Deploys Are the ✨WRONG✨ Way to Change User Experience
I’m no stranger to ranting about deploys. But there’s one thing I haven’t sufficiently ranted about yet, which is this: Deploying software is a terrible, horrible, no good, very bad way to go about…

By: Charity Majors
I’m no stranger to ranting about deploys. But there’s one thing I haven’t sufficiently ranted about yet, which is this: Deploying software is a terrible, horrible, no good, very bad way to go about the process of changing user-facing code.
It sucks even if you have excellent, fast, fully automated deploys (which most of you do not). Relying on deploys to change user experience is a problem because it fundamentally confuses and scrambles up two very different actions: Deploys and releases.
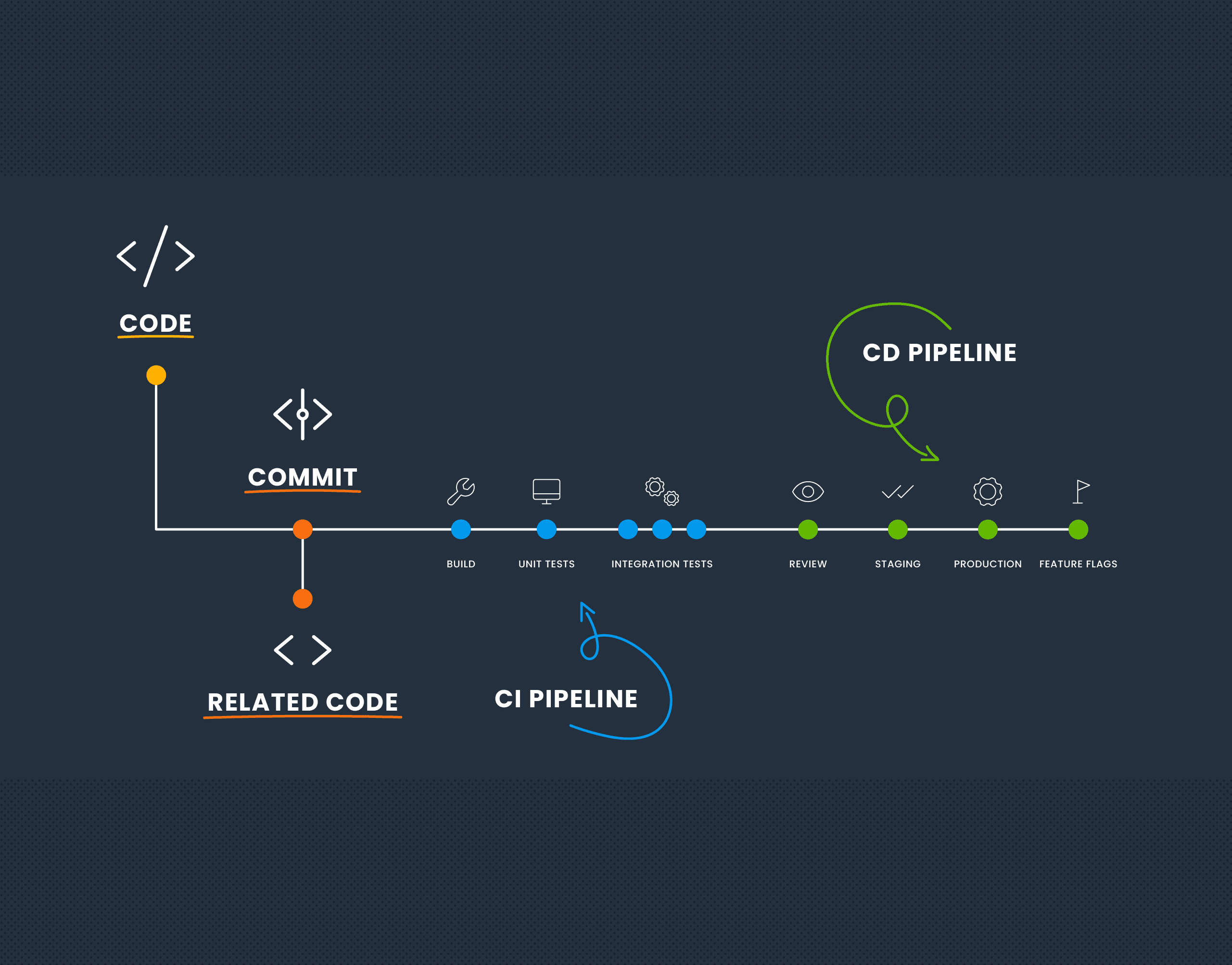
Deploy
“Deploying” refers to the process of building, testing, and rolling out changes to your production software. Deploying should happen very often, ideally several times a day. Perhaps even triggered every time an engineer lands a change.
Everything we know about building and changing software safely points to the fact that speed is safety and smaller changes make for safer deploys. Every deploy should apply a small diff to your software, and deploys should generally be invisible to users (other than minor bug fixes).
Release
“Releasing” refers to the process of changing user experience in a meaningful way. This might mean anything from adding functionality to adding entire product lines. Most orgs have some concept of above or below the fold where this matters. For example, bug fixes and small requests can ship continuously, but larger changes call for a more involved process that could mean anything from release notes to coordinating a major press release.
A tale of cascading failures
Have you ever experienced anything like this?
Your company has been working on a major new piece of functionality for six months now. You have tested it extensively in staging and dev environments, even running load tests to simulate production. You have a marketing site ready to go live, and embargoed articles on TechCrunch and The New Stack that will be published at 10:00 a.m. PST. All you need to do now is time your deploy so the new product goes live at the same time.
It takes about three hours to do a full build, test, and deploy of your entire system. You’ve deployed as much as possible in advance, and you’ve already built and tested the artifacts, so all you have to do is a streamlined subset of the deploy process in the morning. You’ve gotten it down to just about an hour. You are paranoid, so you decide to start an hour early. So you kick off the deploy script at 8:00 a.m. PST… and sit there biting your nails, waiting for it to finish.
SHIT! 20 minutes through the deploy, there’s a random flaky SSH timeout that causes the whole thing to cancel and roll back. You realize that by running a non-standard subset of the deploy process, some of your error handling got bypassed. You frantically fix it and restart the whole process.
Your software finishes deploying at 9:30 a.m., 30 minutes before the embargoed articles go live. Visitors to your website might be confused in the meantime, but better to finish early than to finish late, right? 😬
Except… as 10:00 a.m. rolls around, and new users excitedly begin hitting your new service, you suddenly find that a path got mistyped, and many requests are returning 500. You hurriedly merge a fix and begin the whole 3-hour long build/test/deploy process from scratch. How embarrassing! 🙈
Deploys are a terrible way to change user experience
The build/release/deploy process generally has a lot of safeguards and checks baked in to make sure it completes correctly. But as a result…
- It’s slow
- It’s often flaky
- It’s unreliable
- It’s staggered
- The process itself is untestable
- It can be nearly impossible to time it right
- It’s very all or nothing—the norm is to roll back completely upon any error
- Fixing a single character mistake takes the same amount of time as doubling the feature set!
Changing user-visible behaviors and feature sets using the deploy process is a great way to get egg on your face. Because the process is built for distributing large code distributions or artifacts; user experience gets changed only as a side effect.
So how should you change user experience?
By using feature flags.
Feature flags: the solution to many of life’s software’s problems
You should deploy your code continuously throughout the day or week. But you should wrap any large, user-visible behavior changes behind a feature flag, so you can release that code by flipping a flag.
This enables you to develop safely without worrying about what your users see. It also means that turning a feature on and off no longer requires a diff, a code review, or a deploy. Changing user experience is no longer an engineering task at all.
Deploys are an engineering task, but releases can be done by product managers—even marketing teams. Instead of trying to calculate when to begin deploying by working backwards from 10:00 a.m., you simply flip the switch at 10:00 a.m.
Testing in production, progressive delivery
The benefits of decoupling deploys and releases extend far beyond timely launches. Feature flags are a critical tool for apostles of testing in production (spoiler alert: everybody tests in production, whether they admit it or not; good teams are aware of this and build tools to do it safely). You can use feature flags to do things like:
- Enable the code for internal users only
- Show it to a defined subset of alpha testers, or a randomized few
- Slowly ramp up the percentage of users who see the new code gradually. This is super helpful when you aren’t sure how much load it will place on a backend component
- Build a new feature, but only turning it on for a couple “early access” customers who are willing to deal with bugs
- Make a perf improvement that should be bulletproof logically (and invisible to the end user), but safely. Roll it out flagged off, and do progressive delivery starting with users/customers/segments that are low risk if something’s fucked up
- Doing something timezone-related in a batch process, and testing it out on New Zealand (small audience, timezone far away from your engineers in PST) first
Allowing beta testing, early adoption, etc. is a terrific way to prove out concepts, involve development partners, and have some customers feel special and extra engaged. And feature flags are a veritable Swiss Army Knife for practicing progressive delivery.
It becomes a downright superpower when combined with an observability tool (a real one that supports high cardinality, etc.), because you can:
- Break down and group by flag name plus build id, user id, app id, etc.
- Compare performance, behavior, or return code between identical requests with different flags enabled
- For example, “requests to /export with flag “USE_CACHING” enabled are 3x slower than requests to /export without that flag, and 10% of them now return ‘402’”
It’s hard to emphasize enough just how powerful it is when you have the ability to break down by build ID and feature flag value and see exactly what the difference is between requests where a given flag is enabled vs. requests where it is not.
It’s very challenging to test in production safely without feature flags; the possibilities for doing so with them are endless. Feature flags are a scalpel, where deploys are a chainsaw. Both complement each other, and both have their place.
“But what about long-lived feature branches?”
Long-lived branches are the traditional way that teams develop features, and do so without deploying or releasing code to users. This is a familiar workflow to most developers.
But there is much to be said for continuously deploying code to production, even if you aren’t exposing new surface area to the world. There are lots of subterranean dependencies and interactions that you can test and validate all along.
There’s also something very psychologically different between working with branches. As one of our engineering directors, Jess Mink, says:
There’s something very different, stress and motivation-wise. It’s either, ‘my code is in a branch, or staging env. We’re releasing, I really hope it works, I’ll be up and watching the graphs and ready to respond,’ or ‘oh look! A development customer started using my code. This is so cool! Now we know what to fix, and oh look at the observability. I’ll fix that latency issue now and by the time we scale it up to everyone it’s a super quiet deploy.’
Which brings me to another related point. I know I just said that you should use feature flags for shipping user-facing stuff, but being able to fix things quickly makes you much more willing to ship smaller user-facing fixes. As our designer, Sarah Voegeli, said:
With frequent deploys, we feel a lot better about shipping user-facing changes via deploy (without necessarily needing a feature flag), because we know we can fix small issues and bugs easily in the next one. We’re much more willing to push something out with a deploy if we know we can fix it an hour or two later if there’s an issue.
Everything gets faster, which instills more confidence, which means everything gets faster. It’s an accelerating feedback loop at the heart of your sociotechnical system.
“Great idea, but this sounds like a huge project. Maybe next year.”
I think some people have the idea that this has to be a huge, heavyweight project that involves signing up for a SaaS, forking over a small fortune, and changing everything about the way they build software. While you can do that—and we’re big fans/users of LaunchDarkly in particular—you don’t have to, and you certainly don’t have to start there.
As Mike Terhar from our customer success team says, “When I build them in my own apps, it’s usually just something in a ‘configuration’ database table. You can make a config that can enable/disable, or set a scope by team, user, region, etc.”
You don’t have to get super fancy to decouple deploys from releases. You can start small. Eliminate some pain today.
In conclusion
Decoupling your deploys and releases frees your engineering teams to ship small changes continuously, instead of sitting on branches for a dangerous length of time. It empowers other teams to own their own roadmaps and move at their own pace. It is better, faster, safer, and more reliable than trying to use deploys to manage user-facing changes.
If you don’t have feature flags, you should embrace them. Do it today! 🌈
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.