Blog
Meet the Author

Explore Author's Blog
May 28, 2024
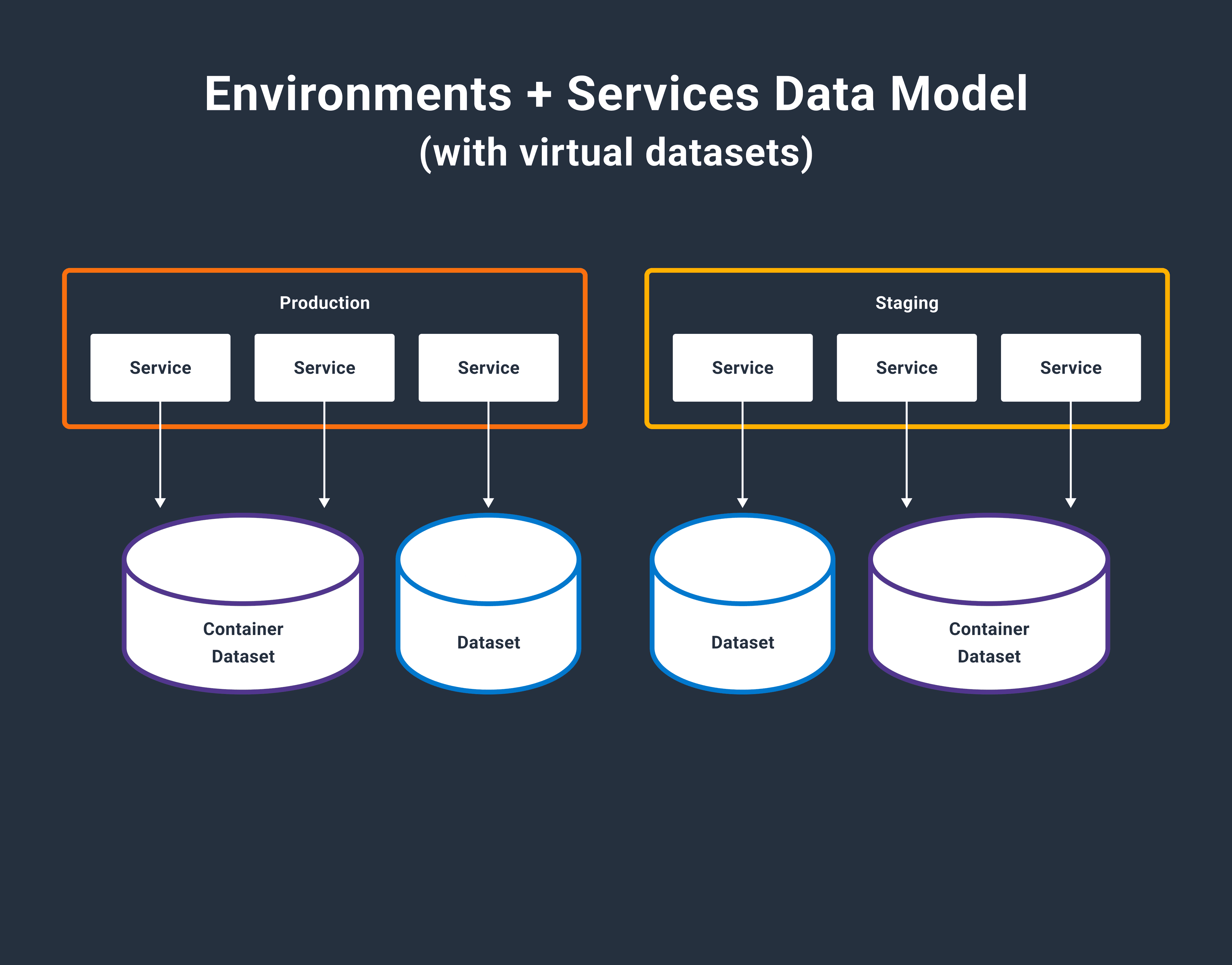
Virtualizing Our Storage Engine
Our storage engine, affectionately known as Retriever, has served us faithfully since the earliest days of Honeycomb. It’s a tool that writes data to disk and reads it back in a way that’s optimized for the time series-based queries our UI and API makes. As usage of this feature has grown, however, we’ve noticed Retriever creaking in novel ways, pushing us to reconsider a core architectural choice.