How to Debug Microservices
Microservices are part of a modern development model that focuses on small, loosely-coupled, independently-deployable services instead of a single monolith of code. Companies like Netflix, Twitter, and Amazon are forerunners of this approach (that’s traffic flow between Netflix services in one AWS AZ you see to the right).
Microservices are hard to debug because behavior can be emergent and small glitches or failures in one part of the system can cause large scale outages. We may have to jump through many services and network boundaries just to debug a single request. We can’t just grep through log files, or rely on stashing aggregated metrics. We need to be able to ask questions and break down data to the level of individual requests, or users, or endpoints, etc.
We built Honeycomb to answer those questions–to deal with microservices, serverless, distributed systems, polyglot persistence, containers, CI/CD–and build an understanding of how your systems and software actually work. You can’t debug what you don’t know.
What to do
Build observability into your microservices:
- Instrument code verbosely. Everything flows from this. Wrap every network or service call with as much context and detail as possible.
- Persist unique request identifiers throughout the stack, for every service and every data request (drop it in a db comment field if nothing else).
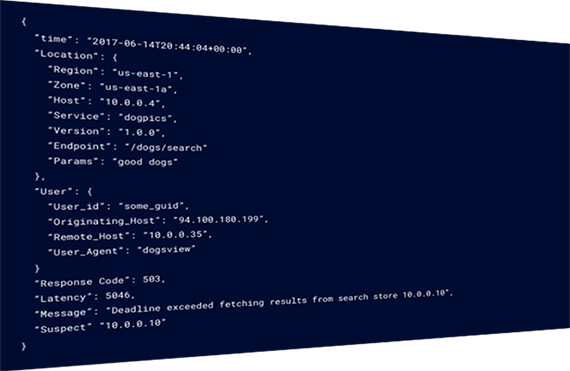
- Emit events with rich context, including high-cardinality data like
UUID,user_id,event_id, shopping_cart_id, etc. Like this! - Structure your data.
- Don’t wait until you can perfectly instrument everything. Start at the edge, then instrument every pain point as it arises. Over time you’ll drift towards full instrumentation coverage (like code coverage for testing).
- Don’t forget to gather events from the perspective of databases and clients: they will often disagree with our internal view on timing and errors–which is useful information.
Observability requires rich instrumentation, not to poll and monitor for thresholds or defined health checks, but to ask any arbitrary question about how your software works. An observable system is one you can fully interrogate.