Twelve-Factor Apps and Modern Observability
The Twelve-Factor App methodology is a go-to guide for people building microservices. In its time, it presented a step change in how we think about building applications that were built to scale, and be agnostic of their hosting. As applications and hosting have evolved, some of these factors also need to. Specifically, factor 11: Logs.

By: Martin Thwaites
The Twelve-Factor App methodology is a go-to guide for people building microservices. In its time, it presented a step change in how we think about building applications that were built to scale, and be agnostic of their hosting. As applications and hosting have evolved, some of these factors also need to. Specifically, factor 11: Logs (which I’d also argue should be a lot higher up in the ordering).
What is the Twelve-Factor App methodology?
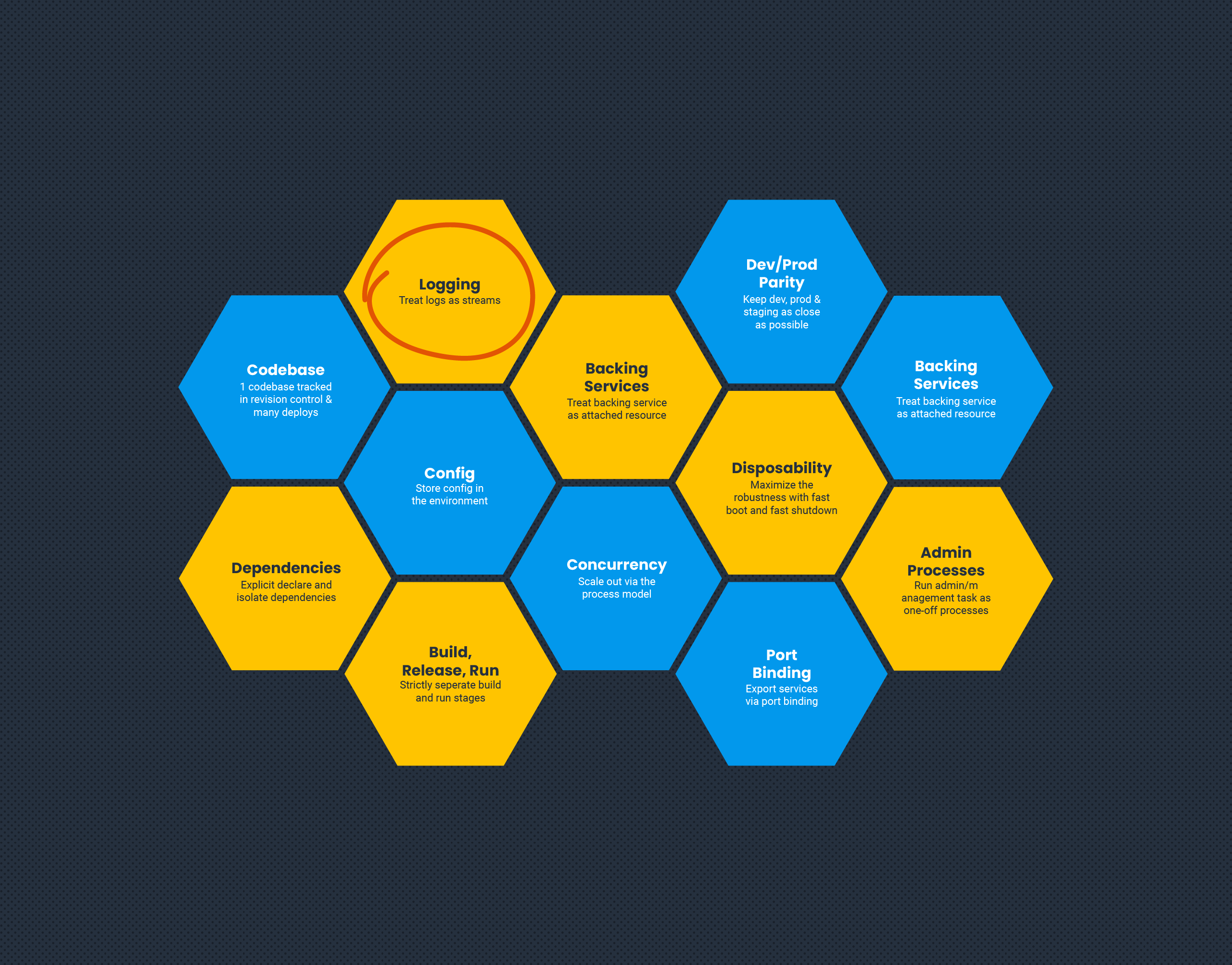
Defined by the teams at Heroku in 2011, twelve-factor is a methodology for building apps in an independent, scalable, and ultimately composable way in order to create a system that works together. This methodology held up well over the past decade due to its principles being well thought through and agnostic of implementation details.
What is factor 11?
Factor 11 refers to treating logs as event streams. More specifically, “A twelve-factor app never concerns itself with routing or storage of its output stream.”
The intent here is very clear. Don’t make operators of your service (whether that’s you or another team) think about anything other than a stream of data. We want to avoid mounting a disk for logs to be written to so they can be tailed and aggregated. We should strive for standardization so that all services have the same output.
These are great goals, and the intent is still valid. However, this factor does go into implementation details of using stdout to push logs. This is where I think we’ve evolved as an industry.
What is OpenTelemetry, and why does it matter here?
OpenTelemetry brings together different mechanisms that engineers use to output telemetry signals from their systems. These signals are known as logs, traces, and metrics.
OpenTelemetry provides a unified way to think about telemetry across languages and frameworks, and provides a consistent, standardized format to forward that data out of the application. They created the OpenTelemetry Line Protocol, which is a protocol and set of standards on how to output logs, traces, and metrics from your application so that backend observability platforms can take them and provide visibility and insights.
You’ll notice that there are similar goals here, and therefore I believe that OpenTelemetry supersedes factor 11.
What about stdout?
The idea around using stdout and essentially “logging to the console” was to provide a consistent transport for the data in such a way that external aggregation systems could gather it.
Unfortunately, this requires conversion and writing data in text format, which is not always the most efficient way. In addition, as we promote structured logging as an industry, we’re essentially serializing information just to deserialize it later.
Within OpenTelemetry, there are now better, more efficient ways to send this information, such as gRPC and HttpProtoBuf. Due to the documentation/standardization of environments across languages, operators can forward that information wherever they want without changing the code.
Conclusion
Twelve-Factor App Methodology is still valid today if you look at the intent. When looking at the logging portion, think about this as a wider concept of “telemetry” and consider whether stdout is, in fact, the right way to transmit the data.
If you want to learn more on logging, we have a good blog on surfacing buggy patterns with logs. In the meantime, feel free to try Honeycomb today. Our free-forever tier is quite useful!
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.