This is the third of three posts focusing on the limitations of pre-aggregated metrics. The first one explained how, by pre-aggregating, you’re tightly constrained when trying to explore data or debug problems; the second one discussed how implementation and storage constraints further limit what you can do with rollups and time series.
Finally, we arrive at discussing “metrics.” Terminology in the data and monitoring space is incredibly overloaded, so for our purposes, “metrics” means: a single measurement, used to track and assess something over a period of time.
While simple to reason about (“this number is the overall error rate for my API”), the problem with metrics is just that—they’re individual, they’re isolated, they’re standalone dots in the big picture of your system. And looking at the progress of standalone datapoints over time means that, while you can get a sketch of reality over that time, you’re never really able to reconstruct reality to identify what really happened. (See Part 1: asking new questions)
This part-3-of-3 problem is the most subtle to explain of the bunch, so let’s work with some of our trusty examples. Using our datastore example from Part 1, let’s imagine that we’re tracking metrics across two main axes, the operation type (e.g. reads, increments, updates, etc) and namespace (this example will use “libdata”, “libmeta”, and “alltxns”):
statsd.timing(`db.op.${operation_type}.latency`)
statsd.timing(`db.ns.${namespace}.latency`)
statsd.timing(`db.op.${operation_type}.ns.${namespace}.latency`)`
(Note that statsd.timing captures percentiles, average (mean), stddev, sum, and lower/upper bounds for us.)
Well, but what if there’s some third attribute that really makes our datastore fall over? We could have just known ahead of time to store something like (db.op.${operation_type}.ns.${namespace}.q.${normalized_query}.latency)… but we already know from Part 1 that it’s a pain to have to anticipate problems ahead of time and manage all those separate metrics, and we know from Part 2 that there are practical limits to how many cross products we should store.
But real-life systems often do have lots of different things going on! Some attributes are highly likely to be worth partitioning by (e.g. hostname), while others might seem less immediately useful but are readily available and might come in handy someday (e.g. AWS instance type, availability zone, build version).
So—instead of carefully pruning which metrics to track and wasting time evaluating how important certain cross products are, sometimes it’s just easier to track a handful of available attributes, then just peek at a few representative events to see the relationships laid plain for us.
In other words, rather than having to look at a bunch of disparate graphs and try to line up anomalies:
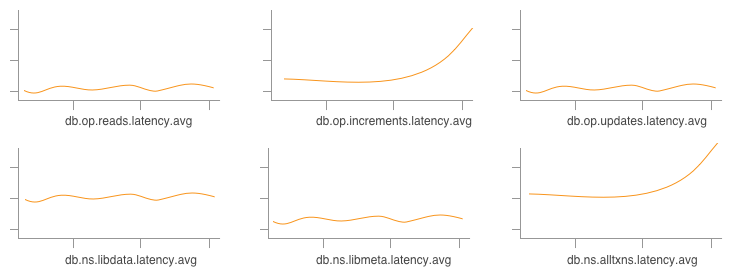
and trying to visually correlate trends (presumably increments on alltxns are correlated with an increase in latency, above), sometimes it’s just straight-up easier to look at some anomaly by saying, “Show me the events that’re causing the latency go so much higher above the average”:
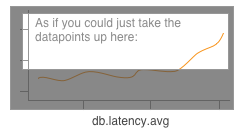
Metrics, once captured, mean that this sort of question is impossible to answer. You can’t go back and reconstruct reality from rollups; you can’t ask for just the events that caused the average latency to increase. With Honeycomb, though, you can iterate like this pretty trivially:
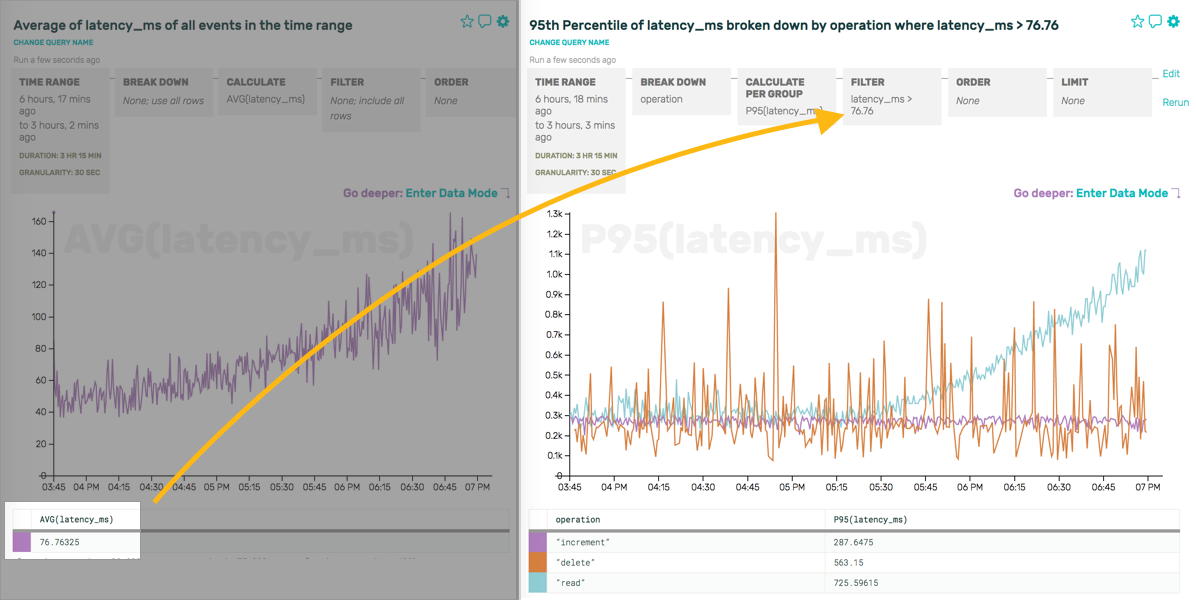
Or, if you like, now that you’ve defined a filter like latency_ms > 76.76, you can drop down and see the raw events and the relationships they contain.
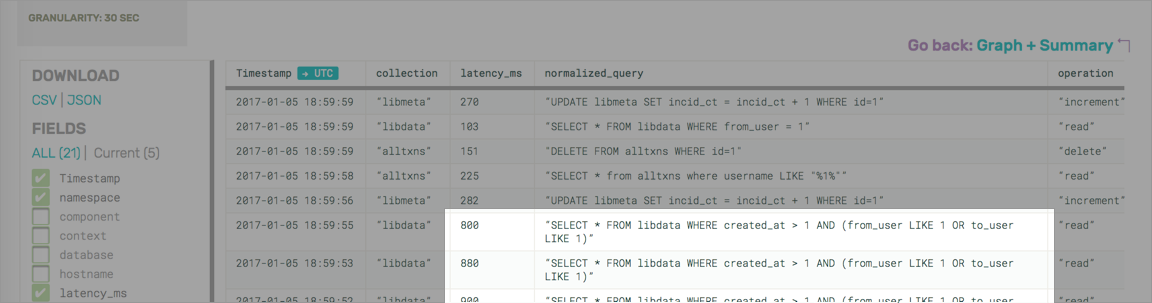
Looking at these, we now have a much better idea of patterns like “we only ever perform increments on libmeta (boring!), but alltxns receives updates, increments, and reads”—more directly and easily than staring at reality through the very small, narrow lenses of individual metrics over time.
With so many things in motion, sometimes just seeing how various attributes are related to each other is more valuable than having to infer it from graphs.
And, ultimately, because we’re visual creatures, Honeycomb makes it easy to pop back from data mode into visual mode, and ask just the right question to confirm our hunch:
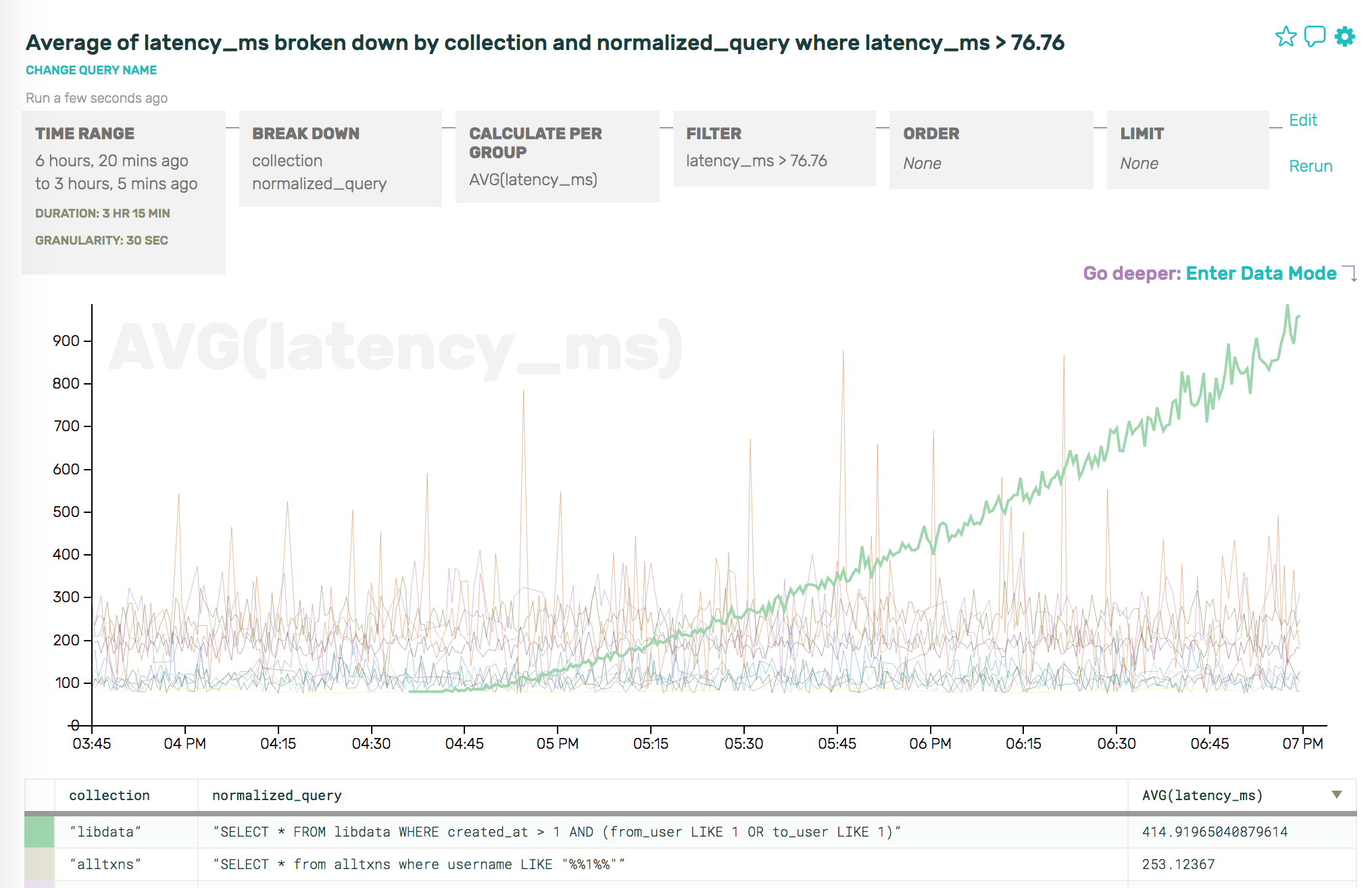
Note: it’s true, detractors will absolutely be able to construct scenarios in which the visually-correlating-trends approach is enough, but that approach relies so heavily on things going wrong in predictable ways or clues in low-cardinality fields that we remain highly skeptical.
Want more? Give us a try!
For more illustrated examples of using Honeycomb to explore database data, check out our other database posts—or just sign up and get started today!