The Future of Software is a Sociotechnical Problem
“Sociotechnical” I learned this word from Liz Fong-Jones recently, and it immediately entered my daily lexicon. You know exactly what it means as soon as you hear it, and then you wonder how you…

By: Charity Majors

I learned this word from Liz Fong-Jones recently, and it immediately entered my daily lexicon. You know exactly what it means as soon as you hear it, and then you wonder how you ever lived without it.
Our systems are sociotechnical systems. This is why technical problems are never just technical problems, and why social problems are never just social problems.
I work on a company, Honeycomb, which develops next-gen observability tooling. But I don’t spend my time trying to figure out how to get more people to use observability tools. Observability alone can’t solve anything, it’s just a necessary part of the solution.
What I do spend my day thinking about is the future of building software. How can we convert the creative fuel of people’s labor into healthier teams and more reliable, resilient systems? We are incredibly wasteful of the creative fuel that people pour into the process, and the result is that we have unreliable, opaque systems hairballs that nobody understands — which are then operated by stressed, burned out humans who are afraid to touch them.
What if we had:
- a future where your code goes live a few seconds or minutes after you commit your changes, and this is all very predictable and boring
- a future where everyone owns their code in production, and you actually look forward to your own turn on call
- a future where all the energy you pour into writing code and building systems genuinely moves the business forward, and you are rarely frustrated or lost or misled by those systems
- a future where the debugger of last resort is not the engineer who has been there the longest, but the most curious person
- a future where shipping software is not scary.
What do you think, does this sound achievable? Easy? Or are you thinking “never gonna happen for my team in this lifetime?”
This is all much more attainable than you might think.
The future is here, it is just unevenly distributed.
I have lived in the future. It’s why I started this company — I got a brief glimpse of what I now think of as ODD, or observability-driven development, a world where the best engineers wrote code with half their screen taken up by their editor, half by a tool where they were constantly watching and poking at and playing with that code live in production. The code they wrote was better. The systems they built were understandable, in a way I had never seen before.
Going back to a world where people write and ship blind was unthinkable. Not an option.
We hear echoes of this from Honeycomb customers now: “This is incredible. I can never go back.“
Because the teams who invest in these sociotechnical practices are radically more productive and happy than those who don’t. They move so much faster and with more confidence; their systems are more reliable and better understood; they amass dramatically less technical debt and can do far more with radically fewer people. They attract and retain better candidates.
And as a software company, this is how you win.
We are in the Middle Ages of software delivery.
The Stripe developer report reports that engineers spend at least 40% (self-reported) on miscellaneous technical bullshit that keeps you busy, maybe blocks you from working on what you need to work on … but does not move the business forward. Just sit with that a sec. Forty percent. Optimistically.
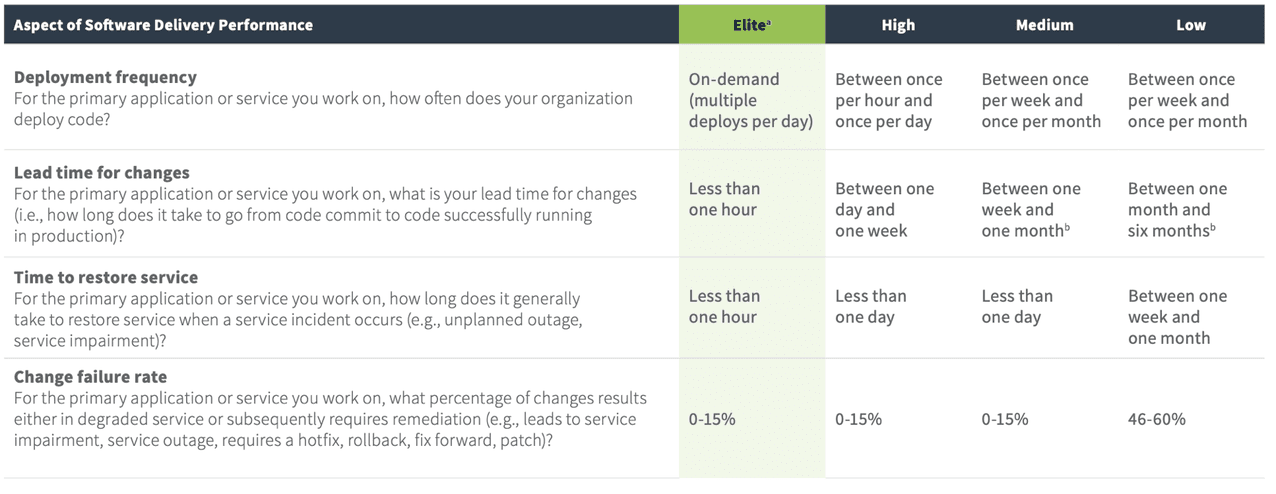
Or maybe you’re familiar with the DORA report. The honeycomb team’s engineering stats are an order of magnitude or two better than their Elite teams, which represent the top 20% of all teams. (“But the company is young, easy for you to say!” you may protest. Sure, we are relatively young … a little over four years old. We are also a fast-growing platform with unpredictable, spiky traffic composed of user-generated streams of content that we have no control over.)
I wish I could tell you “just buy Honeycomb and voila! Get high-performing teams!“
That is not what I’m saying. It is not that easy.
It’s a sociotechnical hole, and only a combination of technical fixes and social change will get us out of it.
A sociotechnical recipe for high-performing teams
But lots of smart, creative teams are out there working hard on this and sharing their findings. As a result, we know a LOT more about what contributes to a solution than we knew even just a year or two ago. You will be forgiven for skimming this very long list:
- Blameless retrospectives
- Automatic deployments triggered on each commit, single commit per deploy
- Removing human gates in the deploy pipeline
- Good test coverage, instrumented test harness
- Shared conventions around instrumentation
- Training, education, collaboration
- Code reviews and mentoring
- Promoting people for their value as team members and force multipliers, not just raw coding ability
- Interview processes that value strengths, not lack of weaknesses
- Shared value systems and organizational transparency
- Welcoming of diverse viewpoints and fresh eyes
- Teams that value juniors and know how to train them up
- Tooling that rewards curiosity
- Job ladders that value communication and independent initiative
- Encouraging software engineers to own their code from end to end
- Encouraging SRE types to work more like product teams
- Adopting SLOs, SLIs, and aligning on call pain strictly with user pain
- Making sure everyone gets enough sleep and time off
- Observability tooling (in the technical sense, as I define it here; not in the old fashioned sense of “metrics, logs and traces”)
Observability is only a one piece of the solution … but it is a necessary piece that should be actively frontloaded if your efforts are to have maximum impact.
Observability is about the unknown-unknowns
Rolling out o11y tooling is like turning on the light and putting on your glasses before you start swinging at the pinata.
To get at the candy inside — the real actionable user and technical insights — you need to be able to interactively slice and dice in real time, break down by high cardinality dimensions, and ask those new questions, the ones that you couldn’t have predicted you would need to ask. This is the minimum viable technical functionality you need in order to explore exactly what is happening in production, what happened when you deployed a particular piece of code, what happened when that user reported that bug. That’s why previous iterations of monitoring were not enough.
Observability in the modern technical definition is about answering the unknown-unknowns, and it is necessary. With observability, all things become easier. It is a force amplifier for all your other efforts.
If you don’t have observability — if you only have metrics, logs, and/or traces — all you can ask will be those questions that you predicted and defined in advance. You are swinging out at the pinata in the dark, or where you think it was yesterday or last week. It might not be completely prohibitively impossible, but it’s a damn sight harder and a lot comes down to luck.
Observability is a necessary ingredient. But everything matters.
People often kvetch at me “yeah, but anything’s easy when you have the best engineers.” They have this exactly backwards. Observability-driven development is what makes great engineers. Observability is what enables you to peek under the hood of the abstractions, it grounds you in reality, forces you to think through the code all the way to how the user will use it. It tethers you to your users and lets you see the world through their eyes.
TDD → ODD
Learning to check your assumptions vs reality was the argument for TDD (test-driven development). That makes you write better code, indisputably. But tests stop at the edge of your laptop! Tests imperfectly mock a predictable subset of reality. Testing in production means replacing the artificial test sandbox with reality.
If you believe TDD makes you a better developer, you should be hungry for the developer you will become using ODD.
I am cautiously optimistic that the industry will embrace observability in far less time than it took to adopt TDD and metrics. Mostly because it is much, much easier to do things this way. It’s actually much harder to do things the bad old ways, what with all the hacks and workarounds.
And every little bit helps. Every one of these changes will, if you embrace them, make your people happier and more productive.
Observability-driven development is what creates great software engineers.
The greatest obstacle between us and a better tomorrow is this pervasive lack of hope. (The second greatest is our perverse pride in our Rube Goldberg hacks & sunk costs fallacy.)
Most people still have not experienced what it’s like to build software in a radically better way. Even worse, most people don’t see themselves in the better world I describe. They don’t think this world is meant for them.
I don’t know how to fix this yet. But if we only succeed in making life better for the elites, we will have failed.
Observability is for everyone, and it is easier if you do it first. Observability makes every technical effort that comes after it sooooo much easier to achieve. Observability is what creates great engineers, not vice versa. Start at the edge, instrument some code, and work in. Rinse and repeat. You got this.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.