
“We can know one thing: shit’s gonna fail.”
Last week we participated in SRECon Americas, held across three days of intensive learning with practitioner talks, hands-on workshops, socializing, and of course vendor booths. Now in its third year, attendees numbered 650 with an additional ~300 from sponsors and organizers.

The USENIX team did a nice job with top notch content because the committee chair and many of the committee members are also SRE practitioners who not only know audience expectations but who have experienced first hand the challenges that come with the job. Committee members volunteer their time and it is much appreciated – our own Developer Advocate Liz Fong-Jones and Mike Rembetsy, Manager of Systems Engineering at Bloomberg opened up the event to a packed room of enthusiastic engineers.
This was my first SRECon and I went to as many sessions as I could; here are my observations:
SRE teams keep businesses humming…or not
During the event, the world experienced a severe outage stemming from Sabre’s central flight reservation system that is relied upon by many domestic airlines including American, JetBlue, and Alaska which prevented passengers from checking in and boarding planes. Avoiding a system outage is a number one concern for every SRE practitioner.
A couple of days later, albeit less impactful, Hubspot experienced an outage that affected all customers, preventing any communication — which was critical during end of quarter timing. This outage impacted Honeycomb’s business, stopping us from communicating about upcoming events, which definitely slowed us down. Even after a few days, performance has been spotty and support’s response time is not up-to-par. Net-net, it’s bad for business and will no doubt impact Hubspot’s upcoming revenue.
System complexity isn’t going away any time soon
The most impressive part of SRECon was the quality of content for attendees dealing with the increasing levels of complexity that come with building and managing production systems. Distributed systems and microservices-based architectures are a given and even though Kubernetes is about four years old, or three from the first stable release, you would think it was mainstream tech at SRECon. This crowd is tech-forward, early adopters, and definitely pushing scale and complexity. A running theme from most presenters was around embracing complexity, facing it head-on to the point of promoting chaos engineering practices to iterate, improve over time, and gain confidence in knowing how to fix things when s*&^ happens.
Monday’s first plenary session presented by Laura Nolan (who recently joined Slack) shared a series of black swan incidents in detail that have taken place over the past several years. Nolan shared key learnings; by her definition, Black Swans are those hard to predict issues, outliers and problems that often cause severe impact. The categorization of these incidents helps teams to recognize patterns, improve predictability, and know how to take action with specific defense strategies and hopefully curtail damage and find quick resolution. Suggested strategies range from better monitoring to load and capacity testing or setting better controls and layering infrastructure with dependencies only on lower layers. In a brief conversation with Laura, she shared that a key part of adhering to the best defensive strategy is communicating clearly with the team on what steps to take when specific incidents occur. Half joking but also half serious, she shared that a good old fashioned step-by-step guide, printed and laminated, often works best.
Key learnings from other industries – even from the Space Shuttle program
The second plenary session from Casey Rosenthal, CEO/Founder of Verica.io (previously SRE at Netflix) shared his wisdom around how to tackle complex systems and that no matter how often you model, test and manage, things still go horribly wrong. Casey likened the role of an SRE today to a situation from a 1986 space expedition where the O-rings in the rocket booster over-heated, ultimately the cause of take-off failure. As it turns out, the NASA team failed to test rings at the lower temperature levels. Rosenthal talked about redundancy, risk avoidance and simplicity as key tenets when managing system complexity. Without the human element, there IS no reliability. Tools alone can’t do it.
Hands-on with SRE colleagues can’t be valued enough
The second day took things a step farther and featured workshop sessions with guided hands-on experiences such as how to set-up a Kubernetes cluster by Liz Frost in addition to “How to design a distributed system in 3 hours” led by multiple presenters from Google covering how to migrate from monolith to microservices, how to build for scale and how to build 3rd party components into your system, starting with understanding the difference between an SLO, SLI, and SLA. Shoulder surfing is the best kind of learning and in such a safe environment as this. Priceless.
Lightning talks ran into the 9pm hour (egads!) and one such talk from Catchpoint shared survey results on stress levels experienced by SRE teams. Findings cite that 49% claim incident response to be a massive part of the job and a further 79% claim it to be stressful. Many feel alone and unsupported by management – in fact only 32% agreed that their company cares about physical and mental wellbeing. This session was presented by Dawn Parzych who is now LaunchDarkly’s developer advocate.
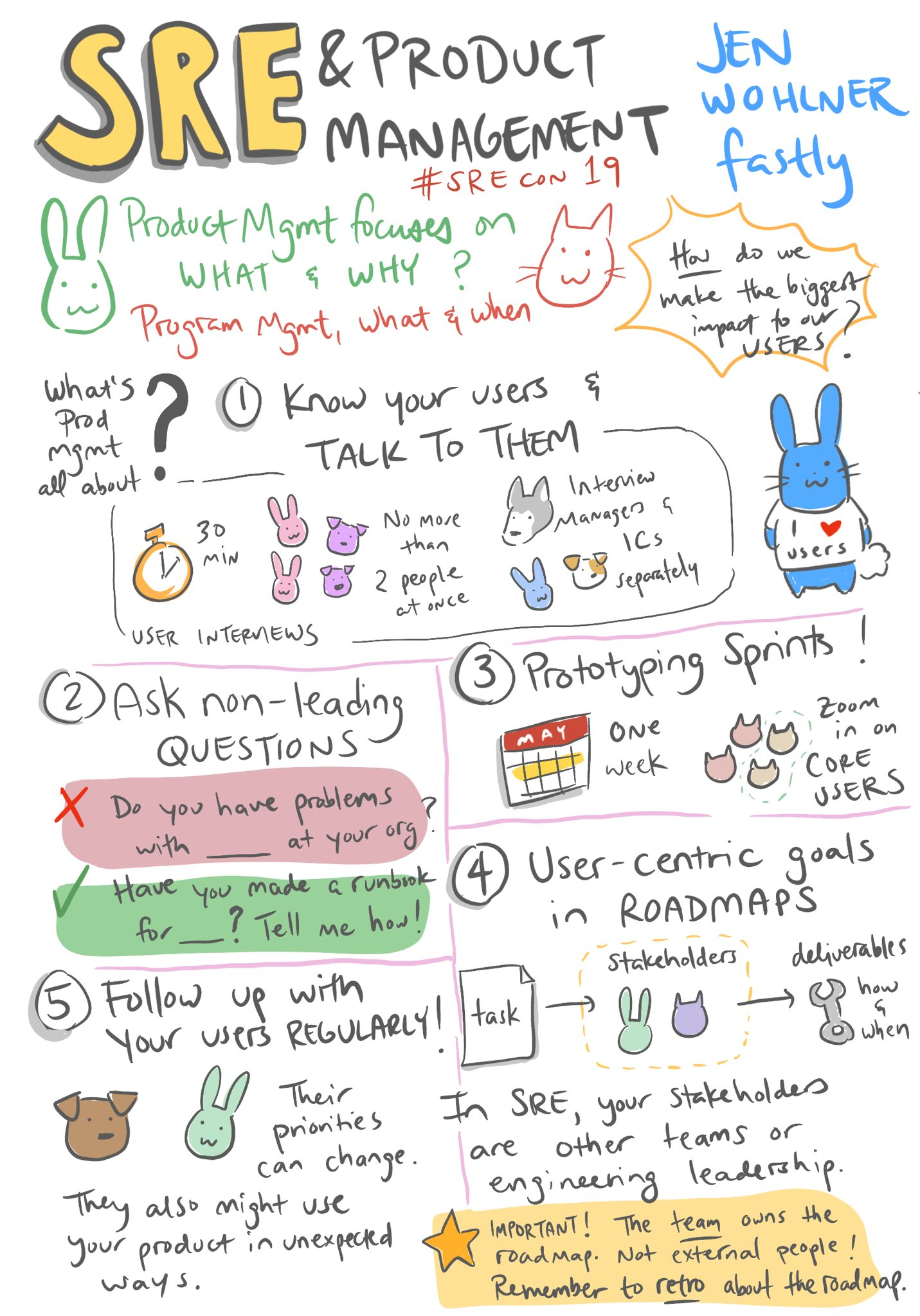
SRE teams not only have to manage SLOs, SLIs, and potentially SLAs but they often intersect with infrastructure teams, architecture roles, and sometimes product owners who collaborate to deliver on ongoing business needs. Fastly’s Jen Wohlner did a session on how SRE’s work with with product management who have a lens on the user experience from a features perspective, whereas SREs focus on performance, availability and errors so that users can have a positive experience in the first place. Denise Yu who is an amazing sketch artist covered Jen’s session in this sketchnote/drawing. It reminds me of a Charity Majors quote: “Nines don’t matter if users aren’t happy”.
Distributed systems… a brief history
On the final afternoon before sessions wrapped up, Denise Yu did one of the closing sessions titled “Why are distributed systems so hard” which was a helluva roller coaster ride covering lots of ground. A speedy historical run-through on why we’ve moved to the cloud and distributed horizontally in order to achieve availability, scalability and of course reduced latency. Of course, the economics make more sense and are very attractive if you’re AWS or Azure. Wu injected humor (plus amazing art) as she shared details around the CAP theorem – consistency, availability, and partition tolerance. It’s not simply a case of optimizing or picking 2. You can’t prevent partitioning unless you only have 1 node and let’s face it, you’re probably not handling scale or complexity.
There was ample time to socialize and the most amazing ice sculpting had to be a Kubernetes certified one. I don’t think the artist attended the K8s workshop but he had mad skills nonetheless 🙂
The burgeoning role of SRE
According to Catchpoint’s survey findings, 64% of respondents say that the role of SRE has been in existence for 3 years or less and that it’s still emerging as a practice. Despite its relative youth, this group at SRECon Americas represents an amazingly supportive community that is open and willing to share learnings and experience, whether good, bad, or ugly. I was so impressed with the open, diverse and friendly community that truly understands we’re all in this complexity together…keeping sites running and keeping businesses operating. Heck… keeping the world online and ticking. Thanks for having me.





