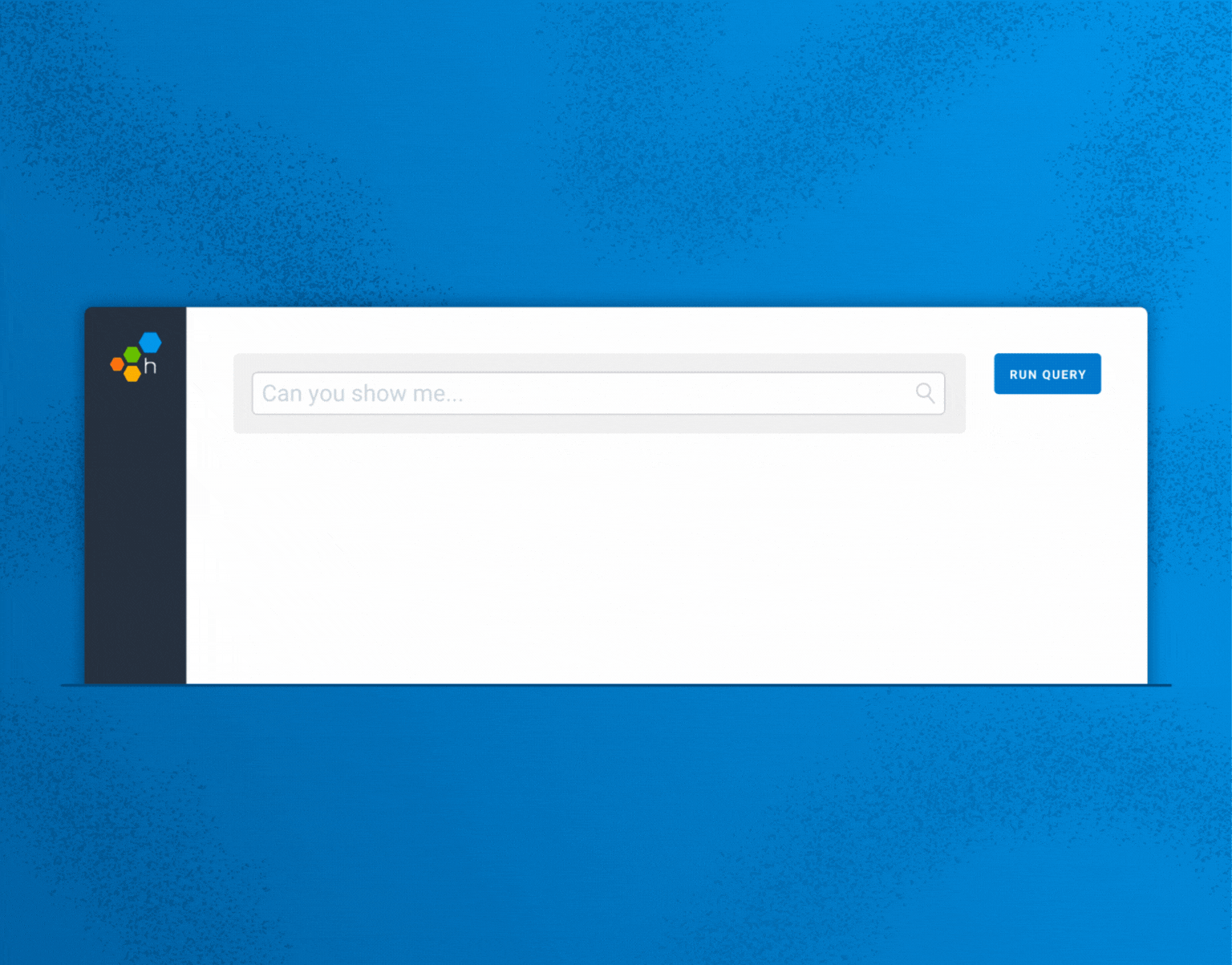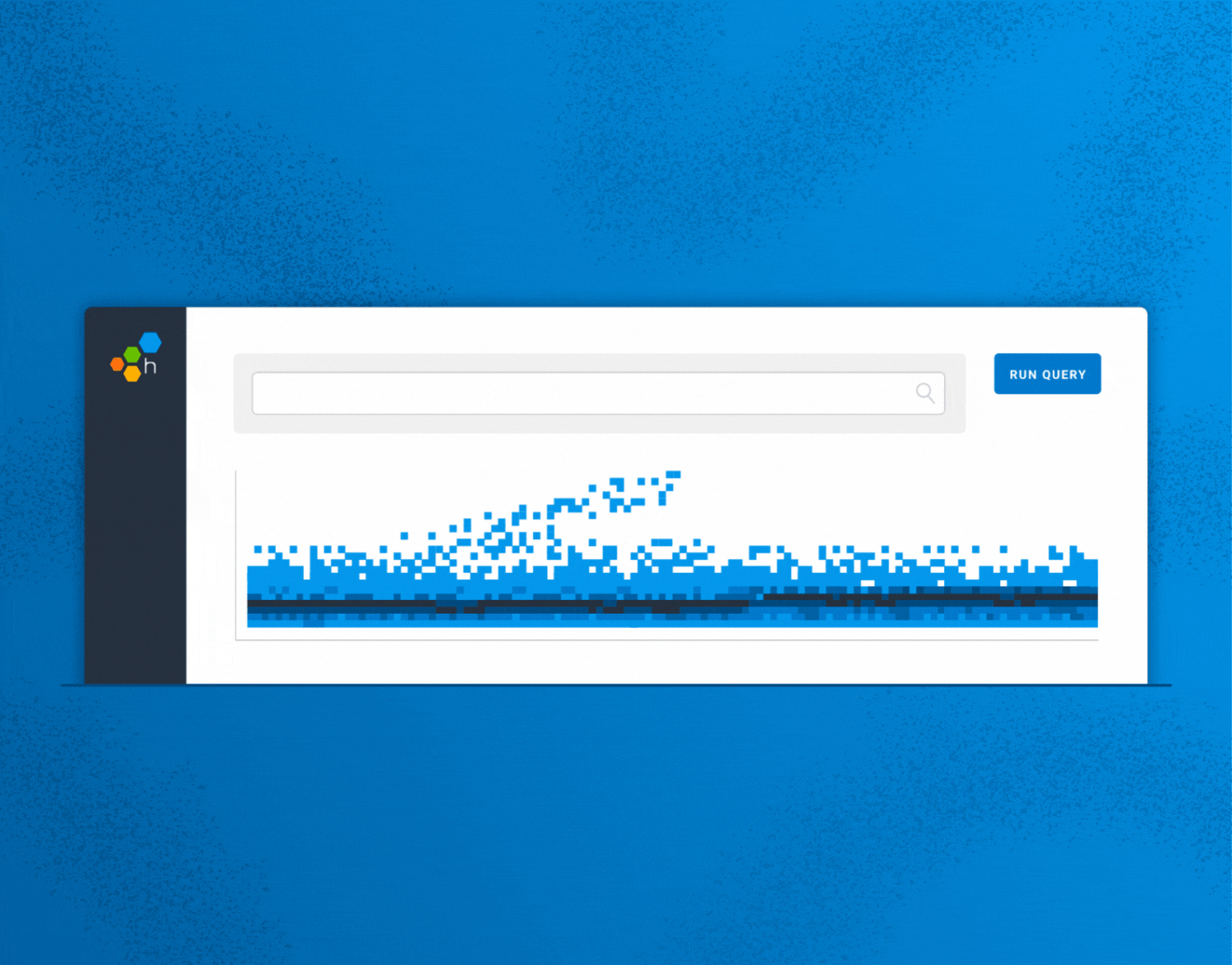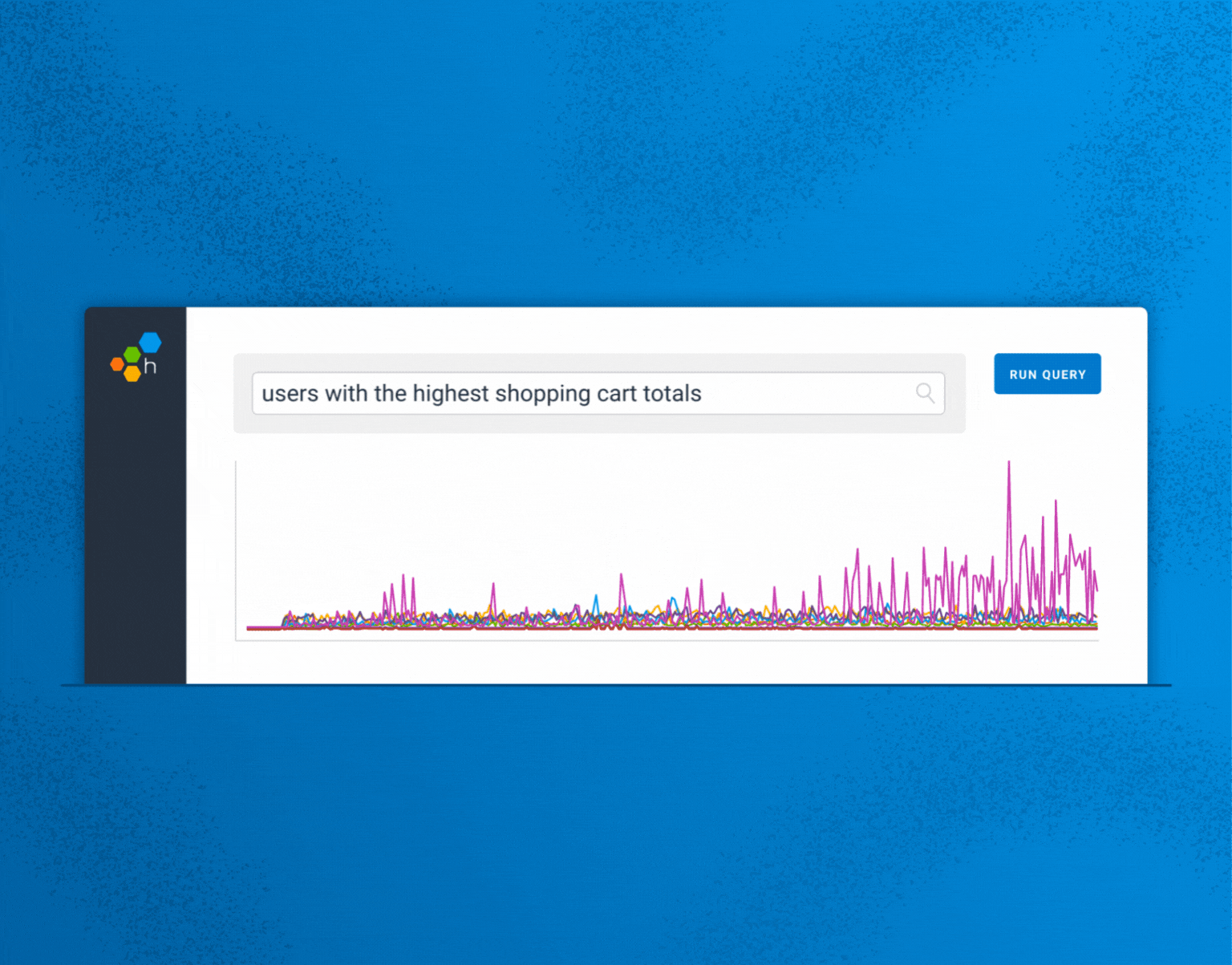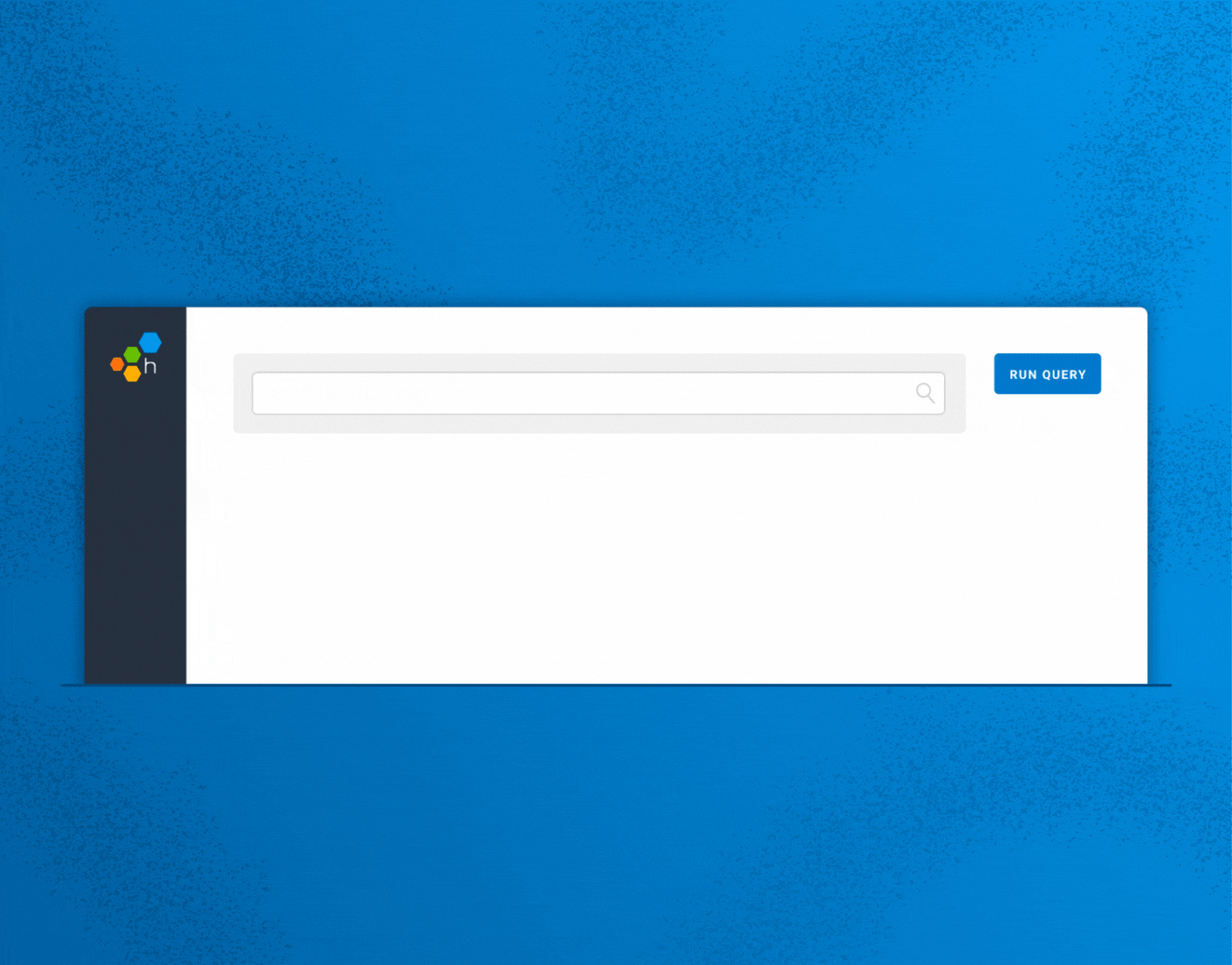
Instead, if you’re interested in something in particular, include that in your input. For example, in our demo environment, if I am curious about users with higher cart totals, I can ask about that.
Input: “latency for users with the highest cart totals, by user id”
Result:
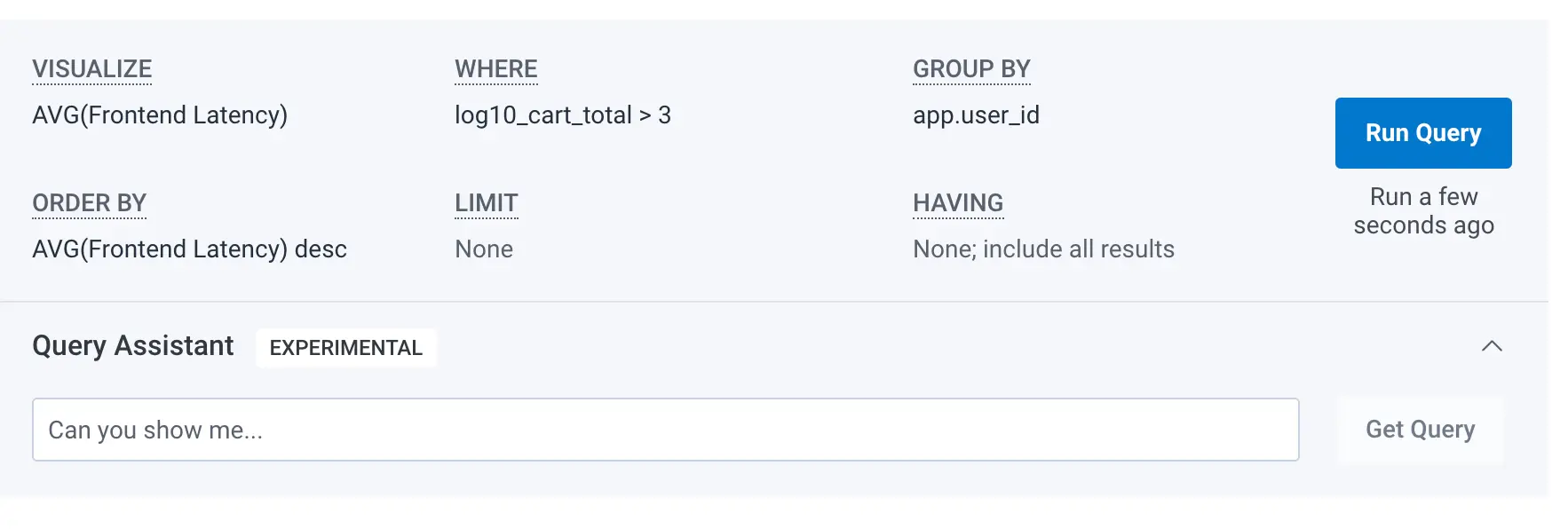
The resulting generated query correctly computes latency for the service, grouped by user ID, but also filters for a threshold on the log10 of cart totals, which filters out users that don’t have much in their shopping carts.
Tip: Say “Show me <something> by XYZ”
The real power of Honeycomb is felt when ‘grouping by’ arbitrary fields in your data. Query Assistant will do this for you if you add “by <interesting name related to a field>” to your input. Here are a few examples:
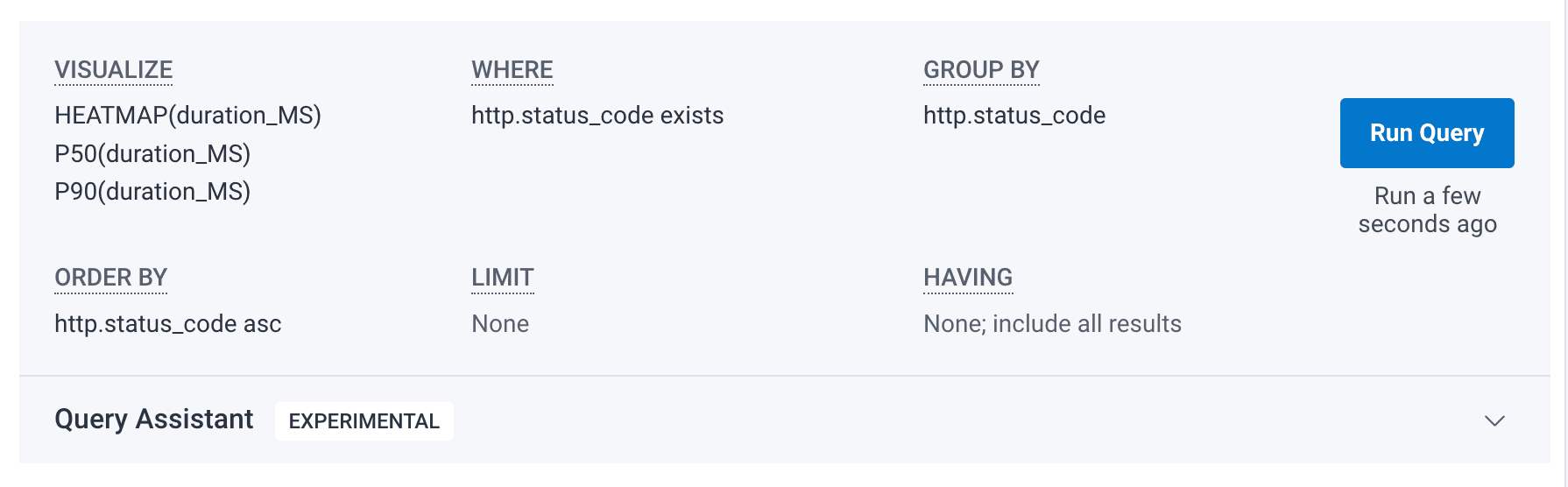
- Latency by status code
- Traffic by user
- Slowest traces by endpoint
For example, when I say “slowest traces by endpoint,” I get a query like this:

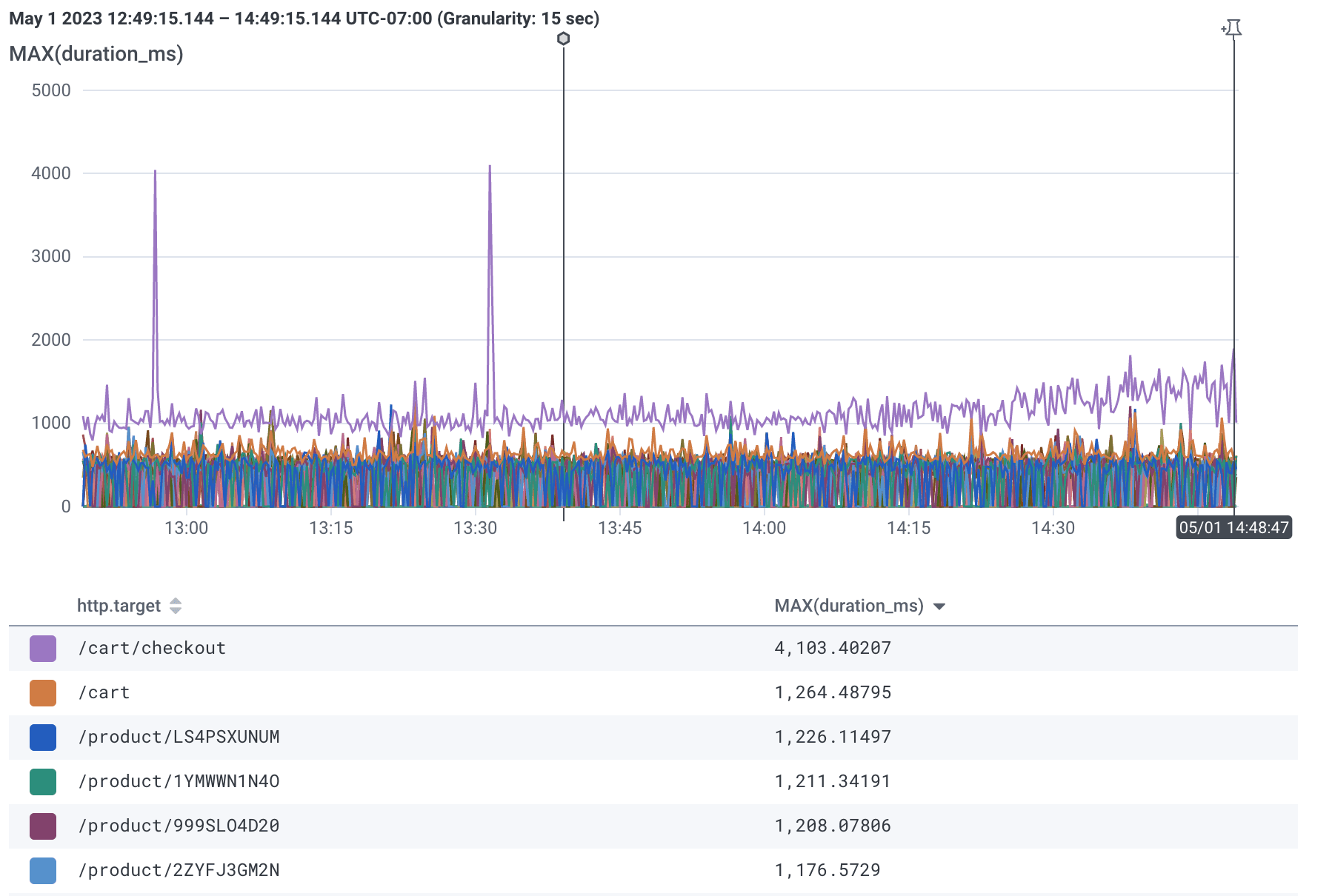
By saying “by endpoint,” I hint to the ML model that I’m interested in grouping results.
Tip: Say “distribution” to get a heatmap of values
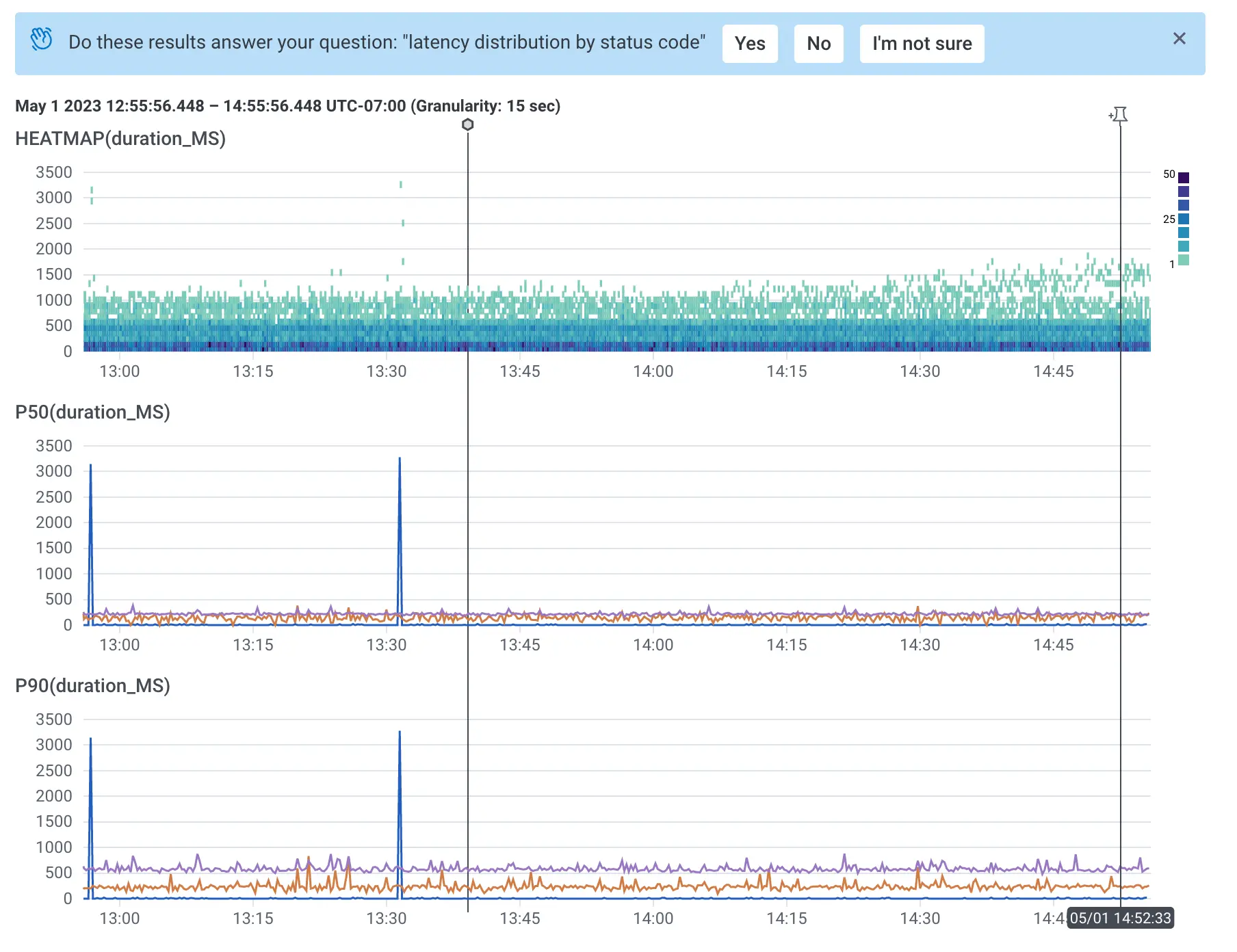
Honeycomb’s heatmaps are so profound because of how intuitive they are at finding outlier data that might represent issues in your system. Heatmaps let you see a full distribution of values, which is especially useful when combined with another aggregation to AVG or P99. Here are some examples:
- P99 and distribution of latency
- Distribution of serverless spend by route
For example, if I say “P99 and distribution of latency by endpoint,” I get this query:
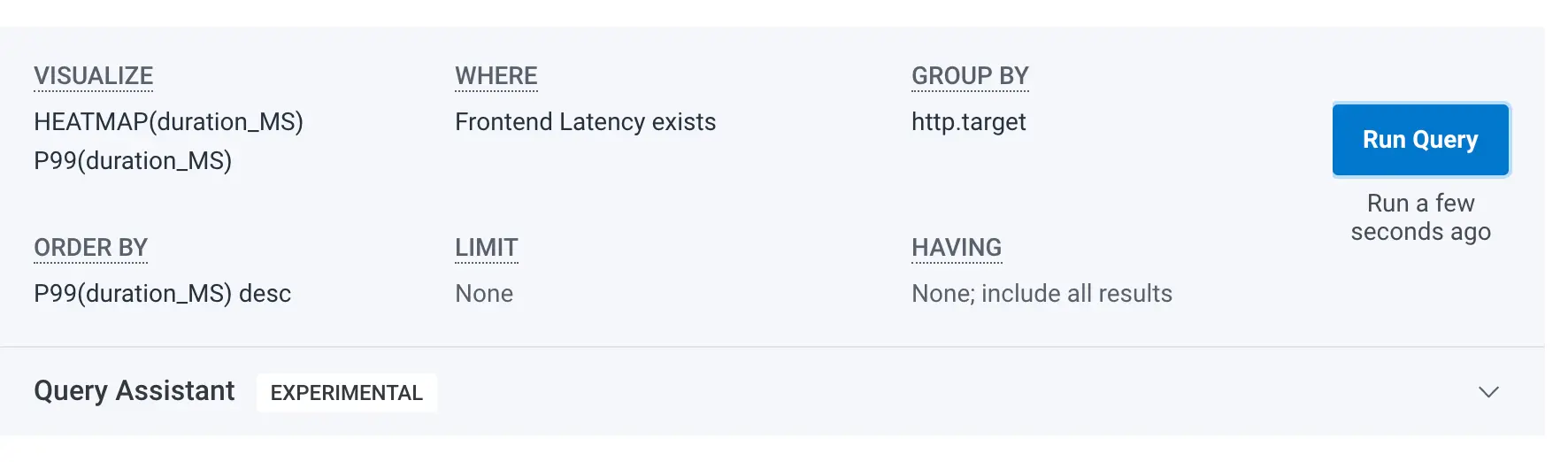
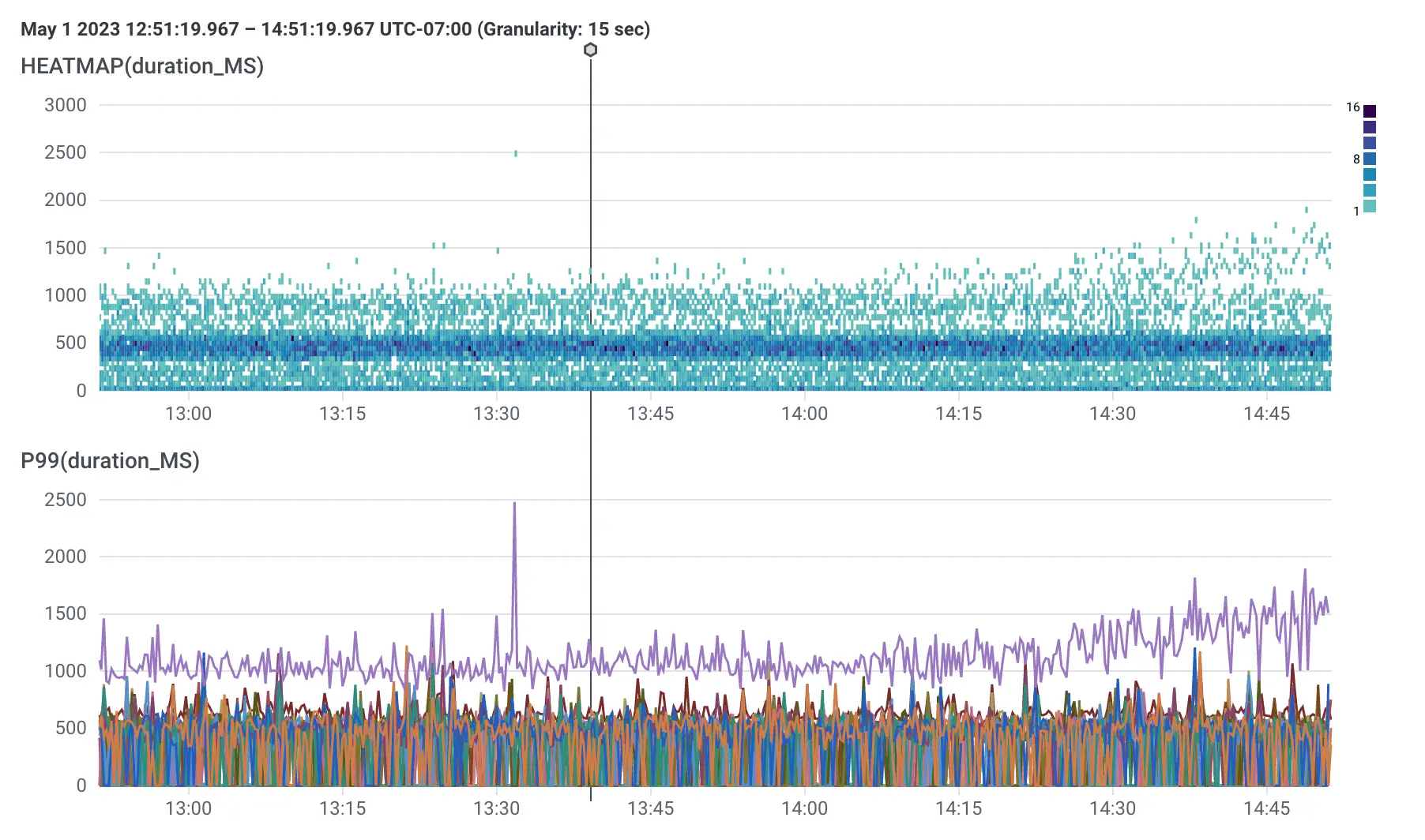
By default, Query Assistant will generate a heatmap when applicable. If you want to ensure that you get a heatmap, say “distribution of <x>” and it’s a lot more likely that you’ll get one. In this example, by saying “distribution,” I ensured that I got a heatmap, which lets me do things like bubble up on the results. Note that I also included “by endpoint” because it’s almost always helpful to group by things.
Tip: Say what you want, not what you don’t want
This tip is broadly applicable to any use of generative AI. When using generative AI, use language that is affirmative. Do not describe what you’re not looking for. Maybe someday we’ll have AI models that can work well with that kind of phrasing, but we’re just not there today.
Do: “Show the highest latency of my services broken down by operation”
Don’t: “Don’t show fast latency, but show latency of my services broken down by operations”
Mixing negative and affirmative statements can muddy the waters. In the above example, both statements ask for the same thing. However, the former can be easily expressed by calculating maximum request latency, ordering by that calculation, and grouping by the name of the operation. The “fast” requests are at the bottom of the result set. To express the latter, it becomes much more speculative: what does “fast” mean? How should that be calculated? And what—if anything—should be filtered, and where?
Tip: Keep using the Query Builder
Query Assistant is… an assistant! It’s not a replacement for our Query Builder. If you find it’s easier to add another column to GROUP BY via clicking and typing, do that. If you’d prefer to filter by a value that you already know, type it into the Query Builder. We expect most investigations, especially in times where you’re iterating a lot on a single query, to still primarily involve our Query Builder. And that’s fine. We believe AI should augment and improve experiences, not replace them.
Why we built Query Assistant
At this point, you might be thinking, “Phillip, you just said this is the first introduction of AI into Honeycomb. Why now? And isn’t BubbleUp machine-assisted?” And to that, I say good question, and good point! The answer is multi-faceted:
- Observability is still challenging for most developers to get accustomed to. Everyone has a mental model of their code, systems, and/or data, but translating that into the constructs of an observability tool can feel unnatural for most developers.
- Advancements in machine learning technology, notably that of Large Language Models (LLM), have made it possible to convert natural language input into a wide range of interesting target outputs.
- Honeycomb is, at its core, built around querying. Query Builder, Boards, Triggers, SLOs, and Service Map are all centered around querying your data in any way you want.
- Yes, Query Assistant joins Honeycomb’s other human-first machine-assisted debugging tools, such as BubbleUp. The intent behind BubbleUp is to help users figure out “what question to ask [next]” and now Query Assistant helps you with how to phrase it.
In other words, we think natural language is a good interface for observability when considering a broad population of developers, and it has the potential to mesh well with the rest of our product.
Query Assistant limitations
Query Assistant is experimental. First and foremost, we want people to try it and give us oodles of feedback. Since it’s complementary to Query Builder, if you’re finding that it doesn’t do what you need, you can still use Query Builder.
As of right now, Query Assistant can only be used to generate queries. We’ve experimented with having it modify the existing query, and that’s likely coming soon. But for now, we want to focus on creating new queries accurately.
Finally, Query Assistant might give less accurate results for large schemas. This won’t impact most users, because the majority of teams lack datasets that are large enough to make a noticeable difference in accuracy. Additionally, even among teams that have larger datasets, they typically constitute only a small portion of their total datasets.
For those who regularly query against large schemas (for either a dataset or an environment), you may notice that Query Assistant “misses” a column that should be there. That’s to be expected from time to time. Just know that we’re experimenting with ways to add accuracy for querying large schemas without sacrificing the performance of query generation. Please give us feedback and stay tuned for more.
A word on user privacy
We know that AI presents consumer privacy concerns. Our current vendor, OpenAI, has robust data protection mechanisms that we are confident in. Additionally, if you sign a BAA with Honeycomb, Query Assistant is currently unavailable (we’re working on it).
No user or team-identifying data is sent to a Large Language Model, and no data is retained for training models either by us or OpenAI. Finally, if you’re simply uncomfortable with the feature, you can turn it off for your team in Team Settings. As has always been the case, we have a deep commitment to the privacy and security of our users, especially now with AI in the picture.
Waxing philosophical on AI for a moment
AI is all the hype right now. As far as we’re concerned, it’s real and likely here to stay. We’re aligning around a particular idiom:
We’re here to build mech suits, not robots.
What that means for our product is that we believe AI is a tool to augment human intuition. We’re keen to explore how machine learning can be used to increase the amount of time our users spend unlocking insights, rather than toiling away at tasks. Some ideas we’re looking to explore this year include:
- Much more advanced natural language querying, with the goal that you can truly ask any question of your systems
- Suggest starter queries and boards to have good jumping-off points tailored to your data
- Explain or summarize results from anywhere within our product
- Incorporate history (such as query history) into all of the above
- Use observability data to help you narrow in on the particular lines of code related to a problem
- Instrumentation feedback mechanisms that suggest how you can further instrument your code
- Make our product documentation more searchable, understandable, and approachable
- New approaches to interacting with data that can complement the current querying interface
You’ll note that in the above there’s no mention of anomaly detection, automated alerting, or AIOps. We feel that such areas are a misapplication of AI that lead to developers ignoring the tool rather than using it. Everything we’re interested in exploring is still rooted in humans being the ones who make key insights, drive the product the way they want to, and maximize their time getting value out of Honeycomb. We believe AI should empower the human intuition and curiosity that drive great observability feedback loops.
To that end, we’re excited for you to try Query Assistant. While you do, we’re going to soak up all your feedback to keep building the best damn observability product on the market. New to Honeycomb? Get started by signing up for free.
Further reading:
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.