startSpan vs. startActiveSpan
TL;DR: startSpan is easier and measures a duration. Use it if your work won’t create any subspans. startActiveSpan requires that you pass a callback for the work in the span, and then any spans…



Elevate Your Engineering: Mastering Observability 2.0 with OpenTelemetry & Honeycomb
Learn MoreTL;DR: startSpan is easier and measures a duration. Use it if your work won’t create any subspans. startActiveSpan requires that you pass a callback for the work in the span, and then any spans created during that work will be children of this active span.
I’m instrumenting a Node.js app with OpenTelemetry, and adding some custom instrumentation. For this important activity that I’m doing (let’s call it “retrieve number”), I’m creating a custom span. Under that will be spans for checking the cache and spans for HTTP GET if the number is not in the cache.
Either way, I will get a tracer like this:
const opentelemetry = require("@opentelemetry/api");
const tracer = opentelemetry.trace.getTracer("number app")and then use it to get a span. The easiest way is to usestartSpan:
async function retrieveNumber(index) {
const span = tracer.startSpan("retrieve number");
span.setAttribute("app.numbers.index", index);
// activities that also create spans
const result = // and they set the result
span.end();
return result;
}This creates a span. The duration is however long it takes to execute this stuff. But this span has no children. Whatever the current active span is when I create mine will be the parent of my span, and the parent of any concurrent spans created by stuff my function calls.
If you want to child spans, then usestartActiveSpaninstead. For this to work, you have to do all your work inside a callback function that you pass to startActiveSpan. That way, the tracer can execute your work in a context that uses your span as the parent of any created spans.
The code looks like this:
async function retrieveNumber(index,) {
return tracer.startActiveSpan("retrieve number", async span => {
span.setAttribute("app.numbers.index", index);
// activities that also create spans
const result = // and they set the result
span.end();
return result;
});
}Notice that the return value of my work is passed through startActiveSpan. The callback’s return value is returned.
Notice that I still end the span inside the callback.
This time the activities that create spans will get my span as a parent. In Honeycomb, the trace view looks like this:
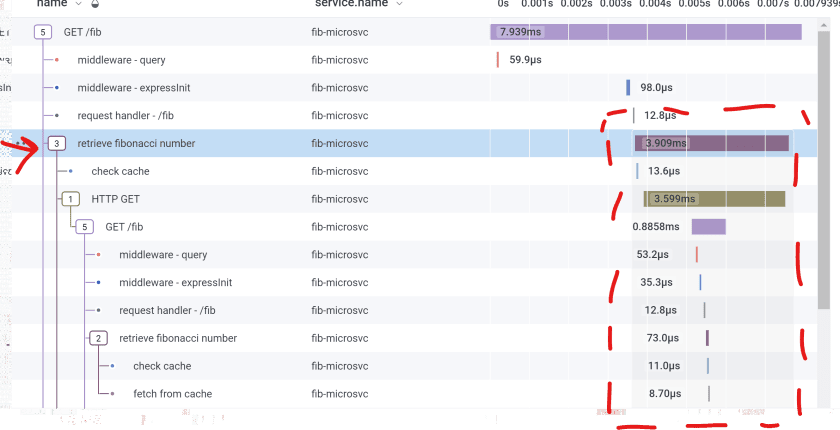
A Honeycomb trace where I used startActiveSpan so my span has children.
Notice that my span (“retrieve fibonacci number” here) creates a level in the hierarchy. Its “3” in a box says it has three children. Over on the right, I’m hovering my mouse over this span in the waterfall, and Honeycomb draws a subtle gray box around all its children.
This clearly says that “check cache” and “HTTP GET” are part of “retrieve fibonacci number.”
For contrast, see what the trace looks like when I usestartSpan:
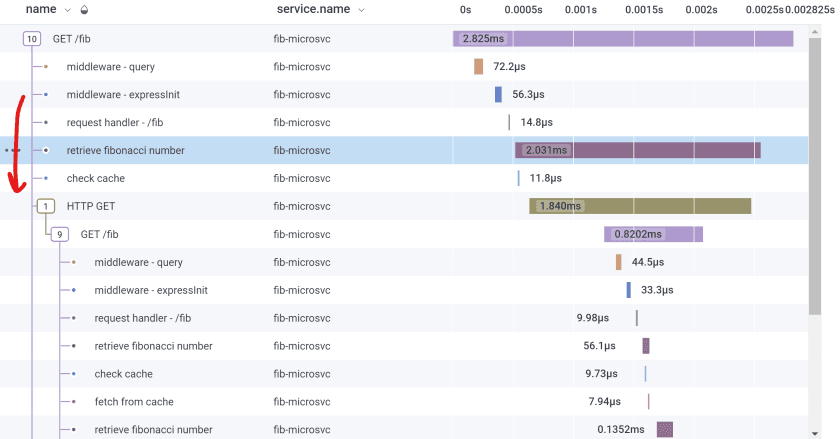
The Honeycomb trace view when I use startSpanso my span has no children, only lots of siblings.
Here, no level in the hierarchy is created. “retrieve fibonacci number” is just another span, a sibling of “check cache” and “HTTP GET.” Their spans overlap in time, is all. But nothing says that “retrieve fibonacci number” caused the “HTTP GET.” Concurrency could be an optimization.
Over on the right, I’m hovering my mouse over its span, but it doesn’t make a difference. There’s no box drawn around its children because it doesn’t have any.
The active span was never changed, so all created spans (including mine) share the same parent (“GET /fib” in this picture).
startActiveSpan is more trouble because you have to pass in a callback, but it’s more expressive because spans created as part of this span’s work are grouped under this span.
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.