Intercom <3 Honeycomb

By: Varsha Patel

Intercom
Intercom brings messaging products for sales, marketing, and customer service to one platform. More than 20,000 businesses use Intercom to connect with a billion people worldwide.
Environment
- Monolithic Rails app
- External services written in Ruby and Go
- 100% AWS
Goals
Intercom’s customer-centric culture drives operations, but they knew they were not detecting key error conditions and performance issues affecting individual customers.
They needed to be able to pinpoint the exact events causing an issue and the exact customers affected, but their existing tools could not handle the high-cardinality nature of the data.
We’ve been through a few metrics products. When you try to break data down by high-cardinality fields like customer app IDs, or even host IDs, it just kind of breaks their UIs and increases cost many times because everything is stored individually as separate time series.
Jamie Osler
Product Engineer at Intercom
What They Needed
- An observability service that allowed engineers to investigate problems across high-cardinality fields such as unique customer app IDs attached to relevant events and metrics
- Support for adding and removing data from instrumentation at will without having to reconfigure dashboards, queries, alerts, etc
Honeycomb @ Intercom
We’ve been told so many times that logging customer ID was impossible and our vendors throttle us or complain, but Honeycomb just handles that.
Conor O’Donnell
Product Engineer at Intercom
Intercom engineers primarily use Honeycomb’s Ruby and Go libraries to instrument their API services and then use Honeycomb to investigate the behavior of those services. They’re continuing to improve their instrumentation coverage as more engineers discover the value of lightning-fast investigation.
When investigating a problem, I want to know if it’s caused by a particular customer. Being able to break down metrics on higher-cardinality fields gives very actionable insights.
Jamie Osler
Product Engineer at Intercom
One piece of data Intercom tracks is ‘message matching duration’. This is the time it takes to check if someone should receive a message through the Messenger, a popup chat module used to engage with users on a per-customer-site basis. Intercom’s team knew this was sometimes a slow operation and had tried with other tools to get greater visibility into the problem, but until one of the engineers added the Messenger timing data to their Honeycomb dataset, they had not been able to get insight into what/who was influencing the P50 or P99 values.
We never dug into it on a per-app basis because we just couldn’t. Conor O’Donnell, Product Engineer at Intercom
Conor O’Donnell
Product Engineer at Intercom
Upon noticing the new data in Honeycomb, another engineer ran a short query:
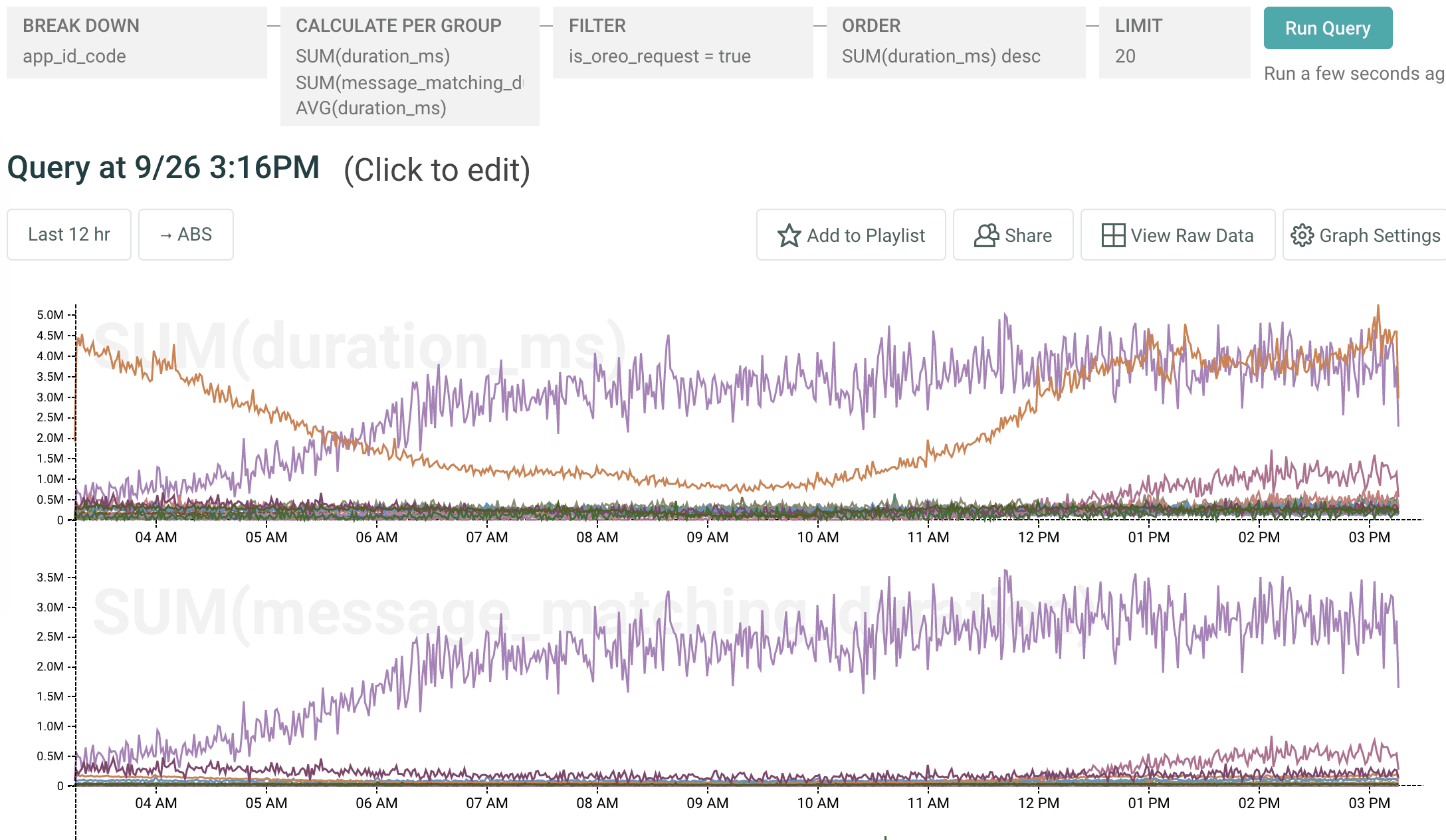
The top graph shows total duration of all requests across all customer app_id_codes. The bottom is total duration of message matching across all apps. The single app in purple is taking up much more message-matching time than any other app.
With Honeycomb, we were able to get a breakdown of message matching duration by customer and saw that one customer was a huge outlier there, accounting for 55% of all server time spent doing that operation-and over 10% of overall server CPU usage for the fleet!
Conor O’Donnell
Product Engineer at Intercom
Based on what they learned from a single 15-second query in Honeycomb, Intercom is now able to plan for the future of their service. Without Honeycomb, they would not have been able to discover the extent of that one customer’s behavior, their use case, and its true impact.
This is the best kind of performance problem to have, when the customer is really trying to use the system.
Conor O’Donnell
Product Engineer at Intercom
Intercom also uses Honeycomb to instrument ElasticSearch services: for example, to see how badly additional regexes in queries translate into performance, or to get insights into how well a cluster set is going to scale with a particular query load.
And of course, Honeycomb is there when something goes truly sideways:
There have been outages where, without Honeycomb, it would have taken us significantly longer to get to the answer.
Jamie Osler
Product Engineer at Intercom
Thanks to Jamie, Conor, and everyone else at Intercom who helped us put this story together! Stories like this are exactly why the honeybees are doing what we’re doing.