Treading in Haunted Graveyards
Part 1: CI/CD for Infrastructure as Code At Honeycomb, we’ve often discussed the value of making software deployments early and often, and being able to understand your code as it runs in production. However,…

By: Liz Fong-Jones
Part 1: CI/CD for Infrastructure as Code
At Honeycomb, we’ve often discussed the value of making software deployments early and often, and being able to understand your code as it runs in production. However, these principles aren’t specific to only your customer-facing software. Configuration-as-code, such as Terraform, is in fact code that needs to go through a release process as well. Lacking formal process around Terraform deployment means a de-facto process that generates reliability risk.
Our Terraform code used to be a mechanism of ensuring reproducibility of our environment from config, but it was still hard to debug when unexpected changes appeared in our terraform plan output. Was a diff because someone else also pushed a change from their branch that I’d be undoing? Was it because of someone pressing an AWS console button and introducing config drift? Was it because of a Terraform provider bug? Even the experts on the team were afraid to touch our Terraform configs, treating them like a haunted graveyard in which to seldom tread.
Two months ago, I spearheaded an effort to introduce to our infrastructure the same degree of rigor as we apply to our release binaries. In our previous process, nothing enforced that our engineers pushed exactly what was in source control, nor did we force synchronizing source control to AWS after landing a commit. Over the course of the project, we switched from engineers using direct token access to modify our production environment to centralized push-on-green deployment of our checked in Terraform configs with the AWS tokens living inside of the Vault instance backing Terraform Enterprise.
Building confidence in our processes also required adding safety rails to ensure that automated pushes were less likely to catastrophically break us. For instance, we started adding deletion protection to critical production instances, using Sentinel to enforce maximum step size changes to instance counts, and otherwise introducing continuous integration/verification to our configs. At first, we notified our operations slack channel on every automated change, but as we grew confidence, we no longer found value in being noisy about them.
The Terraform deployments were less risky and information about their occurrence was no longer seen as valuable signal. Just as we no longer push notifications to Slack on continuous binary release, we no longer needed to push notifications on infrastructure release. Mission success! Instead, we plan to add Honeycomb markers to datasets via webhooks to correlate infra pushes with our own observations.
While we could have rolled our own automatic Terraform deployments using our app CI provider CircleCI, we’d have incurred substantial risk and effort. Our customer Intercom’s motto, “run less software” rings true here. We’d have to support our own integrations and parse Terraform plan/apply output on our own. Beyond that, we as infrastructure providers ourselves recognize that paying those who develop the software we rely upon just makes good business sense. When we bought the Hashicorp product, we received not only a great Terraform CI/CD tool, but also support with Terraform core+provider issues and prioritization of our use cases.
We succeeded in our goal of making Terraform and our AWS environment less intimidating and manual to work with for our SREs… which was a step we desperately needed once investors started doing due diligence into our COGS (Cost of Goods Sold, in other words, how much it costs us to provide Honeycomb to a given customer).
Part 2: The Concrete Payoff
While reducing technical debt is all well and good as a philosophy, let’s talk about concrete benefits that we achieved by investing in paying down this technical debt. One of the upcoming features that the Honeybees are busy with requires creating a new infrastructure component. Without the ability to continuously deploy infrastructure, it would have been repetitive to stand it up across environments and tune it for production workloads. We were able to go from 2-4 Terraform deployments per week at steady state to 2+ deployments per day in support of our infrastructure objectives.
(sidebar: the first months of us using Terraform are mostly full of Charity swearing in commit logs and in code comments, then re-pushing a fixed set of commits; thus, high commit volume, but low actual productivity)
Like any SaaS analytics startup, our cloud bill is a significant fraction of our overall expenditure and a majority of the cost in our unit economics. As we’re in the middle of a careful look at our finances concurrent with investor due diligence… we came to the realization that our AWS bills had crept up and were now untenably high.
We were able to leverage our investment into modern Terraform to safely change our automatic scaling behavior to use target_tracking_configuration to target 60% CPU utilization on our ingest enforcement workers. Previously, we weren’t always reliably scaling down at night, because we were waiting for average CPU utilization to hit 40% before scaling down by a handful of instances, and that had stopped working months ago.
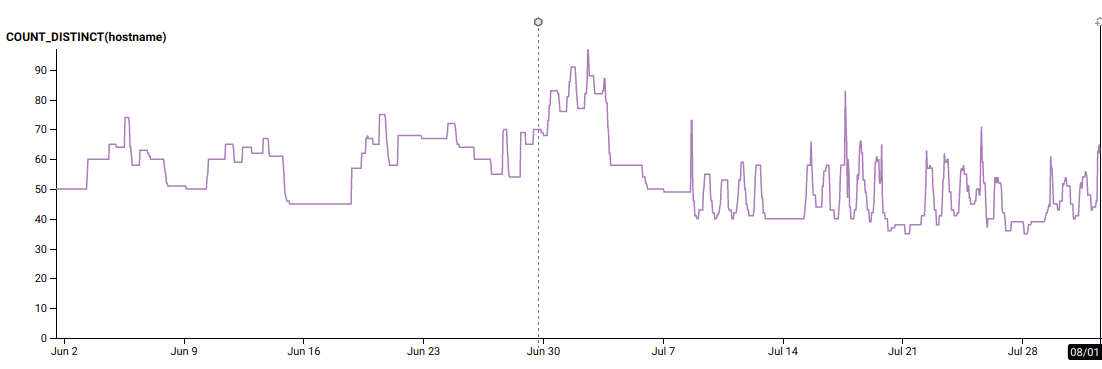
(note the change on July 8!)
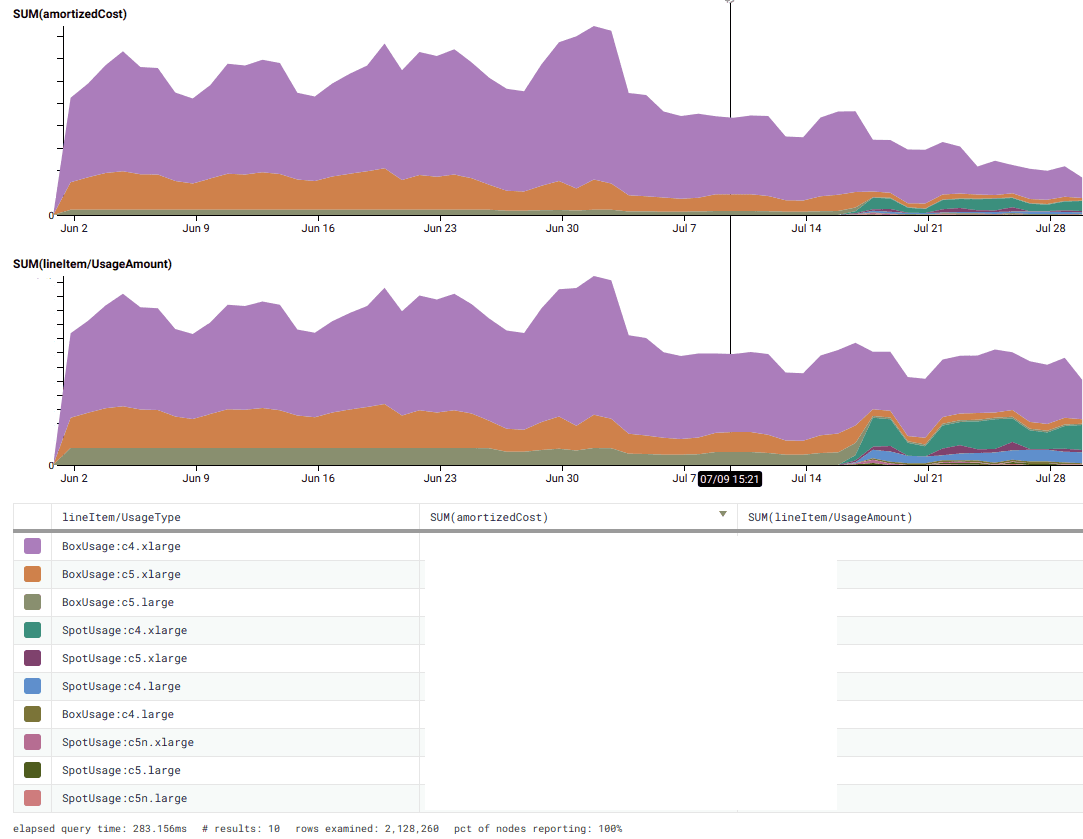
But even after dynamically scaling instance counts, we were still paying more than we had to. While we had reserved instances to cover our baseline workload, it didn’t make sense to continuously reserve additional instances we’d only be using half the time! Enter AWS Spot, which allowed for us to run preemptible instances at 70% off on-demand prices, as long as our workers could tolerate being restarted on 2 minutes notice if the spot price changed.
An AWS feature released in November 2018 allows for combining the autoscaling groups we were already using with Spot requests for peak load (and replace/reschedule instances automatically). With the old Terraform provider and language version we had been stuck on, we had no access to programmatically use the ASG Spot functionality; we’d have been forced to create separate Spot fleets that wouldn’t automatically register with the ASG. Ugh. But fortunately, we had upgraded our Terraform core and provider, so it was a simple 10-line Terraform diff to turn it on… and our bill suddenly got significantly better on July 17!
(yes, of course we use Honeycomb to analyze our bills! you don’t? well, we have a blog post for that… foreshadowing intensifies)
We had phenomenal success at cutting our ingest workers’ compute bill by 3x (the ingest/data transfer issue is, sadly, a longer story we’ll tell another day). In light of this savings using ASGs and Spot, we’ve also now started designing the aforementioned new data processing workers supporting upcoming features to tolerate interruption with off-host checkpointing, because it’s cheaper for us to run them as spot/preemptible instances with hot spares that can immediately take over, rather than running a smaller number of reserved instances.
Part 3: Lessons Learned
- Keep a closer eye on your AWS bill, and look for low-hanging fruit if it becomes a significant fraction of your OpEx/COGS, because chances are you can save a significant chunk of your entire company’s runway just by making a few tweaks. It may be easier than you think!
- Investing in CI/CD for your infrastructure as code can empower you to make significant cost-saving changes to your architecture with comfort rather than fear. We’ve saved tens of thousands of dollars per month, making the yearly subscription to Terraform Enterprise easily worth it. As of this writing, Terraform Cloud is a free offering that offers a subset of TFE’s functionality, so do check it out even if your budget is $0. But the savings do pay for themselves 😉
- Make sure your utilization-based automatic scaling is working correctly (e.g. using target_tracking_configuration), and that you are using Reserved Instances to cover your baseline off-peak workload. Your target utilization number might be different from ours; use SLOs to determine how hot you can run without violating your SLOs.
- If your daemons handle shutdown -h now in a timely fashion, return negative healthchecks, and checkpoint off-host/do an orderly shutdown, you can benefit from AWS Spot. It’ll save you a lot of money.
- Caveat: switching an existing ASG to spot requires handholding — it’ll try to spin up spot and terminate excess on-demand or reserved instances above on_demand_base_capacity, so set scale-in protection first and then manually release them a few at a time to prevent bouncing too much at once. (or reduce on_demand_base_capacity slowly)
- Caveat: Always proactively look out for limits on your AWS account, such as the number of spot instances you’re allowed to run. Otherwise, one morning you won’t be able to scale up when you need to (oops!).
- Templating your instances enables doing other fun things like being able to quarantine and profile misbehaving traffic using ALB rules and special target groups. (to be the subject of another blog post…)
Appendix with code
This is how our ingest workers are configured today, after all the changes we made:
resource "aws_launch_template" "shepherd_lt" {
...
}
resource "aws_autoscaling_group" "shepherd_asg" {
name = "shepherd_${var.env}"
min_size = var.shepherd_instance_min[var.size]
max_size = var.shepherd_instance_max[var.size]
wait_for_elb_capacity = 0
health_check_type = "EC2"
health_check_grace_period = 600
target_group_arns = [...]
vpc_zone_identifier = ...
mixed_instances_policy {
instances_distribution {
on_demand_base_capacity = var.shepherd_instance_min[var.size]
on_demand_percentage_above_base_capacity = 0
}
launch_template {
launch_template_specification {
launch_template_id = aws_launch_template.shepherd_lt.id
version = "$Latest"
}
dynamic "override" {
for_each = var.shepherd_instance_types
content {
instance_type = override.value
}
}
}
}
lifecycle {
create_before_destroy = true
}
}
resource "aws_autoscaling_policy" "shepherd_autoscaling_policy" {
name = "shepherd_autoscaling_policy_${var.env}"
autoscaling_group_name = aws_autoscaling_group.shepherd_asg.name
policy_type = "TargetTrackingScaling"
estimated_instance_warmup = 600
target_tracking_configuration {
predefined_metric_specification {
predefined_metric_type = "ASGAverageCPUUtilization"
}
target_value = 60
}
}
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.