The True Cost of “Search-First” Problem-solving on Your Production Systems
The search-first problem-solving approach—meaning “open up the log search tool” (Splunk, ELK, Loggly, SumoLogic, Scalyr, etc)—is a costly and time-consuming operation during which the true source of a problem is rarely pinpointed in short…

By: Michael Wilde

The search-first problem-solving approach—meaning “open up the log search tool” (Splunk, ELK, Loggly, SumoLogic, Scalyr, etc)—is a costly and time-consuming operation during which the true source of a problem is rarely pinpointed in short order. Log search tools require work by the user to transform text strings into fields that are ready for statistical analysis.
In comparison, the analytics-first problem-solving approach offered by Honeycomb helps you observe and gain a better understanding of production systems behavior. This approach allows you to get to the goal of your investigation in a faster, more flexible way. If “time is money,” it is very easy to spend WAY TOO MUCH of your money on the time it takes to find problems in your production systems.
- Search-first – A “search-based” system ingests log & metric data and generally relies on the user to provide the right text to locate a set of results that may or may not prove to be useful. Search strings are then refined to create a result set that may be helpful. Given that a standard result set of text-based logs may include pages of 10-25 results, it is necessary to have those results transformed into structured data. It is only through parsing or extracting structure from logs that analytical observations can be made.
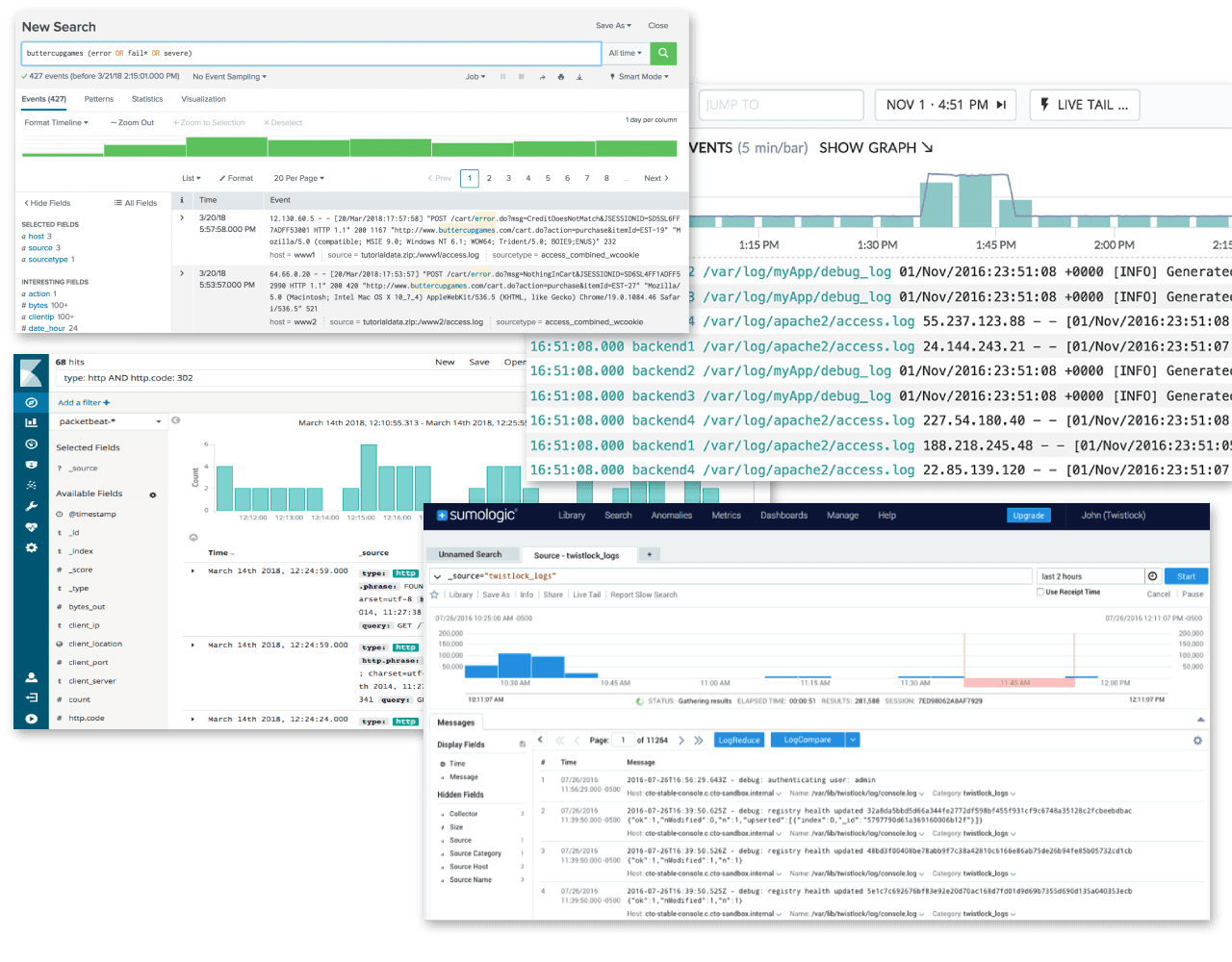
- Analytics-first – An “analytics-based” system ingests structured data and instantly provides the ability to query, perform mathematical comparisons, and provide visualizations to more easily spot trends, patterns, or outliers. These features are completely common for most business analytics tools yet are rare in most developer-and-operations-centric tools for production system analysis–with the exception of Honeycomb. Analytics and visualization allow us to begin to understand the nature of the problem right away, and at the same time drill into the details of what is really going on.
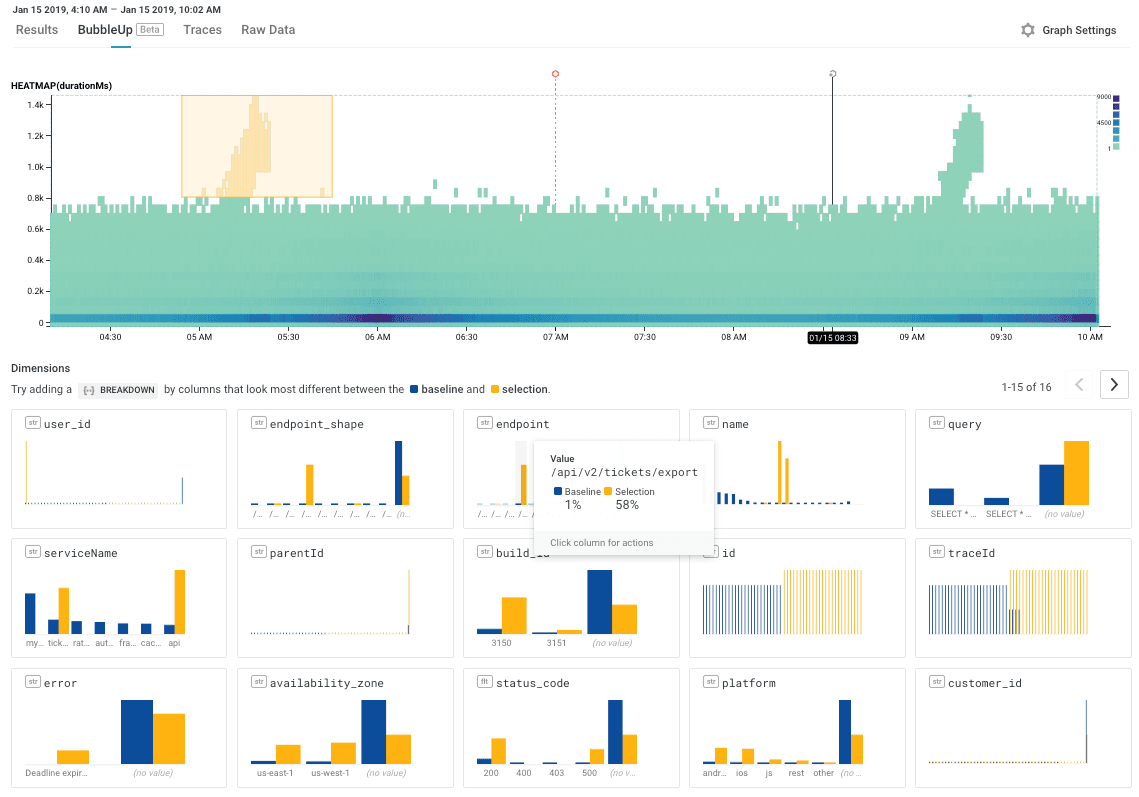
Welcome to the age of analytics-first!
We are rapidly approaching a world where search is less than necessary. Software owners (developers and ops teams) are expanding the telemetry their applications output in production. With the advent of modern analysis tools like Honeycomb that are built on dynamic columnar-storage engines that support high-cardinality data, you can ask super-specific questions of your data. Using Honeycomb becomes an “analyze-first” experience where “tools borne of the log search era” seem slow and arcane; by comparison Honeycomb never pre-aggregates data, stores the raw event, provides sub-second query response over large datasets and illuminates request behavior with distributed tracing. Additionally Honeycomb provides groundbreaking anomaly detection features like BubbleUp to provide you with an experience that helps you “stop guessing, and start knowing”.
The legacy of log search
With the rise of online services, distributed web-based systems, and the cloud, IT ushered in the practice of using “machine/log data” as a source of analysis on everything from systems troubleshooting, security investigations, and auditing, to dashboarding every activity that could be measured. This era gave rise to log search tools like Splunk, LogLogic, SumoLogic, Elastic ELK, and many others. Logging became the standard practice to output telemetry from production systems. As systems got larger and more complex, the log data volumes skyrocketed (and so did the dollars spent on managing all of that data). As a result, search & indexing software was a natural choice to access and process semi-structured log data arbitrarily created by developers of production systems; let’s just call it “the log search era”. (Disclosure: The author is an expert on log search as he spent 12 years building the log search industry as Splunk’s first sales engineer, evangelist, and customer advocate.)
Log data is often considered “a categorical record of all things that happen to distributed systems.” While this is a bit of a generalization, it is still a fairly accurate statement. Metrics, of course, are a time-based aggregation of data points about a specific part of a system. Both are helpful in measurement. However—like the FAX machine—log search has stagnated innovation. Log search tools offloaded the job of creating intentionally well-formed, meaningful “events” from the developer onto the then-owner of the production system. While the attempt to create “signal from noise” is quite noble, the search tool can only do so much with the data that’s been sent to it; often the logs are messy and are missing necessary data and linkages to really help solve production problems.
As a software owner, it is hugely beneficial for you and your teams to have the best and most structured telemetry emitted from your system. Isn’t it time you consider how you are currently spending a lot of your budget on log search tools? Create awesomely wide “units of work”-style events, implement distributed tracing and you won’t need to rely on log search tools for production system outages!
If search works for the web it must work for logs, right?
We use search to trawl the web’s massive data set to find what we’re looking for. Web content search engines like Google really only work well because of the context it creates–what it knows about you and about the linkage between pages. When I speak with developers and ops teams, I usually ask “How do you go about solving problems in production systems?”. The answer typically starts with “well, we check some dashboards” and ends with “search the logs”. Unfortunately, it is not currently possible for machines to understand the true context of the telemetry emitted by, or captured from production systems. There is no PageRank for log data, as there is rarely any linkage between log events. Yet still, we search.
Log search tools need all of your data because:
- Log search vendors try to satisfy a volume-based pricing model by motivating the user to ingest All data while usually paying a premium for it. Public company stock prices rely on you storing all of your log data with these vendors, and since your systems aren’t getting smaller or less complex, you’re almost powerless to stop the spending.
- Log search systems are not built for analytics from the ground up, rather they exist to store and find history. When troubleshooting production systems, their behavior is revealed through statistics. Sampling is one of the best statistical methods to represent behavior without storing every bit of data. Analytics-based systems like Honeycomb account for sample rate not only are the charts correct, storage efficiency is maximized. On the other hand, log search tools are not as effective when data is sampled at its source, as to them, data is missing. As a result, all of your data is required to make a reasonably accurate statistical analysis possible.
“Basic” log events are only part of the story. Tracing is where all the good stuff is happening
Log events will often record a request that happens in your production systems. While it may be possible with log search tools to reconstitute session patterns with what I call “search language stitching operations”, users of these tools often lack the necessary detail to help developers understand how their software is behaving. A recent customer said to me, “Before Honeycomb, we speculated wildly about how our systems were behaving.” A good part of the visibility this customer got with Honeycomb was due to using a Honeycomb Beeline. Beelines are automatic instrumentation plugins that provide request capture and distributed tracing. It is tracing that gives us an understanding—for each request—of what its life was like; how it behaved; what duration each step took; what its resulting success or failures were. As we migrate to cloud-native architectures, distributed tracing is even more critical to understanding how an ephemeral, black-box, service-oriented app is truly behaving.
No more searching in the dark! Illuminate with charts and visualization first! Trace early and often!
While everyone has some sort of log search tool, in the words of Princess Elsa from your kids’ favorite movie “Frozen,” it may be time to “Let it go!” The era of log search is coming to an end, as the cost in your time and money has become too darn expensive.
Always Bee Tracing
We encourage you to embrace distributed tracing with a Honeycomb Beeline, OpenTracing or OpenCensus. Come learn about tracing onsite in San Francisco at our Tracing Workshop. You’ll experience how to instrument an application and see what the analytics-first life is like.
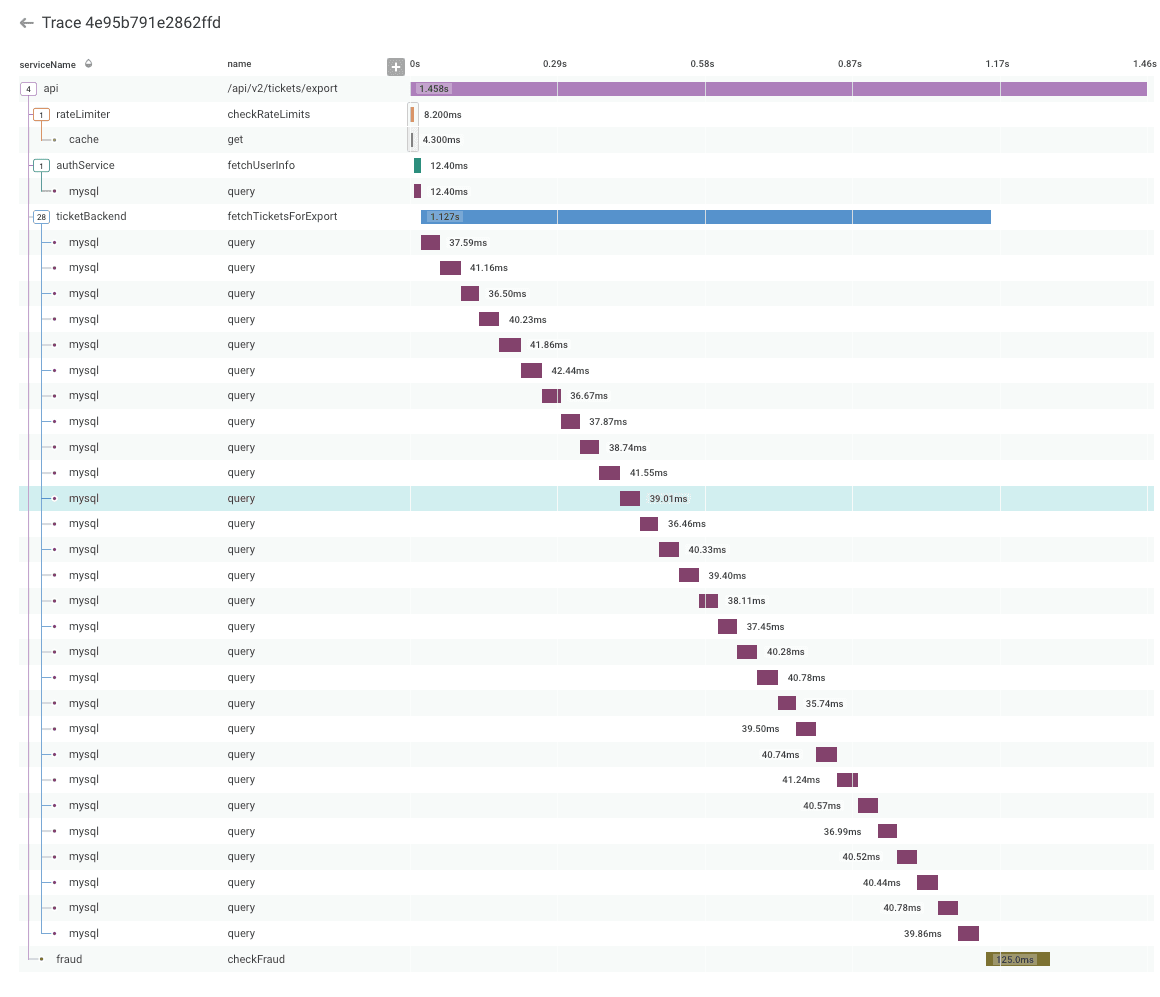
Warning: You may never want to go back to searching logs after you try Honeycomb.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.