All the Hard Stuff Nobody Talks About when Building Products with LLMs
There’s a lot of hype around AI, and in particular, Large Language Models (LLMs). To be blunt, a lot of that hype is just some demo bullshit that would fall over the instant anyone tried to use it for a real task that their job depends on. The reality is far less glamorous: it’s hard to build a real product backed by an LLM.

By: Phillip Carter


8 Best Practices to Understand and Build Generative AI Applications Effectively
Learn MoreEarlier this month, we released the first version of our new natural language querying interface, Query Assistant. People are using it in all kinds of interesting ways! We’ll have a post that really dives into that soon. However, I want to talk about something else first.
There’s a lot of hype around AI, and in particular, Large Language Models (LLMs). To be blunt, a lot of that hype is just some demo bullshit that would fall over the instant anyone tried to use it for a real task that their job depends on. The reality is far less glamorous: it’s hard to build a real product backed by an LLM.
Here’s my elaboration of all the challenges we faced while building Query Assistant. Not all of them will apply to your use case, but if you want to build product features with LLMs, hopefully this gives you a glimpse into what you’ll inevitably experience.
The second edition is here!
Grab your free copy of Observability Engineering
and learn the foundationals of observability
from the experts.
A quick overview of Query Assistant
At a high level, Query Assistant allows you to express a desired Honeycomb query in natural language, such as:
- Which service has the highest latency?
- What are my errors, broken down by endpoint?
- Which users have the highest shopping cart totals?
In return, you get a Honeycomb query that executes as a best effort “answer” to your natural language query.The idea isn’t that it’s perfect, but it’s better than nothing—and it’s easy for you to refine what comes back using our Query Builder UI.
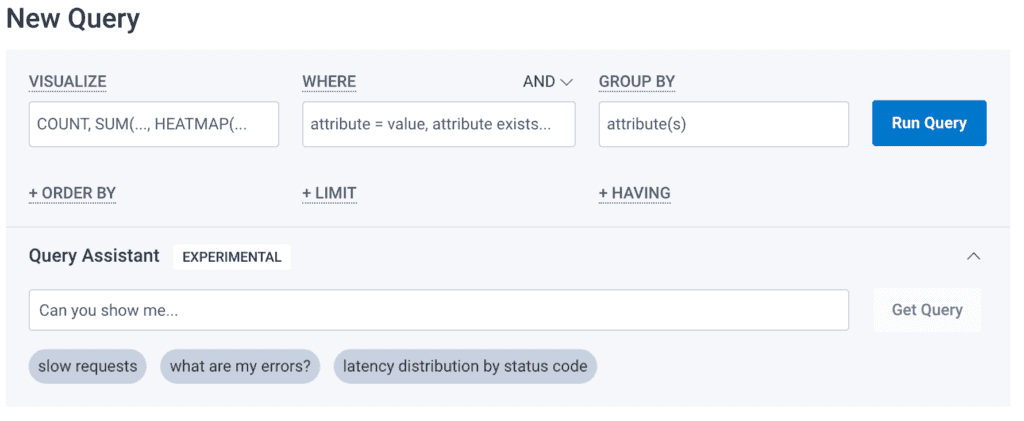
How it works under the hood
Query Assistant is all about prompting, which assembles a task and data/context as input to an LLM. In no particular order, we pass the following things:
- The user’s input where they ask for a query in natural language
- Information about what constitutes a Honeycomb query (visualization operators, filter operators, the structure of different clauses in a query, etc.)
- Information about the domain of instrumentation data (e.g., trace.parent_id does-not-exist refers to a root span in a trace, and is often used to represent a request)
- The schema that a query needs to be produced for (since you need real columns to choose to plug into a query)
- Several examples, similar to a few-shot prompt
- The existing query (if it exists)
- Instructions on what to do
And that’s it! Behind the scenes, we take output from an LLM, parse it and correct it (if it’s correctable), and then execute the query against our query engine. We don’t plug this into a chat UI—we think that’s the wrong interface for us. In fact, we think no interface is the right interface.Aside from the textbox and button to accept natural language input, everything else is just the same Honeycomb UI.
Working with GenAI? Don’t go it alone. Read our best practices guide.
The challenges
Context windows are a challenge with no complete solution
I casually mentioned that we use “the schema that a query needs to be produced for” in our prompt for an LLM. Unfortunately, there’s nothing casual about it. LLMs have a limit to the amount of input that can accept. That limit, called a context window, includes everything: your inputs, all possible outputs of the LLM, and any data you want to pass to it.
Because we made Query Assistant available to everyone, we needed to have an approach for dealing with context that’s bigger than the context window. Some customers have schemas with over 5000 unique fields, and there’s no way for us to know up front which subset is the “correct” one to select. So we considered several approaches:
- Turn off the feature for customers with “big schemas,” or at least turn it off for only those schemas
- Chunk up a big schema and make N concurrent calls to an LLM with some notion of a “relevancy score,” pick the best one, and hope that the boundaries between chunks don’t elide critical information
- Chain LLM calls by repeatedly building and refining a query with subsets of a schema, with the hope that after N serial calls you end up with something relevant
- Use Embeddings and pray to the dot product gods that whatever distance function you use to pluck a “relevant subset” out of the embedding is actually relevant
- Find other ways to get creative about pulling in a subset of a schema
We decided to find other ways to get creative, although we’ll likely use Embeddings in the near future.
As it turns out, people generally don’t use Honeycomb to query data in the past. In fact, when you constrain a schema to only include fields that received data in the past seven days, you can trim the size of a schema and usually fit the whole thing in gpt-3.5-turbo’s context window.
However, even constraining a schema by time isn’t enough for some customers. In some cases we still need to truncate the number of fields we use, resulting in a hit-or-miss experience depending on if the most relevant fields in a schema were truncated or not. We’re looking into the right prayers for the dot product gods with Embeddings to help with this, since it seems to be the most tractable alternative approach. Spoiler alert: the dot product gods aren’t always right, so we’re probably going to have to test in prod for this one and see if it’s an overall improvement when activated more broadly.
There are promising advancements in models with very large context windows. However, in our experiments with Claude 100k, it’s several times slower if we dump a full schema into our prompt, and it hallucinates more often than if we use an Embedding to pluck out a smaller, more relevant subset of fields. Maybe that will get fixed in time, but for now, there’s no complete solution to the context window problem.
LLMs are slow and chaining is a nonstarter
Commercial LLMs like gpt-3.5-turbo and Claude are the best models to use for us right now. Nothing in the open source world comes close. However, this only means they’re the best of available options. They can take many seconds to produce a valid Honeycomb query, with latency ranging from two to 15+ seconds depending on the model, natural language input, size of the schema, makeup of the schema, and instructions in the prompt. As of this writing, although we have access to gpt-4’s API, it’s far too slow to work for our use case.
If you google around enough, you’ll find people talking about using LangChain to chain together LLM calls and get better outputs. However, chaining calls to an LLM just makes the latency problem with LLMs worse, which is a nonstarter for us. But even if it wasn’t, we have the potential to get bitten by compound probabilities.
Let’s imagine an LLM and prompt that produces a valid Honeycomb query for 90% of all inputs. That’s quite good! However, if you need to chain calls to that LLM together, then that can potentially result in less accuracy, because… math. A 90% accurate process repeated 5 times is (0.9*0.9*0.9*0.9*0.9), or 0.59, 59% accurate. Ouch. Fortunately, there are ways to mitigate and improve this process by tweaking the prompts that you chain together, and in practice, it doesn’t result in such a steep drop-off in accuracy.
We found no tangible improvements in the ability to generate a Honeycomb query when chaining LLM calls together. The book isn’t closed on this concept altogether, but here’s your warning: LangChain won’t solve all your life’s problems.
Prompt engineering is weird and has few best practices
As mentioned earlier, the way Query Assistant works today is through prompt engineering. Prompt engineering the art and science of getting a ML model to do useful stuff for you without training it on particular data and/or expected outputs. And here’s the thing: it’s the wild fuckin’ west out there. Just look at all the techniques in the link to see what wild and interesting stuff people try with prompting. Here’s some things we tried:
- Zero-shot prompting: didn’t work
- Single-shot prompting: worked, but poorly
- Few-shot prompting with examples: seems to work well
- “Let’s think step by step” hack: less likely to produce a query for more ambiguous inputs
- Chain of thought prompting: unclear; not enough time to validate
There are improvements we can make to our prompts by combining some of the emerging prompting techniques available. However, we wanted to deliver something fast, and experimenting with prompting is a time consuming process. It’s hard to evaluate the effectiveness of a prompt for us because we have an interesting constraint to be correct and useful for broad inputs.
Correctness and usefulness can be at odds
Earlier, I said that we use an LLM to produce a Honeycomb query. That query needs to be correct to be used, but that’s not the whole story. We must be able to do two things beyond simply producing a correct query:
- Accept broad, potentially ambiguous inputs from users
- Produce a query that’s “helpful” based on certain behaviors we know about Honeycomb
As we’ve learned from shipping our product, our users input every possible thing you can imagine. We get queries that are extremely specific, where people more-or-less type out a full Honeycomb query in English, even using the terminology in our UI. We also get queries that literally say “slow” and nothing else.
Clearly, no prompt + LLM combination can produce a Honeycomb query for all possible inputs, especially if those inputs are extremely vague (how on earth should we interpret slow?!). However, it’s unhelpful for us to be pedantic. What we think is vague may not be vague to someone using the tool, and our hypothesis is that it’s better to show something than nothing at all. And so our prompt needs to work with inputs that might not make much sense.
Supporting very broad inputs is the area where a supposed improvement to prompting techniques, zero-shot chain of thought prompting, seemed to make the LLM behavior “worse.” In testing, a zero-shot chain of thought prompt reliably failed to generate a query at all when inputs were vague. And based on data we have about what people ask Query Assistant, going live with this would have been a mistake, since we get a lot of vague inputs.
Additionally, just doing what someone asks for isn’t always the right thing.
For example, we know that when you use an aggregation such as AVG() or P90(), the result hides a full distribution of values. We’ve found countless times with customers that while aggregations are fine to show a general trend, the fact that they hide a full distribution of values means that you can easily miss problems in your systems that become bigger problems later on. In this case, you typically want to pair an aggregation with a HEATMAP() visualization.
Unfortunately, accepting broad inputs and needing to apply some form of “best practice” on outputs really throws a wrench into prompt engineering efforts. We find that if we experiment with one approach, it improves outputs at the cost of accepting less broad inputs, or vice-versa. There’s a lot more work we can do to improve our prompting, but there’s no apparent playbook we can just use right now.
Prompt injection is an unsolved problem
If you’re unfamiliar with prompt injection, read this incredible (and horrifying?) blog post that explains it. It’s kinda like SQL injection, except worse and with no solution today. When you connect an LLM to your database or other components in your product, you expose all of these parts of your product (and infrastructure) to prompt injection. We took the following steps that we think can help:
- The output of our LLM call is non-destructive and undoable
- No human gets paged based on the output of our LLM call
- The LLM isn’t connected to our databases or any other service
- We parse the output of an LLM into a particular format and run validation against it
- By not having a chat UI, we make it annoying and difficult to “experiment” with prompt injection inputs and seeing what outputs get returned
- Our input textbox and allowed outputs are truncated
- We have rate limits per user, per day
If someone is motivated enough, none of this will stop them from getting our system to do something funky. That’s why we think the most important thing is that everything we do with an LLM today is non-destructive and undoable—and doesn’t touch user data. It’s also why we’re not currently exploring a full chat UI that people can interact with, and we have absolutely no desire to have an LLM-powered agent sit in our infrastructure doing tasks. We’d rather not have an end-user reprogrammable system that creates a rogue agent running in our infrastructure, thank you.
And for what it’s worth, yes, people are already attempting prompt injection in our system today. Almost all of it is silly/harmless, but we’ve seen several people attempt to extract information from other customers out of our system. Thank goodness our LLM calls aren’t connected to that kind of stuff.
LLMs aren’t products
There’s a lot of “products” out there that are just a thin wrapper around OpenAI’s completions API with a barebones degree of “context” or “memory” (usually via Embeddings). These will all likely disappear by the end of the year as ChatGPT, Bard, and Bing become better and add a robust ecosystem. Unless you’re literally in the business of selling LLMs, an LLM isn’t a product! It’s an engine for features.
By treating an LLM like an engine that creates a Honeycomb query, we shifted the focus of our work from being primarily about shipping an LLM interface to users and about extending our product UI. It may have been cheaper to create “HoneycombGPT” and ship a crappy version of ChatGPT with Honeycomb querying as its sole capability (sans prompt injection), but we felt that was uninspiring and the wrong interface for most people.
The bulk of the work in building Query Assistant was no different from most product work: design and design validation, scoping things (in this case, very aggressively to meet a one month deadline), making decisions based on roadblocks found in development, and a lot of dogfooding and as much external validation of the experience as possible. Don’t mistake an LLM for a product, and don’t think it can replace standard product work.
LLMs force you to address legal and compliance stuff
You can’t just plop some API calls to OpenAI into your product, ship to customers, and expect that to be okay if you have anything more than a small handful of customers. There are customers who are extremely privacy-minded and will not want their data, even if it’s just metadata, involved in a machine learning model. There are customers who are contractually obligated to be privacy-minded (such as customers handling healthcare data), and regardless of how they feel about LLMs, need to ensure that no such data is compromised. And there are customers who sign specific service agreements as a part of an enterprise deal.
Some things that we did:
- Do a full security and compliance audit of LLM providers. Spoiler alert: only OpenAI could meet our requirements for now. Props to them for building a robust service!
- Draft new terms and conditions that detail what data we send to OpenAI, that we make no claim over data sent or data received, and that we do not guarantee particular results/outcomes, etc.
- Figure out what (if any) terms need to be changed in our overall terms of service, which hadn’t been updated since 2021
- Ensure these terms and conditions are accessible within the UI itself
- Ensure there are easy and obvious controls to turn the feature completely off
- Flag out any customer who signs a BAA with us. Although OpenAI’s platform controls would likely satisfy each agreement, we’d need to work with each customer on a case by case basis, and we didn’t want to hold up our initial release
Under a longer timeline, none of these would have been special or challenging, but we had to do this in under a month alongside all the other product, engineering, and go-to-market work. You might think it’s unnecessary to do this sort of thing for an initial launch, but it is if you care about keeping your customers trusting and happy.
Early Access programs won’t save you
Finally, it seems that the trend in AI right now usually falls into two buckets:
- Someone releases demoware, generates hype, and it’s short-lived because it’s demoware
- A company makes a big press release announcing an early access program paired with really snappy marketing copy and videos but no actual product you can try (…because what they’re building is much less impressive than the marketing material 😉)
I’m here to tell you that the early access program won’t save you from the problems I talked about in this post. Sorry. Unless your “early access program” is so broad that you actually have a large, representative sample of users, all you’re going to accomplish is fooling yourself into thinking that your product behaves well for most user input.
The reality is that this tech is hard. LLMs aren’t magic, you won’t solve all the problems in the world using them, and the more you delay releasing your product to everyone, the further behind the curve you’ll be. There are no right answers here. Just a lot of work, users who will blow your mind with ways they break what you built, and a whole host of brand new problems that state-of-the-art machine learning gave you because you decided to use it.
Interested in trying Query Assistant and finding ways to break it? Get Honeycomb today. It’s free.
Want to learn more about improving your LLMs in production? See how observability helps.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.