Ask Miss O11y: Long-Running Requests
Dear Miss O11y, How do I think about instrumenting and setting service-level objectives (SLOs) on streaming RPC workloads with long-lived connections? We won’t necessarily have a “success” metric per stream to make a percentage…

By: Liz Fong-Jones

Dear Miss O11y,
How do I think about instrumenting and setting service-level objectives (SLOs) on streaming RPC workloads with long-lived connections? We won’t necessarily have a “success” metric per stream to make a percentage with and a very successful stream could last for days before finishing. What about if the workload contains many individual messages that can independently succeed or fail? How can I adopt observability and SLOs to continuous workloads?
– Stuck on Streams (Nick Herring and Jake Demarest-Mays)
Dear Stuck,
You need not fear a long-lived streaming workload. A few simple tricks can transform a request that may not ever terminate for hours or days into something you can get regular health and status updates on. We in fact have one of those continuous processing services—Beagle, our Service Level Objective stream processor—which we’ve instrumented in this fashion.
Beagle’s instrumentation consists of one root span per stream started per minute (“tick”) with a span duration of 60 seconds. Any outbound requests that start during that window are parented to the tick root span. And when the tick’s duration ends, it also rolls up the number of successful vs. failed writes in total, the amount by which it’s delayed vs. the latest Kafka offset, and so forth into attributes on its root span. One tick is generated per stream per minute, so we’re always able to follow the behavior of each stream of data across multiple minutes by aggregating by the stream ID.
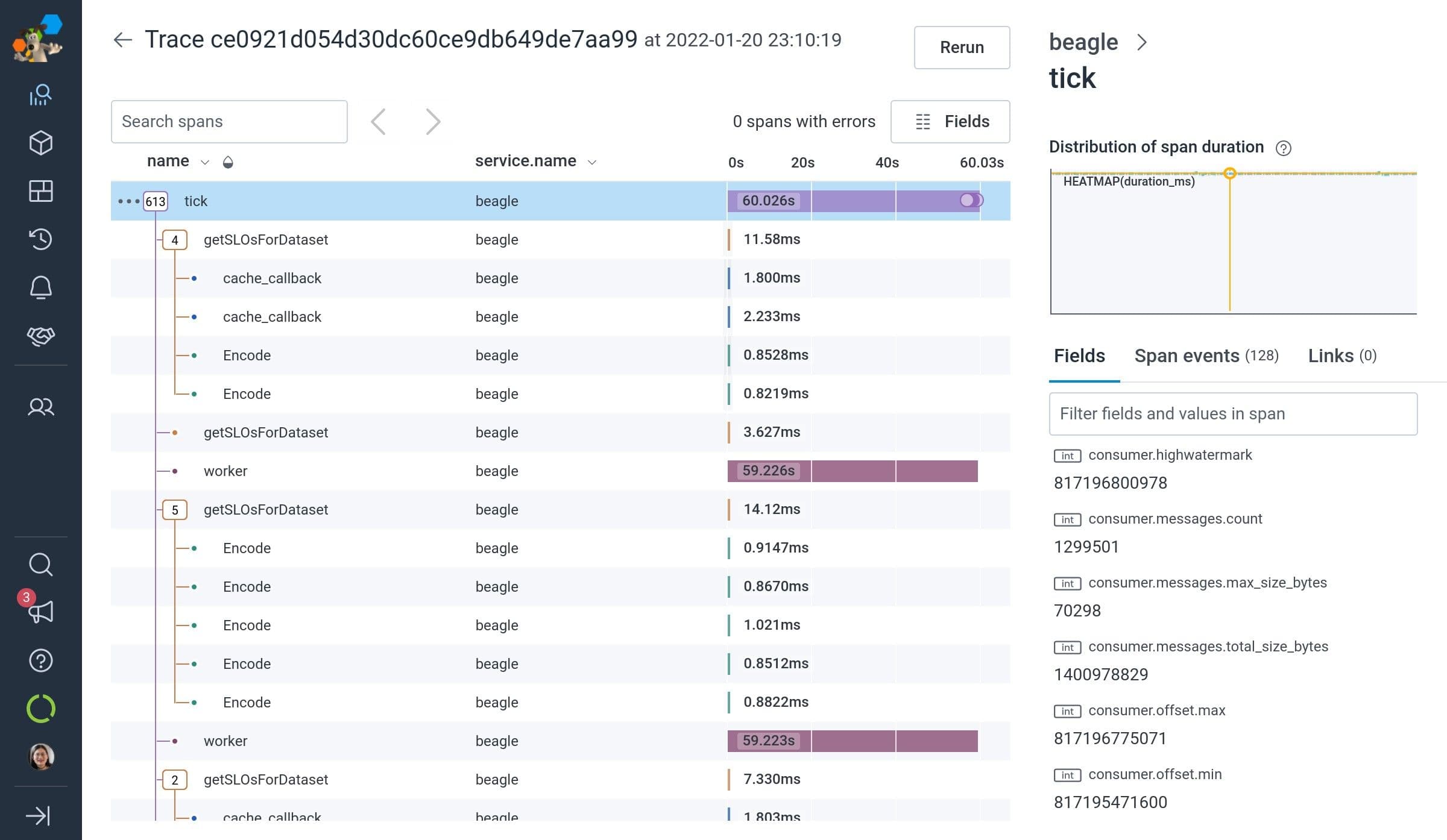
In that fashion, we are able to get periodic minute-long, metric-like data from the root span, along with data from functional traces that don’t sprawl across hours or days accumulating tens of thousands of spans, as well as lower-level data that can be used to feed our own SLOs (it’s Beagles all the way down!).
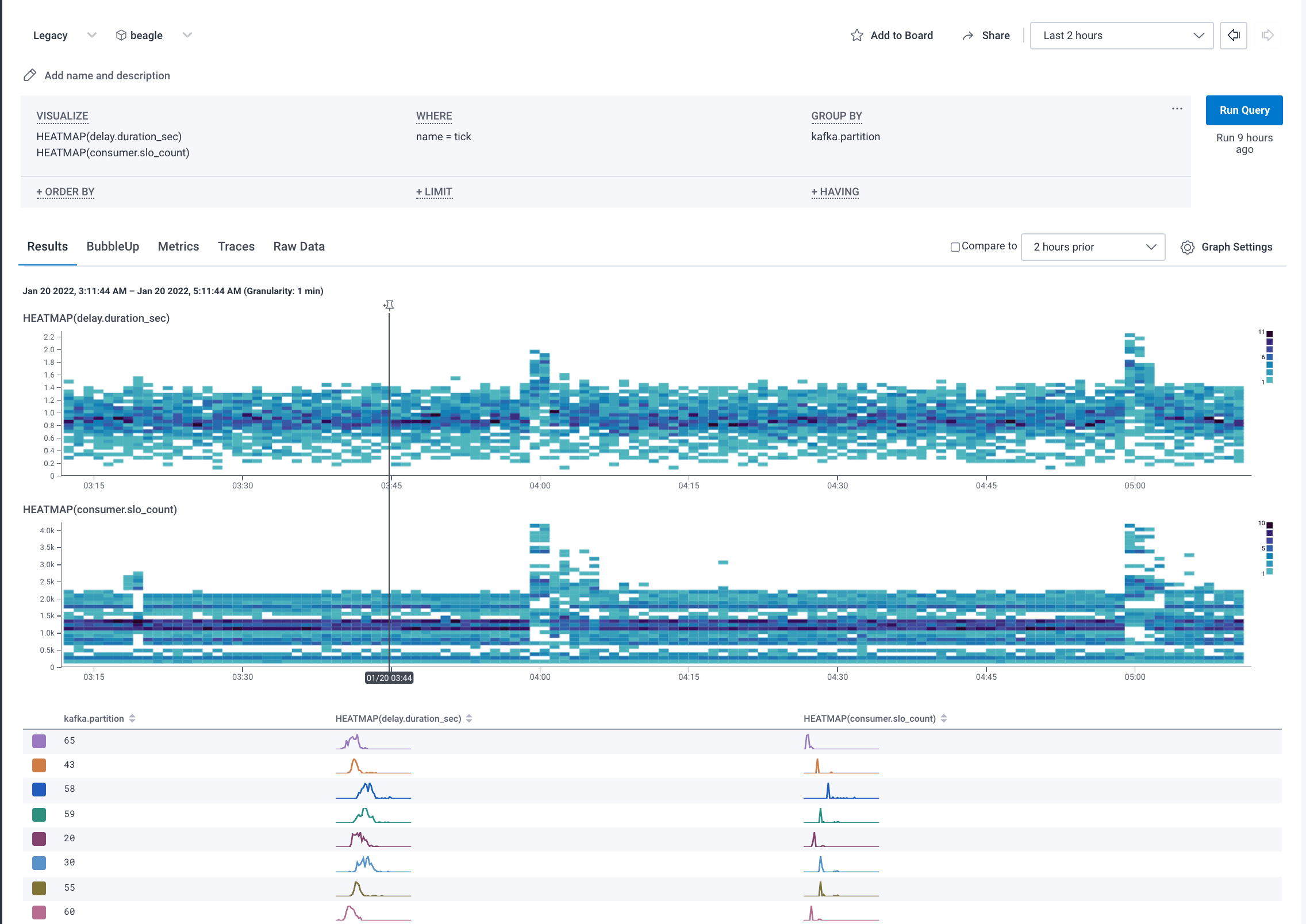
So my advice to you is to set a maximum duration before you roll over and start a new span, have a connection/stream ID to tie the data together, hybridize your root span into being a metrics rollup, and then parent any work that is initiated during that time window to the currently active tick span. You can then set SLOs on the number of succeeding/failing connections in each minute, or even down to the per-sub-request level success, without having to wait for the stream to finish to report its status.
Hope that helps!
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.