Shipping on a Spent Error Budget
Modern software services are expected to be highly available, and running a service with minimal interruptions requires a certain amount of reliability-focused engineering work.

By: Paul Osman
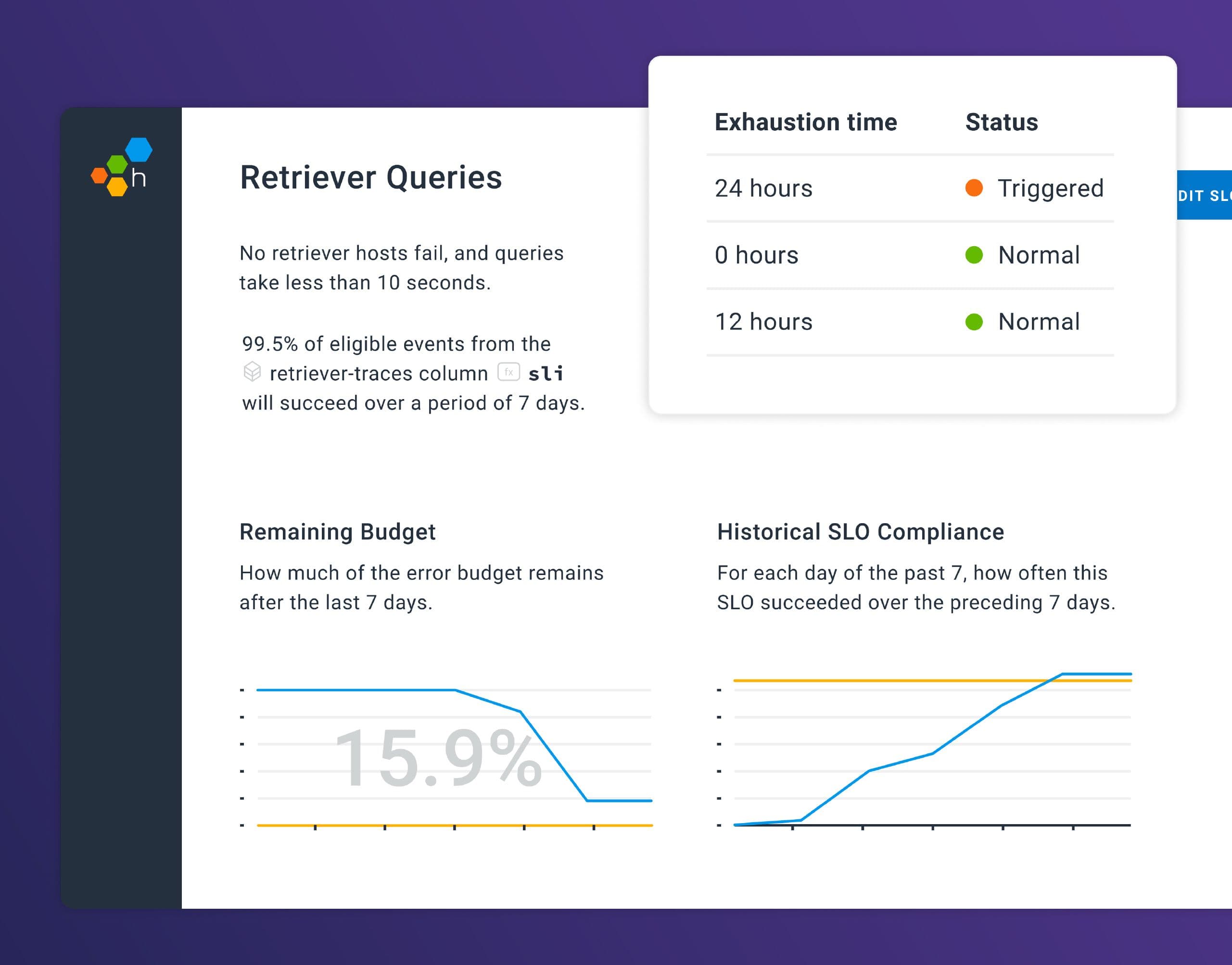
Modern software services are expected to be highly available, and running a service with minimal interruptions requires a certain amount of reliability-focused engineering work. At the same time, teams also need to build new features and improve existing ones, so that users are delighted and don’t churn.
Balancing these two categories of work is a challenge for every engineering team. Some teams opt for a static split, like 30% of their time should be spent on making the product more reliable. But increasingly, teams are finding that their reality is dynamic and there is no predefined split that can solve this tension. Instead, they are relying on service level objectives and error budgets to help guide and negotiate priorities with business stakeholders. This post is about a time when we used a burned error budget at Honeycomb to change how we shipped a feature.
Service level objectives
A service level objective (SLO) specifies the desired availability and reliability targets for a service. It is usually made up of one or more service level indicators (SLI), which are individual measurements for performance.
An example of an SLO would be that 99.95% of requests in a given month must respond successfully and in under 150 milliseconds. Notice that there are two measurements, success (likely measured by response status code or similar) and latency (the request should complete in under 150 milliseconds). These two measurements determine an error budget. 99.95% availability translates to roughly 20 minutes of downtime in a month, so this is a pretty conservative target.
As long as a service is meeting its objective, product velocity can continue at a high rate. Once a service experiences enough downtime, or latency, that it exhausts its error budget, attention should probably shift towards shoring up the service’s performance or reliability.
At Honeycomb, we use our own SLO feature to track how successfully we are meeting our customers’ needs. An SLO at risk of being missed will result in a PagerDuty incident and escalation to the appropriate on-call engineer. When an SLO is missed, we usually opt to shift more of our attention to reliability-focused work, making changes that make it easier to ship while reducing the risk of downtime. This could involve addressing some long-known issues, or working on tooling or anything else that helps engineers ship more quickly and more safely.
The incident
Last year, we added support for the OpenTelemetry Protocol (OTLP) to our ingest service, shepherd. When we started working on this project, we rolled out a change that attempted to bind a socket to a privileged port. This caused our shepherd service to be unable to start and, therefore, we could not auto-scale. Unfortunately, we were unable to catch this in time to prevent the change from rolling out to our production cluster, and we suffered 20 minutes of unusually high response times. One of our service-level indicators for shepherd is that events should be processed in under 5ms per event in a batch 99.9% of the time. This incident burned through that SLO, leaving us without any further error budget for the month!
We didn’t want to stop working on OTLP support, but we knew that we should take a different approach. After discussing a few options, we decided to invest some time and effort in building a separate shepherd cluster that only served OTLP traffic. That way we could continue to work on the feature, continuously deploying our builds, but would have much less of a chance to negatively impact our existing production traffic. No customers were using OTLP yet, and we hadn’t announced support, so we could safely incur downtime on that cluster without impacting anything but our own testing and load testing efforts.
Separating traffic into swimlanes
Thankfully, AWS had recently announced end-to-end support for gRPC in their Application Load Balancers. This allowed us to create a specific target group and listener rules to route gRPC traffic to our OTLP cluster. We use Terraform to manage our AWS resources so we created the appropriate auto-scale group, target group, and listener rules to separate out our existing traffic from the new gRPC traffic. The listener simply checked the Content-Type header in the incoming HTTP/2 request. If it was equal to application/grpc, the request was routed to the target group associated with our quarantined shepherd cluster.
ap
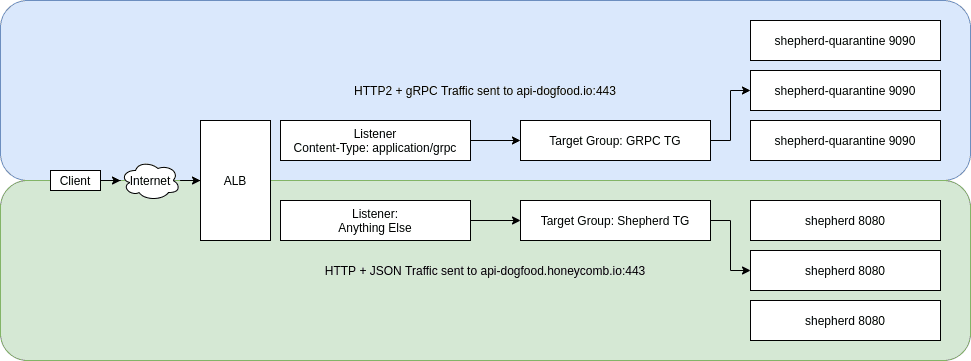
With this additional infrastructure in place, we could begin deploying a branch to the quarantine cluster. In order to minimize differences from the main branch, we rebased daily. Failures in the quarantine cluster would not impact our SLO because it wasn’t serving real customer traffic. The team was able to iterate quickly and deploy their changes to a cluster in our production environment continuously.
When the feature was ready, we canary deployed the branch to one node in our regular production cluster and watched. After we had gained enough confidence that our changes hadn’t introduced any problems, we continued rolling it out and eventually merged it into our main branch. The same version was once again running across our infrastructure. We could then tear down the custom listener rule and target group. Using this approach, we were able to ship support for OTLP in a short amount of time and start getting feedback from real customers!
SLOs encourage discussion
The moral of this story is that there is NOT a simple, straightforward way to proceed when an SLO is missed. Instead, we learned that SLOs are a very useful prompt to have discussions with your team and stakeholders about how best to proceed. I was very happy to see that in this case, we heeded our own advice while continuing to iterate quickly on a new product feature that added value for our customers. We spent extra time working on setting up the new infrastructure and took on some risk merging the work back into our main branch, but overall, it was well worth taking a small pause and investing in infrastructure that allowed us to move quickly while minimizing risk to our existing customers.
Want to learn more about how Honeycomb SLOs work? Sign up for one of our weekly live demos and get your questions answered live!
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.