Tale of the Beagle (Or It Doesn’t Scale—Except When It Does)
By Ben Hartshorne | Last modified on August 29, 2023If there’s one thing folks working in internet services love saying, it’s:
Yeah, sure, but that won’t scale.
It’s an easy complaint to make, but in this post, we’ll walk through building a service using an approach that doesn’t scale in order to learn more about the problem. (And in the process, discovering that it actually did scale much longer than one would expect.)
The Beagle’s beginnings
Before I delve into the story in detail, here’s a quick explanation of why this is the “Tale of the Beagle.” At Honeycomb, we love our pups. So internally, our service level objectives (SLO) product is a combination of “Beagle,” which does the stream processing; “Basset,” which does the burn alerts; and “Poodle,” which is our principle UI dog and constructs the main SLO pages. All are served by our storage engine, “Retriever,” which fetches data for presentation.
Our tale begins two years ago, when we started building the Honeycomb Service Level Objectives (SLO) product The description of the core math was relatively straightforward—every event that comes in evaluates to one of three states: true, false, or nil. Every event either participates in the Service Level Indicator (SLI) or it doesn’t (nil is the “not relevant” category), and every event that participates either meets or fails the criteria. These true and false counts are added up and evaluated against your SLO target.
This description (especially the part about “examine every event”) naturally lends itself to an architecture—evaluate every event on the way into Honeycomb and store those counts. Evaluating burn alerts and other visualizations are then created on top of pre-aggregated data. When a person comes along to understand the state of the SLO, they then lean on traditional Honeycomb exploration to understand what’s going on.
There was just one problem—we didn’t have a platform for streaming event analysis already built, and we didn’t want to put additional computational burden on our existing API servers since their job is to process and hand off events as quickly as possible.
What did we have? Our Retriever, a high-performance query engine! Instead of examining each event on the way in, we can look back over the SLO period and ask Basset to run a query every minute, counting events to see how they do and taking appropriate actions.
Yeah, sure, but that won’t scale.
Sure, it won’t scale. Except that it did.
Let’s put that in context! We were embarking on a project to add a large new feature to the Honeycomb product. We didn’t know if it would’ve filled the well-understood need correctly—i.e., we didn’t know if it would be adopted and we didn’t know if it would be successful. Should we build a whole stream processing platform for a complex feature we didn’t yet understand or know whether it would be successful?
At Honeycomb, we believe in combining the smallest working (i.e., minimum viable) product with iterative development and early customer feedback. We built the SLO product by giving Retriever expensive queries and it worked! We got feedback and evolved the product, all while exploring what parts fit and what didn’t. We did make one affordance to the scaling gods early on by caching data once it was a few hours old (read the tale of the accidental $10k here), but other than that, moved on to focus on other parts of the product.
We used the tools we had on hand that worked well enough to give us the freedom to focus on the most difficult part: building the product itself.
Time went by. And continued to go by. And still, our storage engine was serving up results to the people that asked it questions. We still “knew” that this wouldn’t scale—except that it was. Six months went by, then 12. We came out of beta and launched the feature. Post-launch, we continued to grow and got a full year of learning about how our customers were using the SLO product out of this shortcut that “wouldn’t scale”!
Along the way, we got to try out the new Graviton2 processor, and then when it became generally available, we quadrupled the compute capacity of our storage engine for 10% increased cost, buying us even more time. But even gifts of CPU time don’t change the architectural limits—the natural horizontal scaling designed into the system is aimed at a different type of growth. By this point, the vast majority of Retriever’s time computing query results was purely in service of the SLO product and we could see it beginning to creak.
As with so many complex systems approaching their limit, things got worse slowly … and then they got worse quickly.
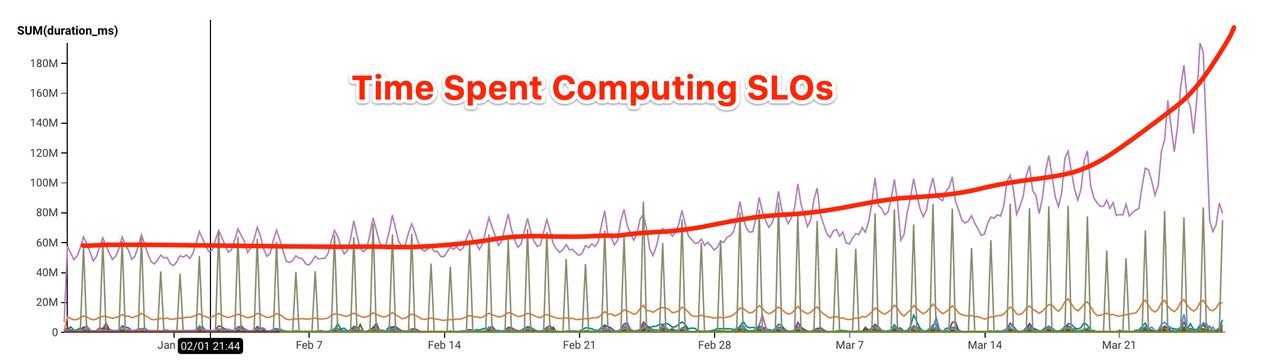
SLOPocalypse was upon us!
Yeah, sure, but that won’t scale.
The echoes of that quote rang in our heads. It was tempting to sit there and think, “Yeah, I wish we had done this differently.”
But ... I don’t. I think we did it just right—we used a tool we had on hand and got over a year’s worth of post-launch production experience out of the deal. It’s perhaps a little less comforting to take that perspective when you’re staring at that curve, wondering if Honeycomb is going to stop working tomorrow as our poor storage engine eats its own internals trying to stay fed, but have faith, all is not doom.
We had a few tricks up our sleeve to handle the load and getting them live was a short effort. The most effective trick cut total SLO load by about two-thirds. We had been computing each SLO independently even when they were on the same dataset. Anybody who’s used Honeycomb is familiar with putting multiple graphs on the same page, and the same concept works for computing multiple service level indicators (SLIs). By computing 10 SLIs simultaneously and a few other short tricks, we bought ourselves about three months of growth time—enough to finally build a more permanent solution.
We took that time and built ourselves Beagle, a stream processor to do SLO calculations. Stream processors are not new, but still there were a bunch of fun things we got to explore along the way: Kafka consumer groups, fun with instrumentation, and some excellent Honeycomb graphs to compare data for correctness (I’d love to say more but each is an entire blog post in itself).
The classic metaphor “replacing the engines while in flight” may be overused, but did feel apt. We were exchanging the lowest level of machinery in the SLO product, the real-time calculations of SLI successes and failures, all while continuing to serve live traffic. We ran both systems in parallel for a while and used Honeycomb to examine the differences. Feature flags let us control whether individual calculations should be on one system or the other, smoothly transitioning in either direction.
The happiest graph of all came at the end.
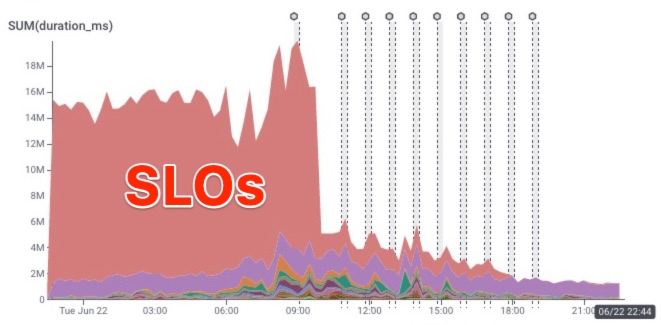
The new streaming service that does SLO calculations is a horizontally scalable cluster that will automatically grow (and shrink) proportionally with the amount of incoming data flowing through our API. So yes, it will scale.
Asking the right question
We’re forced to wonder, though, should we have built it that way from the beginning? Could we have avoided this whole tale by shipping three months later with a system that would grow beyond a year? Maybe that would have been fine? However, I’m not convinced I would have been able to give you an answer if you had asked me a year ago, “What part of the SLO system is going to fail to scale first?” Or if I did give you an answer, it might have been something completely different. Or that I would have been able to predict the effect of Graviton2 on the characteristics of our query engine and how that changed the balance of the whole equation.
Some takeaways: There are times when you know a system will need to scale along a certain axis and you build that in from the beginning. But there are also other paths you can take to get to a user-facing product so that you can find out for sure which parts work and which don’t. This is one tale of getting far more mileage than expected out of a system that worked, letting us learn along the way, then rebuilding the part that needed it when the time came.
Yeah, sure, but that doesn’t scale.”
Maybe it does, maybe it doesn’t. In most cases, that’s the wrong question. Instead of asking whether it will scale, ask instead whether it will get you to the next phase of the product and the company's existence. With that slight change in mindset, you are one step closer to the ideal of continuous iterative development, building what you need when you need it, and shortening the path to a successful feature.
Interested in learning more? Check out this webinar with ecobee to see how SLOs can help create more happy user experiences. Or sign up for a free Honeycomb account today.
Related Posts
How We Leveraged the Honeycomb Network Agent for Kubernetes to Remediate Our IMDS Security Finding
Picture this: It’s 2 p.m. and you’re sipping on coffee, happily chugging away at your daily routine work. The security team shoots you a message...
Driving Exceptional Support: Unleashing Support Power with Honeycomb
n technical support, ensuring customer satisfaction and quickly resolving issues are of utmost importance. At Honeycomb, we embrace a comprehensive approach by using our own...
How Our Love of Dogfooding Led to a Full-Scale Kubernetes Migration
When considering a migration to Kubernetes, as with any major tech upgrade or change, it’s imperative to understand the motivation for doing so. The engineering...