Getting Started With Distributed Tracing
Getting Started With Distributed Tracing
Getting Started With Distributed Tracing
Table of contents
The more complex the software, the more likely it is to break, so the question facing modern DevOps teams today is how to quickly and easily locate misbehaving or poorly performing components amid thousands of moving parts. The old methods of troubleshooting (looking at logs and metrics) are cumbersome, time-consuming, and often lack the context to tell a complete story. Teams working in complex and distributed systems need a better way to understand them, and it starts with observability tools that leverage the power of distributed tracing. Done right, distributed tracing provides a speedy diagnostic process that empowers teams to proactively find and fix bugs, even before they impact customers.
What is distributed tracing?
At its core, distributed tracing is a way teams can view exactly what is going on with every application request using a series of IDs/tags and timestamps to visually represent when requests begin and end, and the relationships between them. Because the tracing is “distributed,” it is an ideal observability solution for organizations using microservices, or wherever an application is broken into independent components and widely dispersed. However, even traditional legacy applications can benefit from distributed tracing. In fact, distributed tracing is a modern observability solution for anywhere developers and operations need a clear view of how code is performing—with an eye to fixing problems quickly.
The benefits of distributed tracing are many. Distributed tracing can help teams with:
- Faster debugging because you can see what is actually happening as requests traverse application components.
- Better development of new code because teams can see how the systems connect and where the dependencies and vulnerabilities are.
- Democratizing system knowledge as without distributed tracing, teams rely on the most seasoned engineers for knowledge of how components fit together.
In 2010, Google told the world about its experiment with distributed tracing in what is now known as the Dapper paper. Since that time, a number of other open source efforts around distributed tracing have launched, including OpenZipkin and Jaeger. Distributed tracing has grown dramatically in popularity since then, and today’s modern solutions are far more efficient, with standards like OpenTelemetry and tools like Honeycomb ingesting your trace data and giving you the tools to find the right trace for any given issue.
In general, distributed tracing systems require the following components to be added so the code is traceable:
- A trace ID: a name that is tied to an application request.
- A span ID: a “span” is work that happens during a trace, and each span needs a unique name.
- Parent or child IDs: these make the nested relationships between spans in the trace clear, as in a child span would nest under a parent span, etc.
- Timestamps/duration: each span needs a timestamp and a way to track how long the event took place.
How does distributed tracing compare to metrics and logs?
To underscore the value of distributed tracing, it can be instructive to look at how issues have been identified and diagnosed in the past, and where existing approaches have provided diminishing returns. Traditionally, metrics were used to benchmark performance trends and formed the basis of early monitoring solutions. Logs, conversely, have been a valuable resource for granular diagnosis of any uncovered problems.
The problem with logs and metrics in modern, massively distributed applications is that they represent two extremes, each with unique challenges at scale. Metrics are at best indirect and aggregated data points which provide information that is either too generalized to isolate the source of a problem, or too late to address customer issues. While logs can make up for this with detailed, tunable diagnostic data, even finding the right log to look at can be a difficult task in modern applications. It can be cost-inefficient to scale logging’s hefty storage requirements.
System metrics are indirect, trailing indicators of health
When monolithic applications ruled the datacenter, system metrics were a decent approximation of health. If your memory’s spiking, you get a page, you restart a service, and that service is promptly restored. The thing is, these solutions were often so straightforward that we soon had access to the means to address them programmatically. Process monitors, service managers, and configuration management all evolved to make sure that simple resource allocation problems could be addressed without human intervention.
Is it still important to monitor memory, disk, CPU, et al? Of course. In modern cloud configurations, for example, system metrics are often used as an input to determine when to automatically scale resources. And it’s still crucial to alert when thresholds are passed, but now those alerts are more defense-in-depth than they are early warnings. An out of memory page means something is seriously wrong, because all of the mundane, automated fixes have already failed.
Application metrics are as useful as your problems are predictable
Application metrics evolved to address the indirectness outlined above. While applications are endlessly varied in how they function, the frameworks and languages they’re built upon are much more finite concerns. Thus, framework by framework plugins, modules, and agents were developed to capture some universally useful metrics. How long did a request take to resolve? How many threads is a particular application process using? These became more relevant indicators of health due to their increased specificity to the code being executed.
While their impact cannot be denied, the problems that have developed with application metrics as patterns have evolved are multifaceted.
The first problem is simple vendor lock-in. The class of tools designed to collect these metrics, Application Performance Monitoring (APM), each launched with their own proprietary agents for capturing metrics with varying capabilities and implementation methods. This made it difficult to comparison-shop or change tooling once an initial APM solution was selected.
The second problem is that metrics have diminishing returns at scale. As a customer base grows, aggregated metrics can make it difficult to see emerging issues that only affect a small subset of an app’s users, making them increasingly trailing metrics, as with system metrics before them. Additionally, as applications themselves become more distributed, metrics like “request duration” are still useful in determining that a problem exists, but provide little insight into where that problem exists.
Finally, and perhaps most importantly, the more distributed an application is, the less predictable its failure modes become. With complexity comes a corresponding explosion in the number of possible combinations and permutations of interactions between an application’s constituent services. In turn, outside of high-level aggregates, even knowing which metrics are actually important to capture might not be possible until after an incident. By their finite and pre-defined nature, out-of-the-box metrics can only account for an ever shrinking subset of health indicators, and custom metrics become an increasing necessity and potential cost vector.
Logs are too verbose for humans and too inconsistent for machines
There’s no substitute for a detailed log when it comes to identifying exactly what’s happening under the hood of an application. The problem at scale isn’t that the answer doesn’t lie in the logs somewhere, it’s that finding the relevant signal in an ever increasing sea of noise is increasingly difficult. What’s worse, logs can become very expensive to store, and cost-saving changes to verbosity, retention, or sampling can undermine the depth that is logs’ core strength.
This is compounded as apps become massively distributed, since logs represent a single service’s point of view, and cannot describe an end-to-end user journey. What’s more, most logs are unstructured logs, which do not necessarily follow any consistent formatting conventions from framework to framework. As a result, it can be difficult to correlate even directly comparable data without first translating the unique structure of each source.
Distributed traces provide the best of both worlds
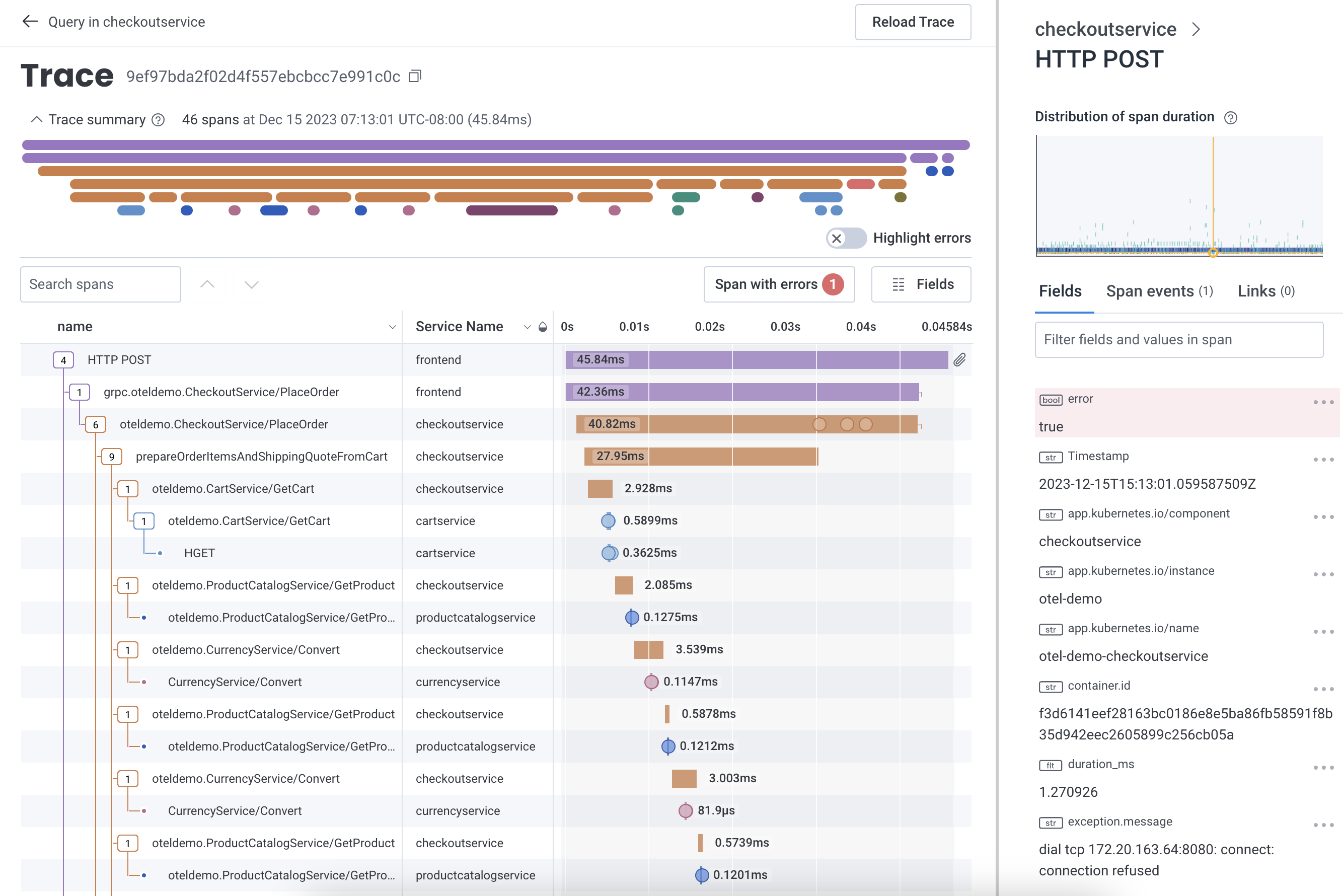
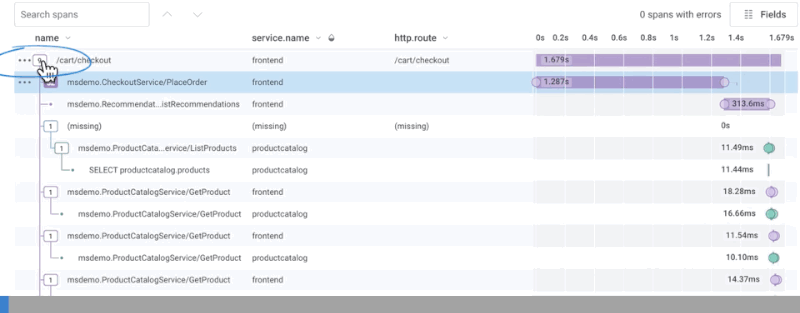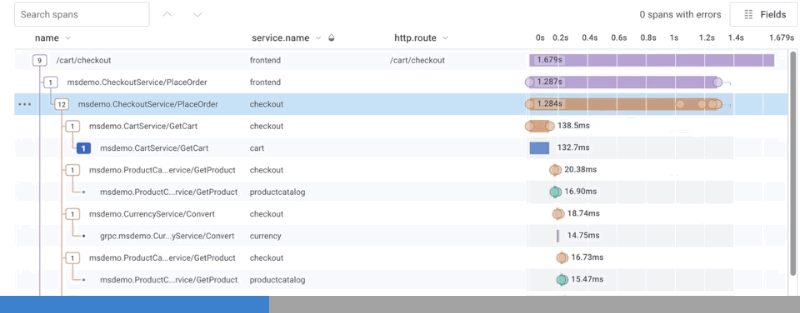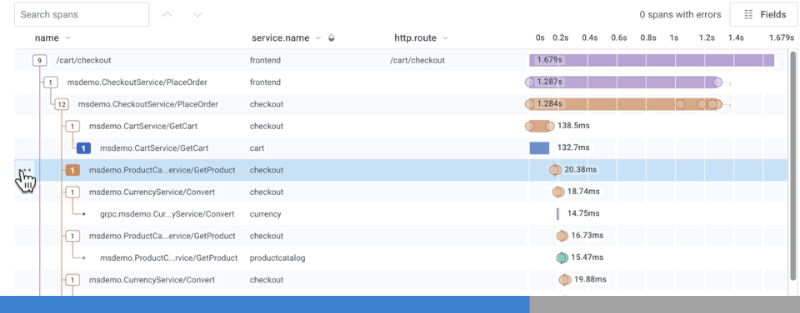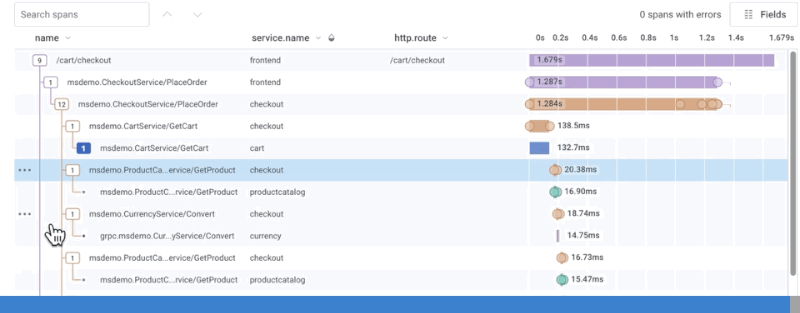
Distributed traces are designed to address all of the challenges outlined thus far. Each service can be instrumented with awareness of its upstream parent, resulting in a visually legible waterfall diagram of the end-to-end details for a single request. Each trace is composed of spans which describe each individual event along the way. Each span, in turn, is augmented with as much metadata as possible for use in later diagnosis. These “dimensions” can be used to capture important configuration parameters that would normally be confined to logs, and crucial performance data that would normally be provided by metrics. But, unlike either of those solutions, traces provide additional context to track and correlate that data from one service to another.
Instrumentation is finally approachable
Even as tracing gained popularity, there remained an elephant in the room: initial solutions were still proprietary and required a ton of upfront effort to implement. Thankfully, in recent years, the OpenTelemetry (OTel) project has matured into a way to address both of these issues.
By providing an open standard backed by the Cloud Native Computing Foundation (CNCF), OTel was embraced by APM and observability vendors alike as a way to standardize tracing configs. This results in a significant reduction in vendor lock-in, and makes implementing OTel a safer long-term investment.
A growing stable of language, format, and framework support have similarly made the cost of that initial implementation much easier to bear by combining a solid foundation of auto-instrumented telemetry with custom instrumentation tailored to the needs of each individual app and team. This allows teams to reap benefits immediately while iteratively improving and refining the telemetry they collect over time.
Observability for literally everyone
No performance issue was ever made better in a silo, which is why distributed tracing offers truly distributed performance data. Teams across an organization have access to the same query results, streamlining debugging and creating a common ground for discussion, investigation and more.
Empowered developers
And finally, happy devs make for a happier development environment, and by drastically reducing the time and energy needed to be spent on debugging, distributed tracing adds to developer job satisfaction. Developers generally prefer less context-switching, and by eliminating the need to dig through logs and compare metrics, distributed tracing systems help support devs to do what they do best.
Where does traditional monitoring fall short?
If there’s a problem with an application, DevOps teams need to know what it is, and that’s where application performance monitoring (APM) metrics come in. APM data can clearly show the “what” but can’t go deeper into the application to show the “why,” which is critical for fast and successful debugging. Distributed tracing is the detailed dive into all of an application’s requests, showing the journey and where conflicts arose. There can be 100 reasons—or more—why an application’s latency is too high, but only distributed tracing can help developers quickly see which part of the app is struggling.
To put it another way, traditional monitoring tells you that there is a problem but not where and why that problem is occurring, and without that insight, debugging and problem resolution is too time consuming for the DevOps team and the end user.
The compounding challenge of instrumenting distributed systems
As our applications have become more distributed, selecting and implementing instrumentation has become more challenging—and not only due to the complexity of the applications themselves. Managing more services means more applications to instrument, and existing tooling is often proprietary and specific to a particular vendor or platform. What happens when a service is written in a language not fully supported by your platform of choice? Or if acquisitions leave your organization with codebases instrumented to send data to different vendors?
Often, the cost of evaluating or migrating a new solution or consolidating on an existing one is high enough that organizations simply make do with underperforming solutions.
Here again, open source solutions like OpenTelemetry provide a means to address this issue. By providing a vendor-neutral mechanism for instrumenting heterogeneous, massively distributed applications, organizations can instrument their applications once and ship their telemetry data to the platform(s) of their choice without needing to re-instrument each time they switch.
Distributed tracing best practices
Here’s how DevOps teams should set themselves up for success with distributed tracing.
Start with why
Although nearly every software development practice can benefit from distributed tracing, organizations with particular needs will see an immediate benefit. DevOps teams using microservices architectures are obvious candidates for distributed tracing, but that’s not the only factor. Companies with extremely complicated monolithic code can benefit, as can distributed teams trying to improve the speed and quality of debugging.
But it doesn’t stop there. Does your application generate high-cardinality data, meaning there are attributes that can have many possible values? High-cardinality data is hands down the most useful information to have when debugging, and the best tool to tackle that detailed data is distributed tracing.
And, at the risk of sounding simplistic, teams that don’t know what they’re looking for when debugging would clearly benefit from distributed tracing.
Choose OpenTelemetry
The advantages of open source technology solutions are well-known, and that’s equally true when it comes to distributed tracing. Jumpstart the tracing process using OpenTelemetry API libraries and choose tools that will support it.
Set up for success
Establishing distributed tracing as part of the software development process means keeping track of lots of moving parts. To ensure teams aren’t missing anything, cover the basics, including:
- Everything must be end to end.
- Implement SLOs based on acceptable latency thresholds in your most important traces.
- Set up a system that will track feedback on response, error, and duration metrics.
- Put a serious focus on duration (because that’s a way to judge how effective the distributed tracing process is).
- If custom tracing spans or business metrics are created, it’s important to have a way to report the data.
Why modern DevOps teams need distributed tracing
Software is the lifeblood of most businesses today and the need to get safe, stable code out the door quickly is a primary goal. But applications are increasingly complicated and distributed, and end users are getting more demanding and impatient. This creates both pressure and an enormous dilemma for development teams: how to continue to create innovative software while at the same time releasing more and more quickly while keeping the needs of finicky end users in mind? Distributed tracing, as part of a modern DevOps practice, will bring results to busy development teams by relieving the burden of both finding and understanding code conflicts and breaks.
With distributed tracing, teams can leverage open source libraries to jump start instrumentation, lessen dependence on logs (and the time spent pouring through them), and slash time spent debugging. Reducing MTTR is an enormous benefit, of course, but there are many others—including faster release times, happier developers, and improved customer satisfaction.
How Honeycomb does distributed tracing
Typically, vendors treat traces as a discrete complement to logs and metrics. Honeycomb’s approach is fundamentally different: wide events make it possible to rely on traces as your only debugging tool, consolidating logs and metrics use cases into one workflow. And unlike metrics, tracing in Honeycomb models how your users are actually interacting with your system, surfacing up relevant events by comparing across all columns. But since a picture is worth a thousands words, see for yourself: