Incident Review: Meta-Review, August 2020
Every once in a while, teams or systems hit an inflection point where enough things change at once and the pattern of incidents shifts. We found ourselves at an inflection point like that last week.

By: Emily Nakashima
At Honeycomb, we’re lucky to work on a product that has a track record of relatively few outages and major incidents — so few that we sometimes fret about how to keep our incident response skills sharp. But every once in a while, teams or systems hit an inflection point where enough things change at once and the pattern of incidents shifts. We found ourselves at an inflection point like that last week. Between July 28th and August 6th, we experienced five incidents that affected our production or dogfooding environments, including three that resulted in partial customer-facing outages to our API or query capabilities.
We know that Honeycomb is an essential part of our customers’ production tooling and we take the availability and reliability of our product extremely seriously. To the customers whose usage of Honeycomb was impacted by these incidents, we are very sorry. We hope this post helps to both shed light on the factors behind these incidents and explain how we are working to prevent additional incidents in the future.
The Incidents
These are the incidents we experienced:
- 7/28 – DNS lookups slow or failing:Amazon’s Route53 DNS service had an outage that affected one availability zone (AZ) in us-east-1, and a small percentage of our infrastructure was in this availability zone. DNS lookups in this availability zone failed or were delayed. This caused a number of effects throughout our infrastructure, primarily manifesting as slight increases in error rates and overall latency. Our on-call engineer became aware of the issue when he was paged by an SLO burn alert. Our BubbleUp feature allowed him to quickly spot that only one AZ was affected, and he successfully moved instances out of the affected AZ to resolve the issue.
- 7/31 – Bad instance in our kafka dogfooding cluster: we received an alert about Kafka latency spikes in our dogfooding cluster. Disk I/O had gone to near-zero and CPU had spiked as well. We suspected a hardware issue, terminated the instance, and brought up a new one, which resolved the problem. We noted that our self-healing mechanisms didn’t work correctly in this case: they were waiting for a more complete failure before kicking in. We created a follow-up task to augment the self-healing mechanisms with a more comprehensive liveness test.
- 8/3 – Query engine lambda startup failures: A code change was merged that prevented the lambda-based portion of our query engine from starting. This is the portion of our query engine that runs queries against S3-based storage — typically older data. We didn’t catch the issue in our dogfooding environment or with automated checks (these typically run against newer data), so the change was later deployed to production, where users saw queries against older data fail to return results for about 90 minutes. We resolved the issue by rolling back to a previous release.
- 8/5 – Query engine panics: A configuration change targeting a different part of the code base caused the query engine reader to panic when trying to execute some common types of queries. We didn’t catch the issue in our dogfooding environment or with automated checks, so the change was later deployed to production, where users saw errors when attempting to run new queries for about 20 minutes. We resolved the issue by rolling back to a previous release.
- 8/6 – Storage engine database migration: We have a primary MySQL database that the engineering team spends lots of time thinking about, but our storage engine also has its own MySQL database that we discuss less often. We use database migration scripts to make changes to the schema of these databases. The migrations are checked in to our primary code repository and deployed as part of our regular deployment process. The process for deploying migrations to the primary database is well documented and we have safeguards built in to ensure the migration runs before code that requires the new schema deploys. However, this isn’t the case for the storage engine database, which sees migrations much less frequently — the most recent migration was four years ago, and that was the second migration ever. An engineer deployed a new migration not realizing the difference between the two deploy processes, leading to errors in our dogfooding environments. We were able to catch the issue before the release went to production and resolve it by running the migration before the new code deployed.
While we are in the habit of regularly doing internal reviews after every incident, we knew a cluster of incidents called for more scrutiny. After we performed our regular incident reviews, our CTO, Charity Majors, suggested a meta-incident review where we could step back, consider multiple incidents at the same time, look for underlying patterns, and reflect on where we might need to change our systems or practices.
The meta-review
Given the low frequency of past incidents at Honeycomb, we didn’t have a template for a meta-review. As our Platform Engineering Manager, Ben Hartshorne, said, “We believe in the power of conversation.” We invited the entire engineering team and relevant internal stakeholders. We started with a short summary of each incident from each Incident Commander (IC) and any other people who were involved (typically the on-call team, other engineers, and anyone running incident comms).
After that, we launched into discussion, looking for common aspects of the incidents. Drawing on her SRE background, Liz Fong-Jones recommended we categorize incidents using the taxonomy she learned at Google: what fraction of incidents are downstream provider-caused, vs. self change-caused, vs. customer-caused? This taxonomy was immediately helpful: we noted that no issues were customer-caused and two issues were provider-caused: the DNS lookup failures and the dogfooding Kafka problem. Besides having #feelings about Route53, we were generally satisfied with our responses to those incidents: we were able to identify the issue quickly and our on-call engineers were able to remediate them quickly as well. The other three issues were all caused by code changes that we merged and deployed. We started to look for common factors between these three incidents.
What went wrong?
In the past, we’ve had a very low rate of failed deploys. All changes are code-reviewed and approved by another engineer with relevant expertise before merging to the main branch, and we have an extensive automated test suite that covers all our major applications and services. If that fails, our deployment process automatically deploys code to dogfooding environments first, so we have an additional opportunity to run automated checks, receive alerts, and dogfood a new release to confirm it’s working as expected.
So why didn’t that work in this case? A common factor we noted between the problematic code changes was that they were at seams between different layers in the system, often in configuration code. These are the areas that are typically hardest to test with automated testing and are some of the places where our test coverage is lighter. They are also often infrequently changed, requiring long-standing institutional knowledge to assess well in the code review process. We are in the process of onboarding new team members and recently had a long-time bee leave who often worked on our deployment code, infrastructure configuration, and storage engine (miss you, Travis!), so we are noticing some areas where institutional knowledge needs to be supplemented with better tooling or documentation.
Finally, we noted that we’ve outgrown some of the assumptions baked into our deployment process. At a high level, our deployment code hasn’t changed much since 2016. Each time a pull request is merged to the main branch, our CI runs. If the run is green (meaning all tests pass), that run generates a release tarball that we store in S3. Once an hour (staggered slightly by host), a cron job runs on our hosts, grabbing the latest tarball and deploying it as a new release. This deployment system is great in many ways: it’s incredibly simple, it’s 100% automated, and it helps us keep our releases small and frequent. The fact that it is fully automated also encourages engineers to make sure they write thorough instrumentation, alerts, and tests ahead of time to verify that something will work as expected in production, rather than manually testing upon deployment. We stagger the time between deploying to our dogfooding environments and to production, so we typically have about a half an hour where we can catch bad releases by using the dogfooding environments or running automated checks against them.
While this deploy process has worked well for us until now, we are running into growing pains. We’ve doubled the size of our engineering team, and we’ve increased our customer traffic by many orders of magnitude. Our deployment process was built in the days when we took the availability of our web application and querying capabilities (“UI availability”) less seriously than the availability of our event-processing endpoints and pipeline (“API availability”), and so our automated post-deployment health checks focused heavily on testing our API in a realistic way and used less-realistic checks for our querying path. Culturally, we’ve made the right shift — our engineers now take both UI availability and API availability extremely seriously and respond to UI issues with the same promptness and thoughtfulness as API issues — but our tooling hadn’t caught up. Our end-to-end checks and health checks don’t yet do a good job of simulating a realistic read load from customers, and so we don’t yet have a sufficiently robust automated way to detect when real-world querying isn’t working as expected and automate a rollback. We’ve also found that an hour has become an awfully long time between releases — with a fast-moving startup engineering team, many changes can be checked into the main branch in an hour, and finding the commit that went wrong has become a more complicated proposition.
What went well?
Just as it’s worth noting where things went wrong, it’s worth capturing where things went well, and we had some things that went right with these incidents:
- Experienced on-call team: our on-call team and other available engineers were able to detect the issue and restore service relatively quickly in these incidents, typically resolving the issue in 15-60 minutes. (Thanks Martin, and sorry about all those pages!) For an incident requiring a human to diagnose and take steps to remediate, this is on the faster end — we would only expect substantially faster remediation from automated techniques.
- SLOs: our team is relatively new to Service Level Objectives (SLOs), but we are lucky to be learning about them from experienced SRE Liz Fong-Jones. In all our customer-facing incidents, we saw that our SLOs correctly represented the issue and alerted us with relevant burn alerts when customers were feeling pain or seeing issues. Particularly in the case of the Route 53 outage, because such a small percentage of traffic was affected, we noted that traditional alerting techniques that require a dramatic change to trigger an alert might not have caught the issue. The issue happened late at night, so our team also wouldn’t have noticed while going about their regular business or triaging customer reports. The SLO burn alert was the only tool in our toolkit that was able to summon the on-call team and allow us to address the issue quickly, minimizing customer impact.
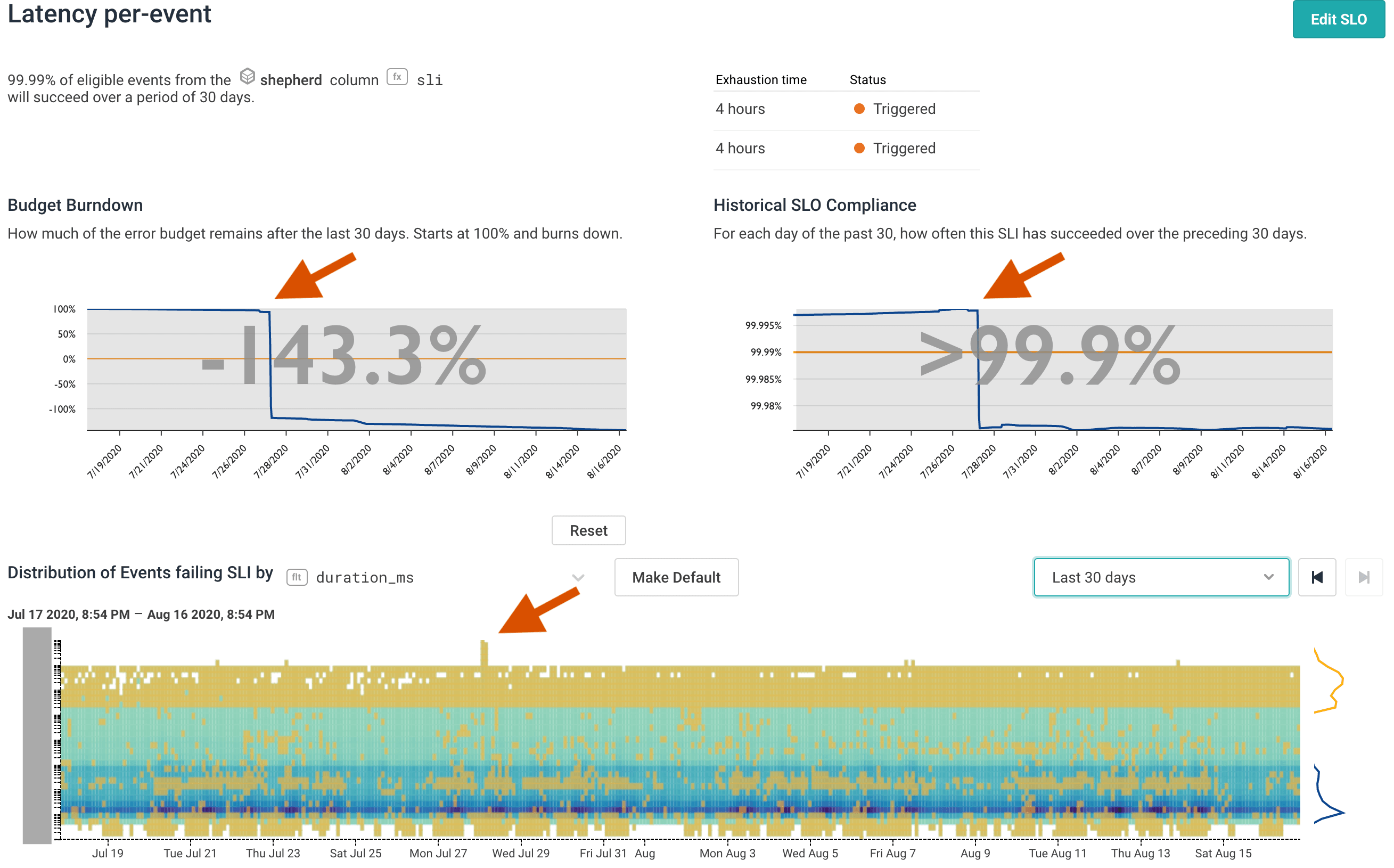
Our SLO for Events API latency shows both that we exhausted our budget in the Route 53 incident, and also that our availability along this axis remains above 99.9%. SLOs are a great tool for alerting about smaller failures that don’t catastrophically affect large portions of traffic but still jeopardize our availability targets.
Next steps
We set ambitious internal availability targets, and these incidents brought our availability numbers below our goals. It’s essential to us that our customers can rely on Honeycomb to be there with the answers they need, at the moment that they need them, and we apologize if that wasn’t the case here. We’ll be making changes to our tooling and processes to prevent similar issues in the future. Here are the most important changes we’re working on:
- Better automated checks. We’ll update our automated post-build checks to better simulate customer traffic, and automatically cancel the deployment or roll back to a prior release when these checks fail.
- Investigate changes to our deployment process. We believe that a faster deploy & rollback cycle and more granular deploys might have allowed us to restore service more quickly, and we’re investigating whether we can update our deployment process to make this possible.
- Additional documentation and training for the team. While this wasn’t a major factor in the incidents we reviewed, we noticed that our institutional knowledge is getting thinner as we grow the team, and we’re due for some additional investments in documentation and training around our infrastructure and deployment processes. We hope that by investing more heavily here now, we’ll help prevent new types of incidents we haven’t yet anticipated in the future.
We’ve planned this work for the second half of our Q3, meaning we’re scheduled to complete this work within the next month and a half. We’ll plan to explore how these changes impact our future practices in upcoming posts as we roll them out.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.